B-Trees
B-Trees are a variation on binary search trees that allow quick
searching in files on disk. Instead of storing one key and having
two children, B-tree nodes have n keys and n+1 children,
where n can be large. This shortens the tree (in terms of
height) and requires much less disk access than a binary search tree would.
The algorithms are a bit more complicate, requiring more computation than
a binary search tree, but this extra complication is worth it because
computation is much cheaper than disk access.
Disk Access
Secondary storage usually refers to the fixed disks found
in modern computers. These devices contain several platters of magnetically
sensitive material rotating rapidly. Data is stored as changes in the
magnetic properties on different portions of the platters. Data is separated
into tracks, concentric circles on the platters. Each track is
further divided into sectors which form the unit of a transaction
between the disk and the CPU. A typical sector size is 512 bytes. The data is
read and written by arms that go over the platters, accessing different
sectors as they are requested.
The disk is spinning at a constant rate (7200 RPM is typical for
1998 mid-range systems).
The time it takes to access data on secondary storage is a function of
three variables:
- The time it takes for the arm to move to the track where the
requested sector lies. Usually around 10 milliseconds.
- The time it takes for the right sector to spin under the arm.
For a 7200 RPM drive, this is 4.1 milliseconds.
- The time it takes to read or write the data. Depending on the density
of the data, this time is negligible compared to the other two.
So an arbitrary 512-byte sector can be accessed (read or written) in roughly
15 milliseconds. Subsequent reads to an adjacent area of the disk will
be much faster, since the head is already in exactly the right place.
Data can be arranged into "blocks" that are these adjacent multi-sector
aggregates.
Contrast this to access times to RAM. From the last lecture, a typical
non-sequential RAM access took about 5 microseconds. This is 3000 times
faster; we can do at least 3000 memory accesses in the time it takes to do one
disk access, and probably more since the algorithm doing the memory accesses
is typically following the principal of locality.
So, we had better make each disk access count as much as possible. This is
what B-trees do.
For the purposes of discussion, records we might want to search through
(bank records, student records, etc.) are stored on disk along with their
keys (account number, social security number, etc.), and many are all stored
on the same disk "block." The size of a block and the amount of data can
be tuned with experimentation or analysis beyond the scope of this lecture.
In practice, sometimes only "pointers" to other disk blocks are stored
in internal nodes of a B-tree, with leaf nodes containing the real data; this
allows storing many more keys and/or having smaller (and thus faster) blocks.
B-Tree Definition
Here is a sample B-tree:
_________
|_30_|_60_|
_/ | \_
_/ | \_
_/ | \_
_/ | \_
_/ | \_
_/ | \_
_/ | \_
________ _/ ________| ____\_________
|_5_|_20_| |_40_|_50_| |_70_|_80_|_90_|
/ | \ / | \ / | | \
/ | \ / | \ / | | \
/ | | | | | | | | \
/ | | | | | | | | \
|1|3| |6|7|8| |12|16| |32|39||42|48||51|55| |61|64| |71|75||83|86| |91|95|99|
B-tree nodes have a variable number of keys and children, subject to
some constraints. In many respects, they work just like binary search
trees, but are considerably "fatter." The following definition is
from the book, with some references to the above example:
A B-tree is a tree with root root[T] with the following
properties:
- Every node has the following fields:
- n[x], the number of keys currently
in node x. For example, n[|40|50|]
in the above example B-tree is 2. n[|70|80|90|]
is 3.
- The n[x] keys themselves, stored
in nondecreasing order:
key1[x] <=
key2[x] <= ... <=
keyn[x][x]
For example, the keys in |70|80|90| are ordered.
- leaf[x], a boolean value that is True
if x is a leaf and False if x is an internal
node.
- If x is an internal node, it contains n[x]+1
pointers
c1,
c2, ... ,
cn[x],
cn[x]+1 to its children. For example,
in the above B-tree, the root node has two keys, thus three children. Leaf nodes
have no children so their ci fields are undefined.
- The keys keyi[x] separate the ranges of keys
stored in each subtree: if ki is any key stored
in the subtree with root ci[x], then
k1 <= key1[x] <=
k2 <= key2[x] <= ...
<= keyn[x][x] <=
kn[x]+1.
For example, everything in the far left subtree of the root is numbered
less than 30. Everything in the middle subtree is between 30 and 60, while
everything in the far right subtree is greater than 60. The same property
can be seen at each level for all keys in non-leaf nodes.
- Every leaf has the same depth, which is the tree's height h.
In the above example, h=2.
- There are lower and upper bounds on the number of keys a node can
contain. These bounds can be expressed in terms of a fixed integer
t >= 2 called the minimum degree of the B-tree:
- Every node other than the root must have at least t-1 keys.
Every internal node other than the root thus has at least t children.
If the tree is nonempty, the root must have at least one key.
- Every node can contain at most 2t-1 keys. Therefore, an internal
node can have at most 2t children. We say that a node is full
if it contains exactly 2t-1 keys.
Some Analysis
Theorem 19.1 in the book states that any n-key B-tree with
n > 1 of height h and minimum degree t satisfies
the following property:
h <= logt(n+1)/2
That of course gives us that the height of a B-tree is always O(log n),
but that log hides an impressive performance gain over regular binary search
trees (since performance of algorithms will be proportional to the height of
the tree in many cases).
Consider a binary search tree arranged on a disk, with pointers being the
byte offset in the file where a child occurs. A typical situation will
have maybe 50 bytes of information, 4 bytes of key, and 8 bytes (two 32-bit
integers) for left and right pointers. That makes 62 bytes that will
comfortably fit in a 512-byte sector. In fact, we can put many such nodes
in the same sector; however, when our n (= number of nodes) grows
large, it is unlikely that the same two nodes will be accessed sequentially,
so access to each node will cost roughly one disk access. In the best
possible case, the a binary tree with n nodes is of height about
floor(log2n). So searching for an
arbitrary node will take about log2n disk accesses.
In a file with one million nodes, for instance, the phone book for a
medium-sized city, this is about 20 disk accesses. Assuming the 15 millisecond
access time. a single access will take 0.3 seconds.
Contrast this with a B-tree with records that fit into one 512-byte sector.
Let t=4. Then each node can have up to 8 children, 7 keys.
With 50*7 bytes of information, 4*7 bytes of keys, 4*8 bytes of
children pointers, and 4 bytes to store n[x], we have
414 bytes of information fitting comfortably into a 512 byte sector.
With one million records, we would have to do log41,000,000
= 10 disk accesses, taking 0.15 seconds, reducing by a half the time it
takes.
If we choose to keep all the information in the leaves as suggested
above and only keep pointer and key information, we can fit up to 64
keys and let t=32. Now the number of disk accesses in our
example is less than or equal to log32 1,000,000 = 4.
In practice, up to a few thousand keys can be supported with blocks
spanning many sectors; such blocks take only a tiny bit longer to access
than a single arbitrary access, so performance is still improved.
Of course, asymptotically, the number of accesses is "the same," but
for real-world numbers, B-trees are a lot better. The key is the
fact that disk access times are much slower than memory and computation
time. If we were to implement B-trees using real memory and pointers,
there would probably be no performance improvement whatsoever because
of the algorithmic overhead; indeed, there might be a performance decrease.
Operations on B-trees
Let's look at the operations on a B-tree. We assume that the root
node is always kept in memory; it makes no sense to retrieve it from the
disk every time since we will always need it. (In fact, it might be wise
to store a "cache" of frequently used and/or low depth nodes in memory
to further reduce disk accesses...)
Searching a B-tree
Searching a B-tree is much like searching a binary search tree, only
the decision whether to go "left" or "right" is replaced by the decision
whether to go to child 1, child 2, ..., child n[x].
The following procedure, B-Tree-Search, should be called with
the root node as its first parameter. It returns the block where the
key k was found along with the index of the key in the block,
or "null" if the key was not found:
B-Tree-Search (x, k) // search starting at node x for key k
i = 1
// search for the correct child
while i <= n[x] and k > keyi[x] do
i++
end while
// now i is the least index in the key array such that
// k <= keyi[x], so k will be found here or
// in the i'th child
if i <= n[x] and k = keyi[x] then
// we found k at this node
return (x, i)
if leaf[x] then return null
// we must read the block before we can work with it
Disk-Read (ci[x])
return B-Tree-Search (ci[x], k)
The time in this algorithm is dominated by the time to do disk reads.
Clearly, we trace a path from root down possibly to a leaf, doing one
disk read each time, so the number of disk reads for B-Tree-Search
is O(h) = O(log n) where h
is the height of the B-tree and n is the number of keys.
We do a linear search for the correct key. There are
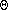 (t) keys (at least
t-1 and at most 2t-1), and this search is done
for each disk access, so the computation time is
O(t log n). Of course, this time is very
small compared to the time for disk accesses. If we have some spare time
one day, in between reading Netscape and playing DOOM, we might consider
using a binary search (remember, the keys are nondecreasing) and get this
down to O(log t log n).
(t) keys (at least
t-1 and at most 2t-1), and this search is done
for each disk access, so the computation time is
O(t log n). Of course, this time is very
small compared to the time for disk accesses. If we have some spare time
one day, in between reading Netscape and playing DOOM, we might consider
using a binary search (remember, the keys are nondecreasing) and get this
down to O(log t log n).