The next step towards optimizing the micro-kernel exploits that computing with contiguous data (accessing data with a "stride one" access pattern) improves performance. The fact that the \(m_R \times n_R \) micro-tile of \(C\) is not in contiguous memory is not particularly important. The cost of bringing it into the vector registers from some layer in the memory is mostly inconsequential because a lot of computation is performed before it is written back out. It is the repeated accessing of the elements of \(A \) and \(B \) that can benefit from stride one access.
Two successive rank-1 updates of the micro-tile can be given by
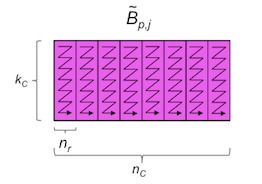
Since \(A \) and \(B \) are stored with column-major order, the four elements of \(\alpha_{[0:3],p}\) are contiguous in memory, but they are (generally) not contiguously stored with \(\alpha_{[0:3],p+1}\text{.}\) Elements \(\beta_{p,[0:3]} \) are (generally) also not contiguous. The access pattern during the computation by the micro-kernel would be much more favorable if the \(A \) involved in the micro-kernel was packed in column-major order with leading dimension \(m_R \text{:}\)
and \(B \) was packed in row-major order with leading dimension \(n_R \text{:}\)
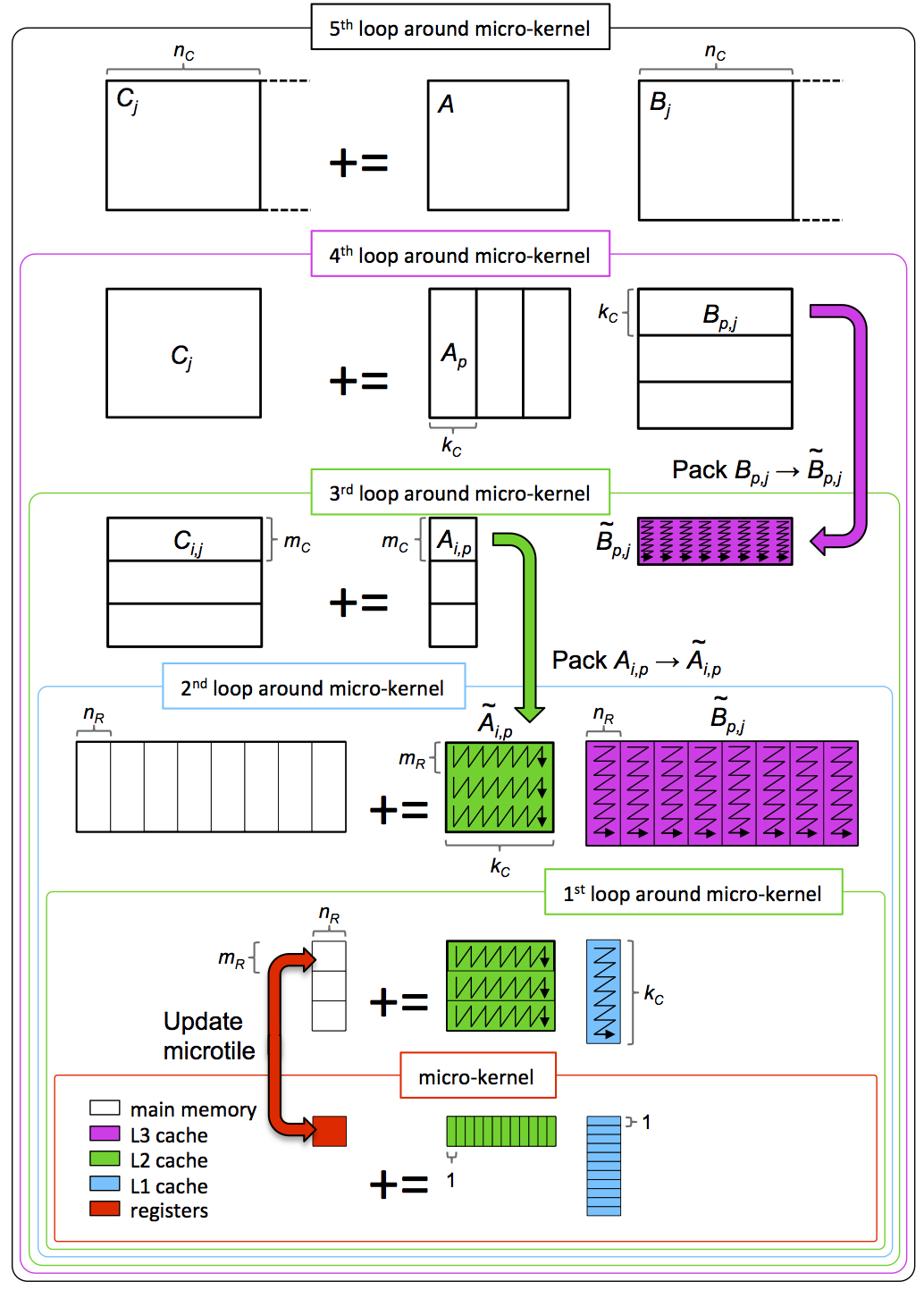
If this packing were performed at a strategic point in the computation, so that the packing is amortized over many computations, then a benefit might result. These observations are captured in Figure 3.3.1.
Figure3.3.1. Blocking for multiple levels of cache, with packing. In the next units you will discover how to implement packing and how to then integrate it into the five loops around the micro-kernel.