Intelligent, Knowledgeable Systems - Results of the Halo Pilot
A project of the
Knowledge Systems Group, UT-Austin,
as part of
Project Halo
![]()
A project of the
Knowledge Systems Group, UT-Austin,
as part of
Project Halo
![]()
Every research field should periodically take a test - to measure its progress and to set course. Our field, knowledge representation and automated reasoning, was recently put to a significant challenge: in 4 months build a knowledge base capable of doing well on an AP (Advanced Placement) Chemistry exam.
The challenge problem was posed, funded and administered by Vulcan, Inc, a Paul Allen company. (See Vulcan's website for a complete report on Project Halo.) Three research teams participated:
The goal of the challenge problem was to assess the current capabilities of knowledge systems - without further R&D, and with very little time to adjust to the rigors of a new application domain, how well could the teams do with existing technology?

Fig. 1. The UT-Austin team in the first of several celebrations, this one at Ski Shores. Clockwise from top left: Peter Yeh, Jason Chaw, Steve Wilder, Ken Barker, Dan Tecuci, Bruce Porter, and James Fan.
Vulcan selected three broad topics in Inorganic Chemistry - stoichiometry, acid-base reactions, and chemical equilibrium - covering about 70 pages in a college level textbook. Vulcan gave each team about the same level of funding and the same ambitious timeline: In four months, each team had to analyze the domain and build a knowledge system encompassing all its terms and laws.
Then came the exam. It was written by a Chemistry professor with considerable experience with AP tests - both designing questions and setting the grading policy. The exam had 169 questions. The first 50 were multiple choice and the rest were open ended. Importantly, all of the questions were novel - the teams were not privy to the exam when building their knowledge systems.
As part of the Challenge, Vulcan set the ground rule that getting the right answer was not enough - the systems had to explain their answers in detail, and in English! Explanations had to be correct, coherent, logical, and succinct to earn full points.
Expert systems of the 1970's and 80's were the first knowledge systems. Thousands were built, and some performed remarkably well. Nevertheless, modern knowledge systems are significantly more advanced in four ways.
The exams were graded by three chemists, each working independently of the others (there was no attempt to coordinate grading standards). All three concluded that our system performed the best.
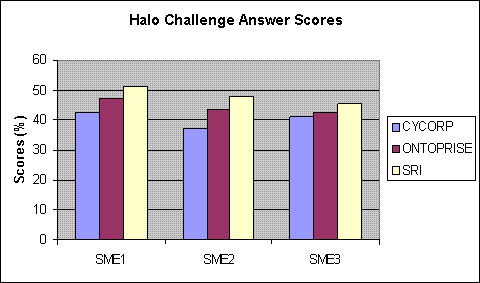
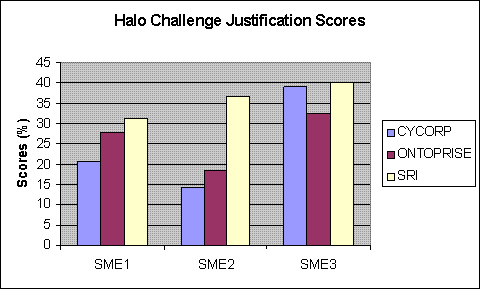
Fig. 2. The results of the evaluation in terms of the correctness of answers (top graph) and quality of explanations (bottom graph). Results are statistically significant to at least 95% confidence.
The chemists used different grading criteria (e.g. "easy grading" vs "hard grading"), but their overall rankings were the same.
To put these results in perspective, the our system performed well enough (in terms of correctness) to earn an AP score of 3, high enough for college credit at top universities, such as UIUC and UCSD.
Nevertheless, the systems would need to be improved substantially to achieve expert-level performance (which is not surprising given only four months of development!) One of the most intriguing shortcomings of the systems was their inability to reason at a meta level. This was revealed by several of the questions on the exam - ones that required the system to solve the problem and then to reflect on its reasoning.
The systems also require more sophisticated methods of explanation generation. In many cases, the chemists deducted points on explanations that were verbose or redundant. Partly this is because the experiment did not allow for interactive, drill-down explanation generation. More importantly, basic research is required on many fronts, such as explanation and dialogue planning.
Our long-term vision is that domain experts (e.g. chemists!) will build knowledge systems - with little or no help from knowledge engineers - as a way of amassing their field's knowledge. Knowledge systems would replace traditional libraries of inaccessible text, and offer extraordinary question answering ability. The main challenge is acquiring representations of knowledge that are computationally useful. Currently, most human knowledge is "locked up" in inaccessible representations - such as text and diagrams - that are largely useless for automated reasoning. (Try asking Jeeves a few simple questions, and you'll quickly see the limitations of computer processing of textual information.) So, one challenge is to develop ways to codify knowledge, and another is to recruit people to do the work!
It's encouraging to consider the parallels between progress in knowledge systems and the early successes in computer programming. During computing's early days, very few people were able to write programs because it required intricate knowledge of computer internals. With the advent of high-level languages (such as Fortran), scientists and engineers with virtually no training in computer science were writing complex programs. Once empowered, the domain experts were eager volunteers, building software infrastructure to meet the needs of their own disciplines.
We believe domain experts will be similarly motivated to codify their knowledge in computational forms (rather than inaccessible representations) if they can write in a high-level language which is then automatically compiled into axioms. The high-level language must include abstractions familiar to the domain experts, as is common in Domain Specific Languages (DSLs) for conventional programming.
Toward that end, we're building a
Component Library
of common
abstractions. It contains representations of basic concepts - actions,
entities, roles, and relationships - each richly axiomatized. We have
found that domain-specific concepts can be built up by instantiating
and assembling these basic building blocks, as Clark and Porter
described in
Building Concept Representations from Reusable
Components
Abstract
and
pdf),
which earned a Best Paper award at the National AI
Conference in 1997 and has served as blueprint for our long term
research.
![]() Created by Bruce Porter
Created by Bruce Porter
Maintained by Dan Tecuci
Last modified September 2004