
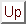

Since faces have a common general structure, it is advantageous to
align the blobs in the model domain to insure that they
are always at the same position in the faces, either all at the left
eye or all at the chin etc. This is achieved by connections between
the layers and leads to the term  instead of
instead of  in
Equation 1.
If the model blobs were to run independently, the image layer would
get input from all face parts at the same time, and the blob there
would have a hard time to align with a model blob, and it would be
very uncertain whether it would be the correct one. The cooperation
between the models and the image would depend more on accidental
alignment than on the similarity between the models and the image,
and it would then be very likely that the wrong model was picked up
as the recognition result.
One alternative is to let the models inhibit each other such that
only one model can have a blob at a time. The models then would share
time to match onto the image, and the best fitting one would get most
of the time. This would probably be the appropriate setup if the
models were very different and without a common structure, as it is
for general objects. The disadvantage is that the system needs much
more time to decide which model to accept, because the relative layer
activities in the beginning depend much more on chance than in the
other setup.
in
Equation 1.
If the model blobs were to run independently, the image layer would
get input from all face parts at the same time, and the blob there
would have a hard time to align with a model blob, and it would be
very uncertain whether it would be the correct one. The cooperation
between the models and the image would depend more on accidental
alignment than on the similarity between the models and the image,
and it would then be very likely that the wrong model was picked up
as the recognition result.
One alternative is to let the models inhibit each other such that
only one model can have a blob at a time. The models then would share
time to match onto the image, and the best fitting one would get most
of the time. This would probably be the appropriate setup if the
models were very different and without a common structure, as it is
for general objects. The disadvantage is that the system needs much
more time to decide which model to accept, because the relative layer
activities in the beginning depend much more on chance than in the
other setup.