William C. Bulko
IBM Corporation
11400 Burnett Road
Austin, Texas 78758
bulko@cs.utexas.edu
Copyright © 1993 Academic Press Limited
This article appears in Journal of Visual Languages and Computing, 4, 1993, pp. 161-175.
Diagrams are both natural and economical as a means of describing spatial objects and relationships. The use of relatively free-form diagrams as input to computer programs is potentially attractive. However, understanding diagrams involves many of the same problems as understanding natural language: diagram elements and relationships are often ambiguous, and essential properties may not be not directly indicated by a diagram. Context and world knowledge must be used to resolve ambiguities and to infer missing information.We describe a program, BEATRIX, that can understand textbook physics problems specified by a combination of English text and a diagram. The result of the understanding process is a unified internal model that represents information derived from both the text and the diagram. The process of interpreting diagram elements and relationships is described; a central problem is establishing coreference, that is, determining when parts of the text and diagram refer to the same object. Constraints supplied by the text, by the diagram, and by world knowledge are used to reduce ambiguity of diagram elements until unique interpretations are obtained. Generalizations of these techniques to other diagram understanding tasks are discussed.
Humans find diagrams to be a natural means of communicating information about shapes and spatial relationships of objects. It is difficult to describe complex spatial relationships using natural language. People frequently use diagrams to supplement natural language when spatial relationships need to be described; this is true not only in engineering and scientific domains, but also in describing football plays, choreography, or positions and movements of military units. An ability to use relatively free-form diagrams as input to computer programs would be very attractive. Diagrams are not only a natural form of communication that is frequently used by humans in communicating with each other, but also powerful and economical in the sense that a diagram conveys a great deal of information in a form that is compact and easily input [larkin-simon:diag10k]. Before diagrams can be used effectively as computer input, however, techniques must be developed to allow diagrams to be interpreted correctly.
Ambiguity in natural languages such as English is a well-known problem. Diagrams can also be highly ambiguous. For example, a line in a diagram might represent an edge of a large object (such as the surface of the earth), or a part of an object, or a shared boundary between two objects, or an object in itself (such as a cable). If a diagram is to be understood correctly, ambiguities must be eliminated, so that each diagram element is given a correct interpretation. In many cases, it will not be possible to uniquely identify a diagram element from its local characteristics, such as shape and orientation; however, constraints provided by the context may allow the ambiguity to be reduced and ultimately eliminated. When natural language text accompanies the diagram, ambiguity can be reduced by knowing that certain things are expected to be in the diagram from reading the text. As some objects are identified, the number of possible identifications of the remaining objects is reduced. Inferences based on common-sense principles of the domain, such as physical principles, can further reduce ambiguity; for example, a physical object is expected to be supported by something, and a rope under tension is expected to be attached to something. Understanding the diagram can likewise reduce ambiguity in interpretation of a natural language description.
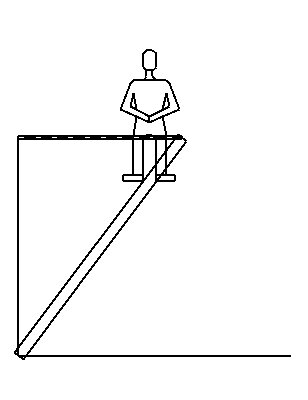
One of us has previously written a program, called ISAAC, that can understand textbook physics problems stated in English [novak:isaac,novak:ijcai77]; this program automatically generates a diagram that represents its understanding of the problem statement, as shown in Figure 1. However, it is difficult to find physics problems that involve complex geometry and are specified entirely by natural language text. Most textbook physics problems are specified by a combination of natural language text and a diagram, neither of which is a complete description by itself. In understanding such a problem, the human reader must produce a single, unified model of the problem that incorporates information from both the natural language text and the diagram; to do so, it is essential to establish coreference, that is, to determine when different forms of description refer to the same object in the situation that is being described and, therefore, in the model of the situation that is being constructed by the reader.
((the foot of a ladder rests against a
vertical wall and on a horizontal floor)
(the top of the ladder is supported from
the wall by a horizontal rope 30 ft long)
(the ladder is 50 ft long , weighs 100 lb
with its center of gravity 20 ft from the
foot , and a 150 lb man is 10 ft from the
top)
(determine the tension in the rope))
Fig. 1: Problem Diagram Generated by ISAAC
The BEATRIX system [bulko:diss,novak-bulko90] is capable of understanding a physics problem specified by a combination of English text and a diagram; it produces a unified model of the problem as output. The process of understanding text and diagram together must be opportunistic: it is important to use all the clues that are available, but it is not possible to predict which clues will be present in a particular problem, nor which order of processing will allow correct interpretations to be made. For this reason, the BEATRIX system has been implemented within a blackboard architecture, using the BB1 blackboard system [bb1] and GLISP [novak:glisp]. Examples of the kinds of problems understood by BEATRIX are shown in Figures 2 and 3. The result of the understanding process is a representation of the problem that is suitable for input to a physics problem solver such as that of Kook [kook:diss,kook-novak91].
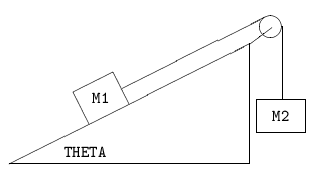
((TWO MASSES ARE CONNECTED BY A LIGHT STRING
AS SHOWN IN THE FIGURE)
(THE INCLINE AND PEG ARE SMOOTH)
(FIND THE ACCELERATION OF THE MASSES AND
THE TENSION IN THE STRING FOR
THETA = 30 DEGREES AND M1 = M2 = 5 KG))
Fig. 2: Test Problem P3 (Tipler 11)

((TWO MASSES ARE CONNECTED BY A CABLE AS
SHOWN IN THE FIGURE)
(THE STRUT IS HELD IN POSITION BY A CABLE)
(THE INCLINE IS SMOOTH , AND THE CABLE
PASSES OVER A SMOOTH PEG)
(FIND THE TENSION IN THE CABLE FOR
THETA = 30 DEGREES AND M1 = M2 = 20 KG)
(NEGLECT THE WEIGHT OF THE STRUT))
Fig. 3: Test Problem A2
In this paper, we describe the interpretation of combined text and diagram input by the BEATRIX program; we emphasize the use of constraints to eliminate ambiguity and to make correct interpretations of the diagram. The constraints are based not only on the observable features of the diagram itself, but also on expectations that are provided by the English text, by knowledge about the problem domain, and by common-sense physics. This work provides a case study that illustrates design principles that we believe will be generally useful for diagram understanding systems.
The user inputs a diagram to BEATRIX by means of an interface that is somewhat like MacPaint^TM. This interface allows the user to construct a diagram by selecting drawing components and moving, scaling, and rotating them as desired. The interface also allows the user to enter bits of text within the diagram and to enter and edit the English problem statement. The diagram is displayed in a window as it is constructed. The interface also constructs a symbolic description of the items in the diagram; this description is the input to the understanding program.
It would be much easier to understand the diagram if the input to the program were in terms of application-domain components such as blocks, ropes, and pulleys. However, we wanted the program to be able to understand diagrams found in textbooks; these diagrams are line drawings that do not explicitly identify component objects. We have been careful to ensure that the input to BEATRIX consists only of ``neutral'' components such as lines, circles, and rectangles. In the input, diagram items are represented by property-value pairs; for example,
(class LINE endpt1 (129 . 142)
endpt2 (354 . 173)
dashed T
ah1 T
ah2 NIL)
represents a dashed line with an arrowhead at its first endpoint
( ah1).
The input to BEATRIX contains only descriptions of basic geometric elements such as lines and circles. This kind of input could be derived automatically from a printed diagram by a scanner and vision preprocessor [ballard-brown]. The use of machine vision for input would be useful in understanding existing diagrams such as blueprints and circuit diagrams.
A human who is solving a physics problem will not read all of the text, and only then look at the diagram, or vice versa. Instead, the human may look briefly at the picture, then read some text, then look back at the picture, and so forth, until the problem has been understood. In a computer program for understanding physics problems, it is unlikely that any fixed order of processing would be sufficient for all problems: a problem might be specified entirely by text, or entirely by a diagram, or by some combination of text and diagram. Therefore, BEATRIX is organized using co-parsing of the two input modalities. The parsing of the English text and parsing of the diagram are done in parallel; the final interpretation of objects depends on information from both the parsed text and the parsed diagram. This control strategy allows the understanding process to be opportunistic, taking advantage of clues to understanding that arise from diverse knowledge sources. An opportunistic control strategy has been useful in other perceptual domains such as speech understanding [hearsay] and sonar signal interpretation [nii:hasp].
This section briefly introduces the concept of blackboard systems for readers who may be unfamiliar with them. Later sections describe in detail how BEATRIX is organized within the BB1 blackboard architecture.
A blackboard system [engelmore] provides an architecture for organizing a set of relatively independent programs, called knowledge sources, for cooperative and opportunistic problem solving. Each knowledge source (KS) is a program that performs a single specific task, e.g., to determine whether a circle and nearby lines represent a pulley system. KS's communicate by means of a central data structure called the blackboard. A KS is triggered (scheduled for execution) when data that matches its triggering pattern is posted on the blackboard. The blackboard may be divided into levels; each level contains data of a particular kind and represents a stage of perceptual processing.
The domain blackboard of the system is organized into five levels, as shown in Figure 4.
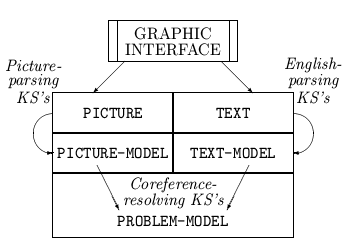
Fig. 4: Domain Blackboard Organization
The lowest levels of the blackboard are called TEXT and PICTURE. The TEXT level contains the English sentences of the problem statement; each sentence has a sequence number indicating its order of occurrence. The PICTURE level contains symbolic descriptions of the diagram elements, such as BOX, LINE, or CIRCLE. In addition, the PICTURE level contains a set of objects, created by a preprocessor program, that represent points of contact between diagram elements.
The intermediate blackboard levels, TEXT-MODEL and PICTURE-MODEL, represent hypotheses created by the parsing of the text and diagram. Objects on the PICTURE-MODEL level represent elementary physical objects, such as MASS or PULLEY, that are possibly contained in the diagram; these are recognized independently from the text, before coreference resolution is performed. TEXT-MODEL objects represent physical objects and relations that have been tentatively identified from the TEXT by the English parser.
The most abstract level of the blackboard is the PROBLEM-MODEL level. Objects at this level represent physical objects in the final interpretation of the problem. These objects have links connecting them to the corresponding objects on the TEXT-MODEL and PICTURE-MODEL levels.
BEATRIX contains 53 knowledge sources ( KS's); each KS is a specialist program for understanding a particular part of a problem description. Table 1 shows the knowledge sources used and classifies them into groups. The names of the knowledge sources indicate the tasks they perform; the table gives an indication of the granularity of knowledge sources and the number of knowledge sources needed for each kind of task. The Control KS, Define-Reliability, is used to set up code for calculating execution priorities of the other KS's. The Identify KS's operate between the PICTURE and PICTURE-MODEL levels; they perform syntactic recognition of related groups of diagram elements. The single Parse KS calls an augmented transition network (ATN) parser [woods:atn] written in Lisp to parse the sentences of the English text. Match KS's perform coreference matching, finding objects on the PICTURE-MODEL and TEXT-MODEL blackboard levels that correspond and making objects on the PROBLEM-MODEL level that encompass them. KS's whose names begin with Retrieve- move information to higher levels of the blackboard when other KS's fail to do so, e.g., when an object appears in the diagram but is not mentioned in the text. Semantic KS's modify existing objects and make inferences; for example, if the angle between a horizontal surface and another surface is known, Propagate-Angle-ROTN will cause the rotation of the other surface to correspond to that angle. Of the Special KS's, Post-the-Problem initiates blackboard action by placing the text and diagram on their respective blackboard levels; the remaining KS's perform default reasoning when more specific KS's cannot act because of insufficient input information.
| Control: | Match: |
| Define-Reliability | Match-Incline |
| Match-Mass-to-Mass | |
| Identify: | Match-Mass-to-Object |
| 1-1 Identify-Angles | Match-Normal-Arrow |
| Identify-Arrows | Match-Normal-Force |
| Identify-Line | Match-Pivot |
| Identify-Mass-Labels | Match-Pulley |
| Identify-Masses | Match-Rope |
| Identify-Pulley | Match-Struts |
| Identify-Pulley-System | Match-Surface |
| Identify-Struts | Match-Tension |
| Identify-Surfaces | Match-Tension-Arrow |
| Propagate-Touches | Match-Variable |
| Propagate-PM-Contact | |
| Parse: | Propagate-PSt-Contact |
| 1-1 Parse-the-Sentences | Propagate-RM-Contact |
| Propagate-RP-Contact | |
| Semantic: | Propagate-RS-Contact |
| 1-1 Add-Contact-Locs | Propagate-RSt-Contact |
| Add-Contact-Objects | Propagate-SM-Contact |
| Assign-Value-to-Variable | Propagate-SP-Contact |
| Correct-Floor-to-Table | Propagate-SS-Contact |
| Find-COEF | Propagate-SSt-Contact |
| Get-Mass-Value | |
| Neglect-TM-Weight | Special: |
| 2-2 Propagate-Angle-ROTN | Default-Mass-ROTNs |
| Propagate-Rope-ROTN | Default-Rope-ROTNs |
| Propagate-Touch-ROTN | Post-the-Problem |
| Translate-BE-ADJ | Retrieve-Mass |
| Translate-LET-BE | Retrieve-Pulley |
| Retrieve-Rope | |
English sentences are parsed using an augmented transition network (ATN) grammar [woods:atn]; the grammar is written in a meta-language similar to the one described by Charniak and McDermott [charniak-mcdermott]. Figure 5 shows the grammar function for a noun phrase. The grammar is simple; most semantic processing is performed by the understanding module that considers text and diagram together. The ATN parser is invoked by a single knowledge source, Parse-the-Sentences. A sentence is syntactically parsed top-down; the parser produces a parse tree and posts tokens representing the objects mentioned in the sentence on the TEXT-MODEL blackboard level. This forms the natural language input to the understanding module, which performs semantic processing of the natural language input and the diagram together.
(DEFINEQ (NP (LAMBDA ()
(CHAIN NP
(EITHER
(CAT QWORD)
(SEQ (OPTIONAL (CAT DET))
(OPTIONAL (CAT NUMBER))
(OPTIONAL* (CAT ADJ))
(OPTIONAL (MEAS))
(CAT NOUN)
(SETQ NN1 (THAT NOUN))
(OPTIONAL (AND (SETQ LABEL-ARC
(CAT NOUN))
(EQ (GETPROP
(THAT NOUN)
'TYPE))
'VARIABLE)
LABEL-ARC))
(OPTIONAL (VCLAUSE))
(OPTIONAL (PREPP NN1)))))))
Fig. 5: Noun Phrase ATN Grammar Function
The diagram is parsed by a set of knowledge sources that recognize combinations of picture elements that have special meaning. In effect, these KS's act as grammar productions of a picture grammar [ksfu74]; [hanson78] describes the use of a blackboard system for scene interpretation that uses a grammar-like representation of components of a scene. A two-dimensional diagram is inherently ambiguous because it is a projection of a (possibly imaginary) three-dimensional scene onto two dimensions; for example, a circle in a diagram might represent the end of a cylinder, or a sphere, or a hole. A diagram is a symbolic representation: a diagram may omit some objects or details, may represent some features symbolically, may exaggerate features for effect, or may include descriptive elements that are not objects ( e.g., arrows used to show dimensions of objects). Graph matching has been suggested as a means of scene understanding, but graph matching is computationally expensive and has difficulty with missing or extra diagram components. Instead, we have developed knowledge sources that opportunistically combine related elements based on expectations of typical combinations. Other knowledge sources eliminate partial interpretations that do not make sense.
Local analysis of combinations of diagram elements often allows a combination to be interpreted as a larger and meaningful grouping. For example, if two lines touch at an acute angle, and there is text between the lines and close to the vertex, and the text is a number or is a variable name that is typically used to denote an angle (such as THETA), then the two lines will be collected on the PICTURE-MODEL level as an ANGLE; the number or variable will be associated with the ANGLE as its magnitude. An arc connecting the two lines is associated with the ANGLE if it is present, but it is not required. The examples in Fig. 6 show two angles, one of which contains text that is not part of the angle grouping.
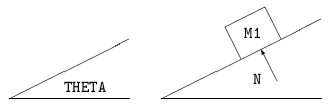
Fig. 6: THETA is part of angle, but N is not.
As parts of the diagram are interpreted, they trigger additional KS's that are associated with the interpretations. For example, after a small circle with a line to its center has been interpreted as a PULLEY, the KS Identify-Pulley-System is triggered to look for lines tangent to the pulley that represent the rope passing around the pulley. This results in the grouping of the two lines that represent the rope into a single ROPE object, with the endpoints that are distant from the pulley being identified as the ends of the rope. This, in turn, triggers additional inferences: the ends of a rope are expected to be attached to objects or surfaces. When a KS can make a clear interpretation of a part of the diagram, it obviates (removes from the execution queue) any other KS's that might have been triggered to attempt alternative interpretations.
The diagram parsing KS's not only trigger KS's to interpret related parts of the diagram, but also trigger KS's that implement expectations for later processing. For example, identification of a CONTACT between a mass and a surface triggers an expectation that a normal force and a coefficient of friction for the CONTACT may be specified in the English text. Such an expectation is necessary to correctly interpret a definite noun phrase such as ``the coefficient of friction'' if the diagram is the only place where the CONTACT is described.
The process of diagram ``parsing'' continues until no further interpretations can be made at that level; this phase interprets many features of the diagram. Figure 7 schematically illustrates the features that are identified by diagram parsing in an example problem; most of the TOUCH relations and some CONTACT relations are omitted for readability.

Fig. 7: Interpretation after Diagram Parsing
The understanding module controls the parsing of the text and the diagram, and it performs the majority of the semantic processing. Its inputs are the ``parsed'' diagram on the PICTURE-MODEL level of the blackboard and the parsed sentences on the TEXT-MODEL level; the parsed sentences are represented by case frames stored as semantic networks. The output of the understanding module is a unified model of the problem, incorporating information from both text and diagram.
A major task is to establish coreference between the text and diagram inputs in order to produce a unified model of the problem. Each object that appears in either the text or the diagram must be present on the PROBLEM-MODEL blackboard level; if features of an object appear in both text and diagram, the features must be collected on the same object in the problem model; the text and diagram are said to co-refer to this object. For example, the text might say ``the coefficient of friction is 0.25''; this might refer to a contact between a block and an inclined plane that is shown in the diagram but is not mentioned in the text. The friction value from the text must be associated at the PROBLEM-MODEL blackboard level with the contact relation between block and plane that was derived from the diagram.
The knowledge sources ( KS's) that perform coreference resolution are triggered when their corresponding types of objects are posted on the PICTURE-MODEL or TEXT-MODEL blackboard levels. For example, in the problem shown in Figure 2, parsing the phrase ``the string'' will cause an object representing a string to be added to the TEXT-MODEL level, and this will trigger the Match-Rope KS to attempt to find a corresponding object in the PICTURE-MODEL. In some cases, it is easy to establish coreference, e.g., to resolve a reference to ``the mass'' when only one object that could be a mass is present in the diagram. In other cases, however, the presence of parsed diagram elements on the PICTURE-MODEL level is necessary for finding the referent of a phrase; otherwise, the phrase would be incoherent. The text may contain a definite reference to an object (``the incline'') or to a feature of a relationship (``the coefficient of friction'') that is not otherwise mentioned in the text and could not be understood properly without the presence of the corresponding elements from the diagram. In effect, forward inferences are made to attempt to match things that might occur in the other modality; for example, in Figure 2 the contact between the mass and the inclined plane in the diagram causes the KS's Match-Normal-Force and Find-COEF to be triggered to look for corresponding references such as ``the normal force'' or ``the coefficient of friction'' that might appear in the text.
The KS's of the understanding module also perform inferences that add to the representation of the problem; in some cases these can be considered to be based on common-sense physics. For example, BEATRIX will infer that the rotation of an object is the same as the rotation of the object on which it rests, or that an object that is hanging from a rope hangs directly below it. A contact between an object and a surface is assumed to be a frictional touch contact, while a contact between a rope and an object that the rope supports is assumed to be an attachment. Such inferences are important for understanding, since both natural language text and diagrams often omit things that an intelligent reader should be able to infer.
Control of the process of understanding text and diagrams must be flexible, since no fixed order of processing is likely to succeed for a wide variety of problems. Some problems contain all of the necessary information in the text; for example, the ISAAC program [novak:isaac] handled problems whose English descriptions were sufficiently complete by themselves (although diagrams were often given for these problems in textbooks). Other problem descriptions rely heavily on a diagram; for example, in one example handled by BEATRIX the entire text is: WHAT IS THE TENSION IN THE CORD IN THE FIGURE .
Control must be opportunistic, so that clear identifications can be made first; as some identifications are made, others that were ambiguous may be resolved uniquely. Expectations must be posted so that they can be matched with corresponding references that will appear later. Defaults need to be performed when no other knowledge source can operate.
A blackboard architecture provides a scheduling mechanism that allows many knowledge sources to be triggered, or scheduled for execution; the same KS can be triggered multiple times for different data. In the BB1 blackboard system [bb1], a dynamically calculated priority is associated with each triggered KS; the KS with the highest priority is executed first. If a KS makes a clear identification, it can obviate (remove from the schedule) any remaining KS's for the same task. These methods are used to achieve opportunistic control. Bulko [bulko:diss] describes the processing of an example problem in step-by-step detail; the following items summarize the control strategies that are used:
Our experience with the BEATRIX program has led to several general conclusions about diagram understanding.
The common saying ``a picture is worth 10,000 words'' [larkin-simon:diag10k] is true in the sense that a diagram represents, using only a few diagram elements, much more information than is shown explicitly. For example, the fact that a line represents a rope often is not shown, but may be inferred from its context and from other information such as the mention of a rope in the English problem statement. Perpendicular contact between a line representing a rope and another line representing an edge of an object should be inferred to be an attachment between the rope and the object; however, other kinds of contact do not represent attachment. Thus, understanding a diagram is not a passive process of absorbing what is plainly in the diagram, but is an active process of model construction and inference, using the diagram as an outline of the model to be constructed. The ISAAC program [novak:isaac,novak:ijcai77] demonstrated a similar finding with English text: the internal model generated from understanding a problem statement was some 30 times as large as the English text. Thus, both natural language and diagrams can be seen as communication media that directly represent only the outline of a message; many details must be filled in appropriately by an intelligent reader. Brevity gives diagrams much of their power, but it also presents a challenge for diagram understanding by computer. If a large part of the understanding of a diagram must be inferred from the reader's knowledge, then that knowledge and the procedures to use it must be part of any successful diagram understanding program. Ambiguity is ever-present in diagrams: a given diagram element could potentially be interpreted in many different ways. It must be possible to resolve the ambiguities and to produce the most likely interpretation of the diagram.
Parsing of English sentences can be done in left-to-right order by a simple parsing algorithm, since English has a fairly strong sequential ordering of words and phrases. Diagrams, however, are two-dimensional, and they do not have clear rules of grammaticality. Therefore, a blackboard system appears to us to be a good method for control of a diagram-understanding program. The blackboard architecture allows opportunistic processing; for example, identification of a pulley in the diagram can trigger specialist programs to look for the ropes that typically pass around a pulley. The use of such opportunistic programs is important because a clear identification of one part of the diagram can allow many related elements to be identified unambiguously because of their relationships with that part. Opportunistic identification can be based not only on syntactic relationships ( e.g., two lines that form an acute angle with an arc and variable name between them), but also on semantic relationships governed by world knowledge or common-sense physics ( e.g., identification of a square as a mass implies that the line below the square must represent a surface).
Although reasoning about relations between diagram elements can reduce ambiguity, it cannot always remove ambiguity entirely. Some blackboard systems use numerical certainty factors to represent the estimated certainty of identifications; these systems allow multiple possible identifications to coexist on the blackboard. Later semantic processing can sometimes choose the better identifications based on how well they fit into a global interpretation. Although BEATRIX does not use such certainty factors, it seems clear that they would be useful in a larger diagram understanding system. For example, the association of a variable name with an ANGLE object could be given a higher score if the variable name is a name typically used for angles, such as THETA.
Several different classes of knowledge sources for diagram understanding are identified below. Some of these should be useful for many kinds of diagrams, while others will be specific to diagrams of a particular kind.
We have described a particular program that understands diagrams in the domain of textbook physics problems. We described the problems of ambiguity and missing details that are found in this domain and, we presume, are found in understanding other kinds of diagrams. The blackboard architecture was discussed as a method of organizing diagram-understanding knowledge so that the knowledge can be used opportunistically. Some of the features of the BEATRIX program are specific to the domain of physics problems; however, we expect that many of the techniques used by BEATRIX will be applicable in understanding other kinds of diagrams. We hope that our experience with the BEATRIX program will prove helpful to others who implement diagram understanding programs. In the paragraphs below, we suggest future research and applications of diagram understanding.
Graphical interfaces are convenient for humans. Most existing graphical interfaces are special-purpose: the graphical elements that are used, and the ways in which these elements can be connected and combined, are specialized to the application. An ability to understand diagrams that are input by the user as free-form drawings would allow the same interface to be used for multiple applications; special-purpose knowledge sources would be needed for particular application areas.
Diagrams can describe a geometric layout with only a minimal outline of the objects involved; this makes them especially useful for human input. It is very burdensome and time-consuming to specify every detail of a geometric model with high precision. A diagram understanding system that can use knowledge to understand a minimally specified diagram and to fill in details correctly can be a much better user interface.
Diagram understanding might be used for existing drawings (such as blueprints or circuit diagrams) by using an optical scanner and computer vision pre-processing program to provide the input data. Diagram understanding could also be used for conversion of CAD drawings for use with a different program than the one that made the drawings.
Drawings alone are not sufficient for complete specification; in many cases, diagrams and blueprints contain blocks of text as well as drawings. The ability to read blocks of text and to understand the text and drawings together would be needed for many applications.
[ballard-brown] Ballard, D. H. and Brown, C. M., Computer Vision, Prentice-Hall, 1982.
[bulko:diss] Bulko, W., Understanding Coreference in a System for Solving Physics Word Problems, Ph.D. dissertation, Tech. Report AI-89-102, A.I. Lab, CS Dept., Univ. of Texas at Austin, 1989.
[bb1] Hayes-Roth, Barbara and Hewett, M., ``BB1: An Implementation of the Blackboard Control Architecture'', in [engelmore], pp. 297-313.
[charniak-mcdermott] Charniak, E. and McDermott, D. V., Introduction to Artificial Intelligence, Addison-Wesley, 1985.
[engelmore] Engelmore, R. and Morgan, T., eds., Blackboard Systems, Addison-Wesley, 1988.
[hearsay] Erman, L. D., et al., ``The Hearsay-II Speech-Understanding System: Integrating Knowledge to Resolve Uncertainty'', ACM Computing Surveys, vol 12, no. 2 (June 1980), pp. 213-253.
[ksfu74] Fu, K. S., Syntactic Methods in Pattern Recognition, Academic Press, 1974.
[hanson78] Hanson, A. R. and Riseman, E. M., ``Visions: A Computer System for Interpreting Scenes'', in Hanson and Riseman (eds.), Computer Vision Systems, Academic Press, 1978.
[kook:diss] Kook, Hyung Joon, A Model-Based Representational Framework for Expert Physics Problem Solving, Ph.D. dissertation, Tech. Report AI-89-103, A.I. Lab, C.S. Dept., Univ. of Texas at Austin, 1989.
[kook-novak91] Kook, Hyung Joon and Novak, G., ``Representation of Models for Expert Problem Solving in Physics, IEEE Trans. on Knowledge and Data Engineering, 3:1, pp. 48-54, March 1991.
[larkin-simon:diag10k] Larkin, J. and Simon, H. A., ``Why a Diagram is (Sometimes) Worth 10,000 Words'', Cognitive Science, 11:65-99, 1987; also in [simon:mot2].
[nii:hasp] Nii, H. P. et al., ``Signal-to-symbol Transformation: HASP/SIAP Case Study'', A.I. Magazine, vol. 3, no. 2 (Spring 1982), pp. 23-35.
[novak:glisp] Novak, G., ``GLISP: A LISP-Based Programming System With Data Abstraction'', A.I. Magazine, vol. 4, no. 3 (Fall 1983), pp. 37-47.
[novak:isaac] Novak, G., ``Computer Understanding of Physics Problems Stated in Natural Language'', American Journal of Computational Linguistics, Microfiche 53, 1976.
[novak:ijcai77] Novak, G., ``Representations of Knowledge in a Program for Solving Physics Problems'', Proc. 5th International Joint Conf. on Artificial Intelligence (IJCAI-77), 1977, pp. 286-291.
[novak-bulko90] Novak, G. and Bulko, W., ``Understanding Natural Language with Diagrams'', Proc. Eighth National Conference on Artificial Intelligence (AAAI-90), 1990, pp. 465-470.
[simon:mot2] Simon, H. A., Models of Thought, vol. 2, Yale Univ. Press, 1989.
[woods:atn] Woods, W. A., ``Transition Network Grammars for Natural Language Analysis'', Communications of the ACM, vol. 13, no. 10 (Oct. 1970), pp. 591-606.