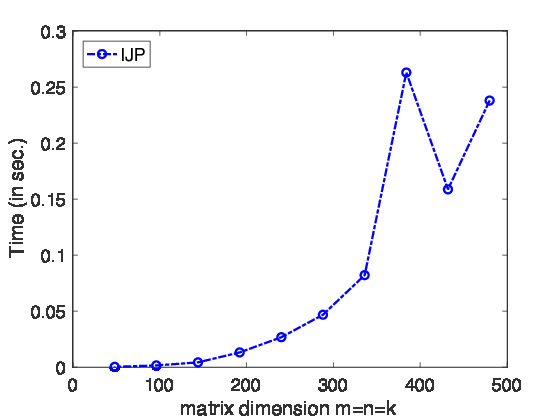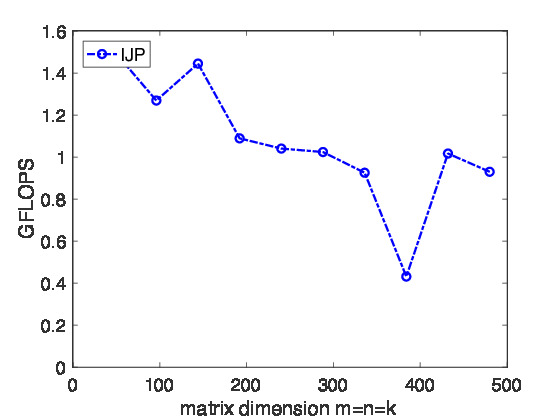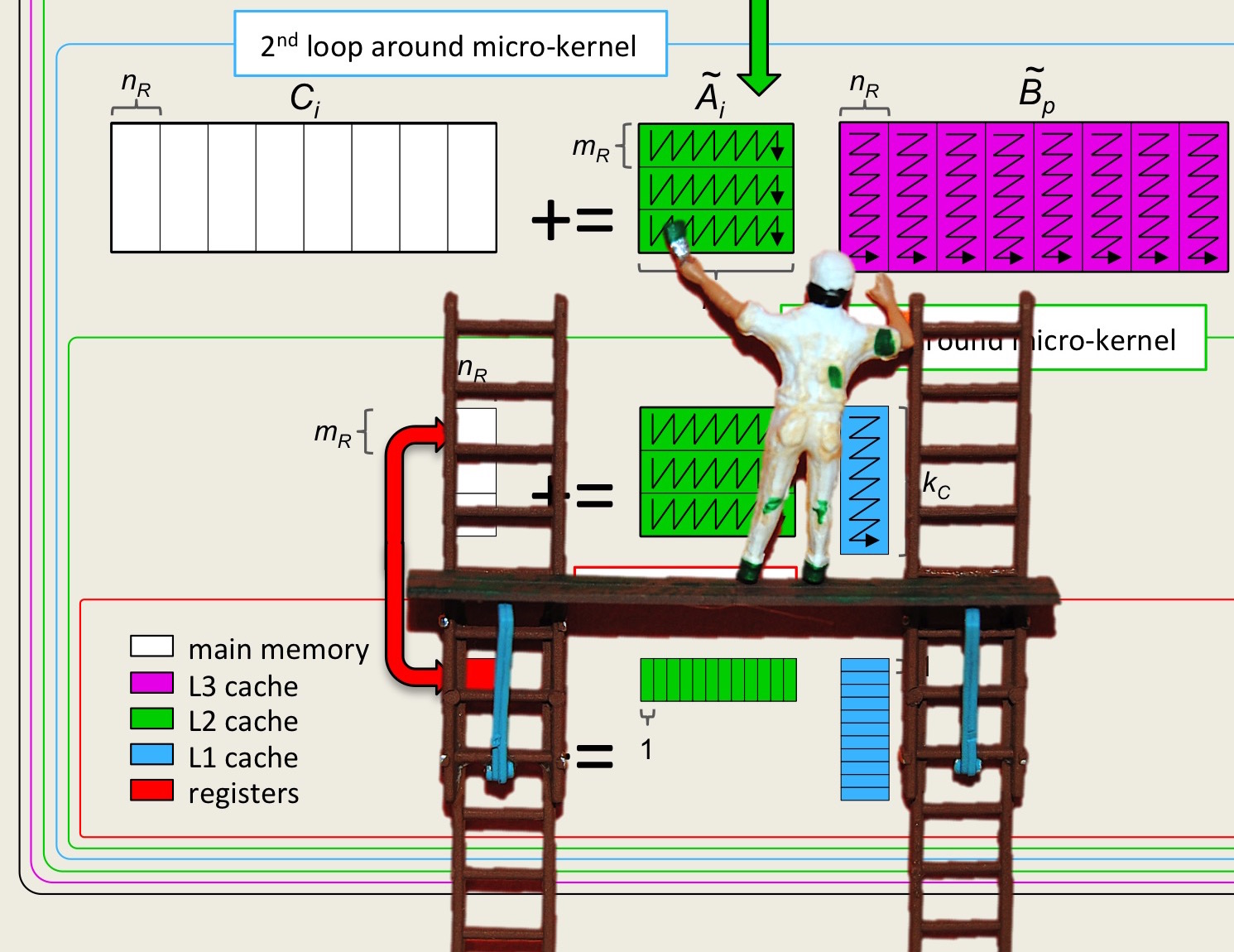
Homework 1.1.1
Compute \(\left(\begin{array}{rrr} 1 \amp -2 \amp 2\\ -1 \amp 1 \amp 3\\ -2 \amp 2 \amp -1 \end{array}\right) \left(\begin{array}{rr} -2 \amp 1\\ 1 \amp 3\\ -1 \amp 2 \end{array}\right) + \left(\begin{array}{rr} 1 \amp 0\\ -1 \amp 2\\ -2 \amp 1 \end{array}\right) = \)
Answer
\(\left(\begin{array}{rrr} 1 \amp -2 \amp 2\\ -1 \amp 1 \amp 3\\ -2 \amp 2 \amp -1 \end{array}\right) \left(\begin{array}{rr} -2 \amp 1\\ 1 \amp 3\\ -1 \amp 2 \end{array}\right) + \left(\begin{array}{rr} 1 \amp 0\\ -1 \amp 2\\ -2 \amp 1 \end{array}\right) = \left(\begin{array}{cc} -5 \amp -1\\ -1 \amp 10\\ 5 \amp 3 \end{array}\right)\)