(For a more recent code repository that implements this task, see https://github.com/aijunbai/keepaway)
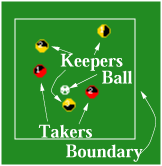
Keepaway is a subtask of robot soccer in which one team, the keepers, tries to maintain possession of a ball within a limited region, while another team, the takers, tries to gain possession. Whenever the takers take possession or the ball leaves the region, the episode ends and the players are reset for another episode (with the keepers being given possession of the ball again). The domain is implemented within the RoboCup soccer simulator. Parameters of the task include the size of the region, the number of keepers, and the number of takers.
Keepaway is a challenging machine learning task for several reasons:
Despite these challenges, we have enabled keepers to learn to match or out-perform several benchmark policies. They do using reinforcement learning methods in just a few thousand training episodes.This page shows flash files of the benchmark and learned policies. Full details of our approach along with extensive empirical results are available in the following article.
Keepaway player framework source codeThe Keepaway player framework is an implementation of all the low- and mid-level keepaway behaviors described in the publications above. The intended purpose of this code is to allow other researchers to compare different machine learning techniques on a common benchmark platform. More details about the framework, along with current benchmark results, can be found in the following paper:
News:
This code is provided "as is" as a resource to the community. All implied or expressed warranties are disclaimed. However, we welcome feedback regarding if and how you were able to use it. Also, we are interested in hearing your ideas about how it can be improved. Original Keepaway Players: This is the official release of the code maintained by the group at UT Austin. It was used to generate the benchmarks on this site. As of Fall 2010, this code works with a fresh install of version 11 of the RoboCup soccer server.
New Keepaway Players: This branch to our code is maintained by Tom Palmer in order to support modern compilers and more recent releases of the soccer server. UT Austin is not involved in its maintenance, but endorses the project as a valuable resource to the community. Please see the README file in the repo for more details: Learning Code: In response to significant interest, we have released a snapshot of the Sarsa learning code. Please keep in mind that this particular instantiation may not line up with all of the published papers using keepaway.
RCSSJava Library: This library contains java code that may be helpful in the creation of a coach or a trainer. Two applications are included: a trainer and and log player.
Mailing list: A mailing list for the keepaway framework has been created: keepaway@utlists.utexas.eduWe will periodically make announcements to the list regarding new versions of the code or changes to the web site. Also, we encourage you to use this list to ask questions, make suggestions, or announce your own projects related to the framework. To subscribe to the list, visit the following page: https://utlists.utexas.edu/sympa/subscribe/keepaway You should receive a welcome message with instructions on how to post, unsubscribe, etc. Tutorials: Basic Tutorial - This tutorial page explains step-by-step how to install the players, run a simulation, and generate a graph of the learning curve. Learning Agent Tutorial - This tutorial page explains how to modify the players to include your own learning code. Benchmarks:
The above table shows the average episode durations along with their standard deviations for each of the fixed policies included with the framework. The hand-coded policy included with the framework is the "tuned" one presented in our Adaptive Behavior article, not the simpler one described in our RoboCup05 paper. However, because the results in the AB article were obtained using a different player framework, the results are not directly comparable. The results posted here are the ones that you should expect to see when running the latest version of the Keepaway benchmark players. Initial ResultsHere we show files from the experiments reported in the ICML 2001 paper. To play the files, your browser must have the Macromedia Flash plugin.First we show the 3 vs. 2 policies with no hidden state and no sensory noise. In all cases, the two takers use a fixed go-to-ball policy: they both always go to the ball. The only difference between the keepers' behaviors is what they do when they have possession of the ball. At other times, they use a hand-coded policy specifying to where they should move. HAND-CODED (Flash, JavaScript, mp4): Here, the keepers use a reasonable hand-coded policy by which they pass the ball to the most open teammate whenever an opponent is within 10 m. This policy allows them to keep the ball for 8.2 seconds. The hand-coded policy used here is better than the one used in the ICML 2001 paper. It is the untuned hand-coded policy from the Springer Verlag 2004 paper. ALWAYS HOLD (Flash, JavaScript, mp4): Here, they never pass. Note that even with this policy, the takers have some trouble stealing the ball. In particular, one keeper can keep the ball from one taker indefinitely. Thus it is necessary for both takers to go to the ball. Here, the episodes last 4.8 seconds on average. RANDOM (Flash, JavaScript, mp4): Here, the keepers act randomly when they have the ball. That is, they choose randomly whether to hold the ball or to pass, and if passing to whom. Here the keepers hold the ball for an average of 5.5 seconds. This is the policy the keepers use at the beginning of each learning run. LEARNED (Flash, JavaScript, mp4): This file shows a typical result of the learning process. Here the keepers hold the ball for about 12 seconds on average.
| ||||||
|
Adding Hidden State and NoiseIn the Springer Verlag 2004 paper we extend these results in various ways, including adding in hidden state and perceptual noise. We also use a much stronger hand-coded policy for comparison.HAND-CODED (TUNED) (Flash, mp4): In this file, the keepers use the hand-coded policy described in the previous section, but with hand-tuned parameters. Using this policy, they are able to maintain possession for 9.6 seconds. Note that due to the increased noise, the players miss passes more frequently than in the files above. As a result, episode durations are lower on average than in the noise-free scenario. LEARNED (Flash, mp4): Here, the learning does at least as well as the new hand-coded policy, keeping the ball an average of 10.4 seconds.
| ||||||
|
Scaling UpHere we show the results of scaling up to larger teams on a larger field.RANDOM 4 vs. 3 (Flash, JavaScript, mp4): In this file, 4 keepers play against 3 takers on a 25m x 25m (56% larger) field. While the two closest takers still go straight for the ball, the additional taker tries to block passing lanes using a hand-coded algorithm. Here, the keepers are able to keep the ball for 6.3 seconds. LEARNED 4 vs. 3 (Flash, JavaScript, mp4): As in the 3v2 case, learning is able to outperform all benchmark policies. The keepers maintain possession for about 10.2 seconds. LEARNED 5 vs. 4 (Flash, mp4): With 5 keepers and 4 takers, the keepers are able to keep the ball an average of 12.3 seconds, which is about 4 seconds better than Random.
|