
I'm a final-year Ph.D student in the Computer Science Department at The University of Texas at Austin, fortunately working with Prof. Qixing Huang. My primary research interest lies in large vision language models, large-scale 3D pre-training, 3D unsupervised/self-supervised learning, and point cloud processing.
Before that, I received my B.S. degree from the Department of Computer Science at Peking University in 2019 with First Class Honors.
I'm looking for jobs starting from summer 2024. If you are interested, please drop me an email!
News
- [2024/01] Both "MaskFeat3D" and "MVNet" are accepted at ICLR 2024!
- [2023/10] I started my internship at NVIDIA Autonomous Vehicle Research Group at Santa Clara, CA.
Work Experience


Publications

We aim to improve the visual grounding capability of Large Vision Language Models (LVLMs) by using fine-grained reward modeling.
[paper]

We introduce a new method for pre-training 3D point clouds by leveraging pre-trained large-scale 2D networks. Additionally, a multi-view consistency loss ensures the 2D projections maintain 3D information by capturing pixel-wise correspondences across views.
[paper]

We introduce a novel method for 3D self-supervised pretraining of point clouds using Masked Autoencoders (MAEs). Diverging from traditional 3D MAEs that focus on reconstructing point positions, our proposed approach employs an attention-based decoder, independent of the encoder design, to recover high-order geometric features of the underlying 3D shape.
[paper]
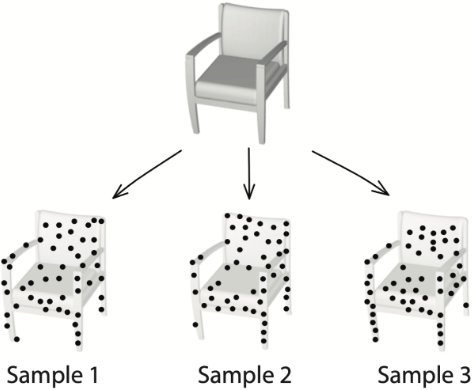
We introduce a novel method for 3D self-supervised pretraining of point clouds using Masked Autoencoders (MAEs). Diverging from traditional 3D MAEs that focus on reconstructing point positions, our proposed approach employs an attention-based decoder, independent of the encoder design, to recover high-order geometric features of the underlying 3D shape.

We introduce a new deep-learning model for segmenting 3D shapes represented as point clouds into primitive patches. It stands out by using hybrid feature representations, combining a learned semantic descriptor, two spectral descriptors based on geometric parameters, and an adjacency matrix highlighting sharp edges.

We present a novel approach for estimating relative poses in RGB-D scans, especially effective for small or non-overlapping scans. The method involves scene completion followed by matching completed scans. We use hybrid representations combining 360-degree images, 2D image-based layouts, and planar patches, allowing for adaptable feature representations for relative pose estimation.
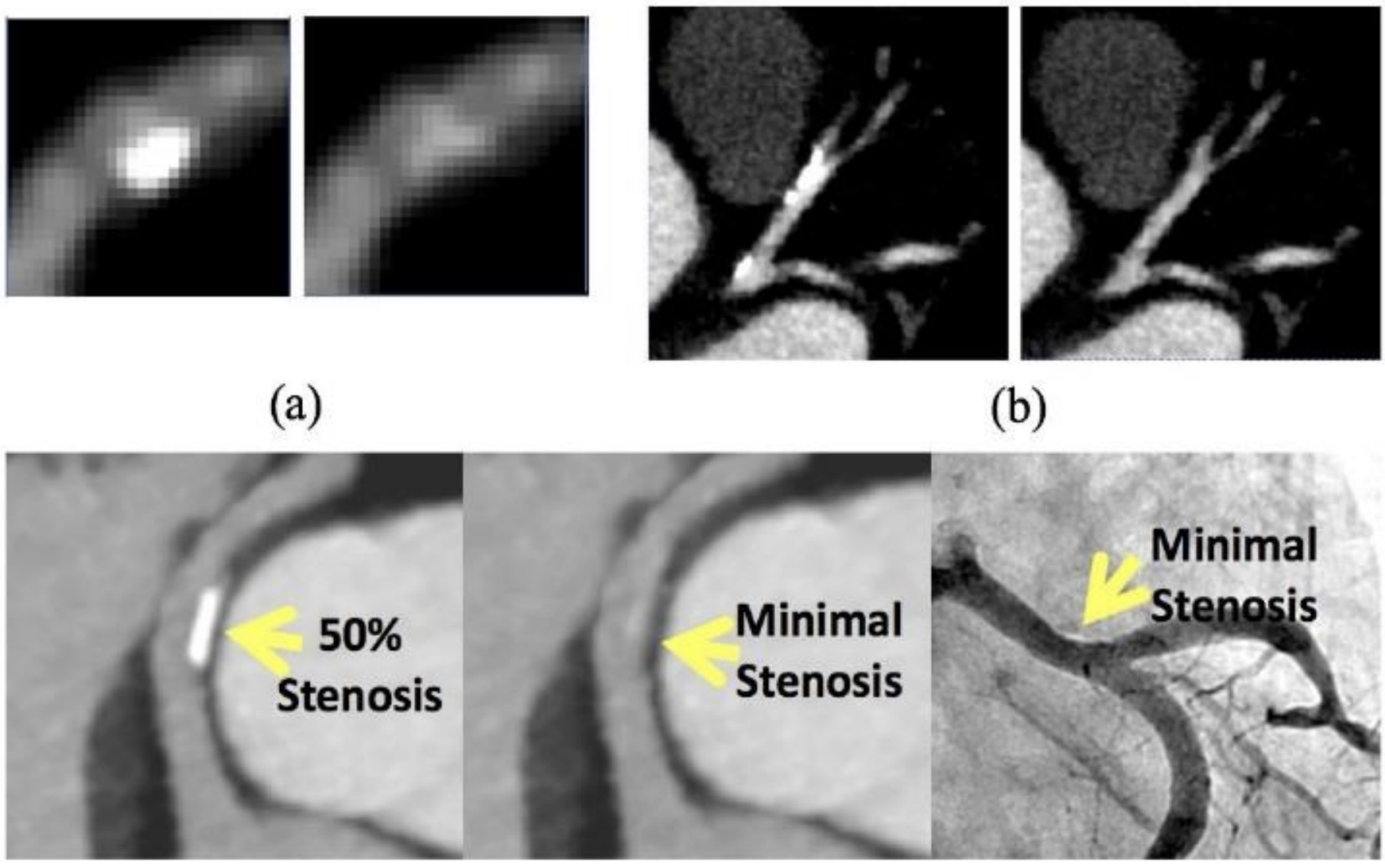
We introduce a deep learning-based method featuring a multi-step inpainting process to address the issue of coronary calcium causing beam hardening and blooming artifacts in cardiac computed tomography angiography (CTA) images.
[paper]

Recent advancements in unsupervised learning have significantly narrowed the gap in modeling the development of the primate ventral visual stream using deep neural networks. These networks, previously limited due to their reliance on extensive supervised training, which is implausible for mimicking infant development, now show promising results with unsupervised methods.
A short version is presented at Conference on Cognitive Computational Neuroscience (CCN), 2019.
We present a novel approach for generating 3D scenes using deep neural networks. It utilizes parametric prior distributions learned from training data to regularize neural model outputs and predict an over-complete set of attributes. This allows for the application of consistency constraints to eliminate infeasible predictions.

Introducing feedback loops and horizontal recurrent connections to a deep convolutional neural network enhances its robustness against noise and occlusion, suggesting these modifications improve feedforward representations by injecting top-down semantic meaning.
[paper]
Teaching

TA with Etienne Vouga.
TA with Qiang Liu and Adam Klivans.