Fast Searching with Hash Tables
This is a summary of the material presented in the lab last time.
A searching algorithm looking for a key k in a set of keys
S typically must wade through many keys in S before
finding k. We can quantify this behavior in terms of the number
of comparisons of keys in S with k.
With linear searching in e.g. linked lists and unordered
arrays, the number of comparisons is 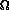 (n), where
n = |S|. With binary search in e.g. binary
trees and ordered arrays, this can be improved to (log n)
comparisons. B-Trees allow us to lessen the impact of disk input/output
on searching, but the (log n)
lower bound on the number of comparisons remains.
(n), where
n = |S|. With binary search in e.g. binary
trees and ordered arrays, this can be improved to (log n)
comparisons. B-Trees allow us to lessen the impact of disk input/output
on searching, but the (log n)
lower bound on the number of comparisons remains.
Hashing is a technique that allows essentially O(1)
comparisons to bring us to the right key in the set. We keep the keys
in an array called a hash table. When we want to find the location (index) of
a certain key k, we call a function called a hash function
that computes some function of k telling us magically where k
should be in the array. Then we go to the array and look for k
in that immediate area, taking only (if we arrange everything right)
O(1) work.
In a hash table with N array elements, the function must return
a valid array index between (in C) 0 and N-1. Ideally, the
hash function will tell us exactly where the key is located in the
array. In reality, more than one key may hash to the same
location (i.e., have the same hash function value). When two keys have
the same hash value, this is called a collision. Much of
hash tables is deciding what to do in case of a collision.
Collision Policies
A collision occurs when two keys k1 and k2
hash to the same array index i.
There are two main techniques used to resolve collisions encountered
in a hash table:
- Probing. k1 is placed in the ith
entry in the table. When k2 comes along, the algorithm
sees that entry i is already taken, so it probes the
array starting at i in a deterministic (i.e., reproducible) manner
until an available slot is found. A common probing technique (linear
probing) is to simply
try index i+1, i+2, etc. until an empty slot is found.
Variations on this are to try i+p, i+2p,
i+3p, etc., where p is relatively prime to
N; this is supposed to reduce clustering, or unwanted
bunching up of keys in the same area of the table.
- Chaining. The hash table is an array of linked lists.
k1 and k2
become members of the ith linked list in the array.
Each of these linked lists is called a bucket. Imagine chaining
like a post office box system. If you had to sort through everyones'
mail to find your own, it would take you a very long time. But with
everyone's mail neatly sorted into little boxes (buckets), it takes you
no time at all to grab all of your mail. Linked lists are not supposed
to be efficient, but a well designed hash table should have very
few elements per list. If you like, you can use binary search trees
or some other more efficient data structure for the buckets, but in practice
linked lists work fine.
Properties of a Well Designed Hash Table
A good hash table should have the following properties:
- It should have at least as many empty slots as full slots. We insure
this by knowing how many data we are expecting to store and adjust N
accordingly.
- It should have a hash function that provides uniform distribution
of hash values for the type of keys expected.
By counterexample, a poorly designed hash table for storing words
from a dictionary would use a hash function assigning index 0..25
for words beginning with a..z, respectively. This is poor because
we will probably have many more words than letters (thus large
buckets or an overflowing probing table) and some letters
will occur more frequently than others (leading to efficient searching
for 'xylophone', perhaps, but not for 'echidna').
Let's look at an example of hashing with probing. Suppose we have
student records like this:
typedef struct _rec {
int id; /* student ID */
char name[100]; /* student name */
float gpa; /* student gpa */
} rec;
We are expecting to have maybe 10,000 students, so we'll have our hash
table accomodate 30,000 records:
#define N 30000
rec table[N];
A reasonable hash function is the last four digits of the student ID.
However, this gives us a number in the range 0..9999, wasting two thirds
of the table and inviting collisions. So we'll use the student ID
modulo N:
int hash (int id) {
return id % N;
}
We first initialize the table so that each id field has
an impossible value meaning "this slot is available.":
void init_table (void) {
int i;
for (i=0; i<N; i++)
table[i].id = -1;
}
Here is the function for inserting with probing:
void insert (rec r) {
int h;
/* find hash value */
h = hash (r.id);
/* look for an available slot */
while (table[i].id != -1) {
i++;
/* wrap around so we don't go off array */
if (i == N) i = 0;
}
table[i] = rec;
}
And here is the function for searching by student ID, returning a pointer to the
record found, or NULL if the record isn't in the array:
rec *search (int id) {
int h;
/* just like inserting... */
h = hash (id);
/* ...except we're looking for the id, not -1 */
while (table[i].id != id) {
i++;
if (i == N) i = 0;
/* not there? */
if (table[i].id == -1) return NULL;
}
return &table[i];
}