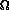 (n) comparisons.
(n) comparisons.
There are many different sorting algorithms. Sorting has been one of the most heavily researched areas of computer science. We will see just a few sorting algorithms.
In most of the discussion, we will assume we want to sort an array of n floats in ascending numerical order. We could just as easily sort them in descending order, or sort integers, or sort records by some key, or sort disk nodes, but floats will keep things simple.
/* function to swap two elements in an array */
void swap (float v[], int i, int j) {
float t;
t = v[i];
v[i] = v[j];
v[j] = t;
}
/* bubble sort function, sorts elements v[0..n-1] */
void bubble_sort (float v[], int n) {
int i, /* array index */
swapped; /* true if we have swapped */
do {
/* we have not swapped yet */
swapped = 0;
/* go through array, looking for out of order elements */
for (i=1; i<n; i++)
/* if v[i-1] and v[i] are out of order... */
if (v[i-1] > v[i]) {
/* swap them */
swap (v, i, i-1);
/* and remember to go through the loop again */
swapped = 1;
}
} while (swapped);
}
Bubble sort is so named because the "lighter" (i.e., smaller) elements
"bubble" to the top (i.e., lower indices) of the array, while the
"heavier" elements sink to the bottom. An interesting experiment
is to code up bubble sort to display the contents of the array each
time through the while loop and watch the lighter elements bubble
to the top.
Let's analyze this algorithm. For comparison sorts, where the algorithm does things based on comparisons of array elements, time is usually measured in terms of how many comparisons are done. There are three cases:
(n) comparisons.
/* insert k into sorted array v[0..n-1], moving everything into v[0..n] */
void insert (float v[], int n, float k) {
int i;
for (i=n-1; (k < v[i]) && (i >= 0); i--) v[i+1] = v[i];
v[++i] = k;
}
void insertion_sort (float v[], int n) {
int i;
for (i=0; i<n; i++) insert (v, i, v[i]);
}
The worst and best case analysis is the same, and will be done in class.
The result is that insertion sort, like bubble sort and selection sort,
takes O(n2) comparisons.
If we ignore the procedural aspects of an algorithm and look only at the data being sorted, we see that each comparison results in at most one change in the order of the array, e.g., maybe two elements may be swapped, or maybe nothing will happen at any one step.
Without loss of generality, let's assume that each array element is different. This makes the analysis easier and is often not too far an assumption from the truth.
We can think of this process as search through a binary search tree where each node is a permutation (a particular order) of the array. The root of this tree is the order of the array as the algorithm initially encounters it.
What we're searching for is the node where the permutation of elements is sorted. The right and left children of a node are the two resulting permutations when the comparison is "less than" and "greater than," respectively. It is up to the algorithm which two elements to compare. For example, the following decision tree shows the movement of data in the bubble sort algorithm performed on three items (the tree is not complete; it is large):
{ a b c }
/ \
/ \
/ \
a < b / \ a > b
/ \
{ a b c } { b a c }
b < c / \ b > c a < c / \ a > c
/ \ / \
{ a b c } { a c b } { b a c } { b c a }
/ \ / \ / \
A general purpose sort is a sorting algorithm that works on
any kind of ordered data. You provide the algorithm with an ordering
on the data, and the algorithm sorts them for you.
You provide the comparison sort with a way to compare two items of data and the algorithms sorts them for you. The standard C function qsort is a good example of a general sort:
#include <stdlib.h>
void qsort(void *base, size_t nel, size_t width,
int (*compar) (const void *, const void *));
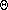 (ln m).
(ln m).
How many nodes are there in the decision tree for an array of size n?
Since there is a node for every permutation of the array, there are
n! nodes (i.e., n-factorial, n *
(n-1) * (n-2) * (n-3) * ... * 1 nodes). So
the height of the decision tree is
(ln (n!)).
A lower bound on the factorial function (known as Stirling's approximation) is:
(2for all n. If we take logarithms on both sides and use the properties that log ab = log a + log b and log a/b = log a - log b, and some asymptotic notation to hide constants, we get:n)1/2 (n/e)n <= n!
which works out to simply
ln (n!) =(An easier, but less rigorous, way to see this is to see that n! = O(nn), so log n! = O(log nn) = O(n log n).)
So the height of the decision tree has a lower bound of
(n ln n).
In the worst case, the sorting algorithm will have to "search"
all the way down to a leaf node, so
(n ln n)
comparisons is the best a comparison sort can be expected to do.
Since the number of comparisons is at least the number of array
accesses or other operations, this is the lower bound on the
worst case time-complexity of any comparison sort.
This all implies that we should be able to sort in time
(n log n)
Can we? Yes. For example, consider inserting all the array elements
into a binary search tree, then traversing the tree, replacing elements
into the array in order, e.g.:
int i = 0;
void traverse (tree *t) {
if (!t) return;
traverse (t->left);
v[i++] = t->k;
traverse (t->right);
}
Inserting takes (n log n), traversing takes less time, so this is an (n log n) sorting algorithm. However, it suffers
from the degeneracy that plagues binary search trees in general (we might
get a linked-list looking tree and it would just turn into insertion sort),
and it wastes a lot of memory. Next time we will see (n log n) sorting algorithms that use no
extra memory.