 (h-d) 2d
d=0
(h-d) 2d
d=0
int Parent (int i) {
return (i-1) / 2;
}
int Left (int i) {
return i * 2 + 1;
}
int Right (int i) {
return i * 2 + 2;
}
You can tell if an array
element i is in the heap simply by checking whether i <
heap-size. Note: this scheme
doesn't work in general with binary (possibly incomplete) trees, since
representing leaf nodes at depths less than the height of the tree
minus 1 isn't possible, and if it were, it would waste space.
This representation of an almost complete binary tree is pretty efficient, since moving around the tree involves multiplying and dividing by two, operations that can be done with simple shifts in logic, and adding one, another simple instruction. Asymptotically speaking, each of the heap node access functions above consume O(1) time.
/* makes the subheap with root i into a heap , assuming Left(i) and
* Right(i) are heaps. heap_size is a global variable.
*/
void Heapify (float A[], int i) {
int l, r, largest;
l = Left (i);
r = Right (i);
/* find the largest of the three: parent, left, and right */
if (l < heap_size && A[l] > A[i])
largest = l;
else
largest = i;
if (r < heap_size && A[r] > A[largest])
largest = r;
/* swap the parent with the largest, if needed. */
if (largest != i) {
swap (A, i, largest);
/* the exchange may have violated the heap property
* of a subheap, e.g.:
5 7
/ \ / \
4 7 ===> 4 5 <--- this subheap is
/ \ / \ / \ / \ no longer a heap!
1 2 3 6 1 2 3 6
So we must re-establish the heap property, possibly
marching down a path of the tree recursively swapping
things into place.
*/
Heapify (A, largest);
}
}
void Build_Heap (float A[], int n) {
int i;
heap_size = n;
/* each leaf is a trivial subheap, so we may begin to call
* Heapify on each parent of a leaf. Parents of leaves begin
* at index n/2. As we go up the tree making subheaps out
* of unordered array elements, we build larger and larger
* heaps, joining them at the i'th element with Heapify,
* until A[] is one big heap.
*/
for (i=n/2-1; i>=0; i--) Heapify (A, i);
}
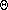 (1) time for each
recursive call. So the question is, how many recursive calls will Heapify
do? In the best case, it won't do any, so the answer is
(1) time for each
recursive call. So the question is, how many recursive calls will Heapify
do? In the best case, it won't do any, so the answer is
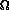 (1). We're more interested in the
worst case. In this case, Heapify traces a path from the root node
down possibly to the parent of a leaf node, swapping elements each time.
If the tree has a height of h, then Heapify can't call
itself recursively more than h times, since any path from root
to parent of a leaf is at most of length h. So Heapify
runs in time O(h). Recall that there are at most
n=2h+1-1 nodes in an almost complete binary
tree of height h, so Heapify runs in time
O(ln n).
(1). We're more interested in the
worst case. In this case, Heapify traces a path from the root node
down possibly to the parent of a leaf node, swapping elements each time.
If the tree has a height of h, then Heapify can't call
itself recursively more than h times, since any path from root
to parent of a leaf is at most of length h. So Heapify
runs in time O(h). Recall that there are at most
n=2h+1-1 nodes in an almost complete binary
tree of height h, so Heapify runs in time
O(ln n).
How long does Build-Heap take? Clearly, it calls Heapify n/2 times, so it takes O(n h) = O(n ln n). But this isn't the whole story; O(h) is an upper bound for Heapify. Most calls to Heapify are done on nodes that are the roots of subtrees far smaller than size n. For example, a node at level 4 will have only n/16 descendants under it. The larger i is in Heapify, the farther down in the tree i occurs, and thus the fewer nodes Heapify has to consider.
We'll start by counting the number of nodes at depth d in the tree, and figuring out how much time Heapify must spend on each one. We know that a complete binary tree of height d has 2d+1-1 nodes. If we subtract off all the nodes at levels lower than d (i.e., the number of nodes in a tree of height d-1), we get 2d+1-1 - (2d-1) = 2d nodes at level d. The heights of each subheap of these nodes is h-d, so at level d Heapify only has to do O(h-d) work.
Now if we count the amount of work done for all levels, i.e. from level 0 to level h, we get big-oh of:
hwhich works out to:
hAmazingly, through the magic of guesswork and a gross proof by induction you don't want to see, it turns out that:
-
d=0
hSo we can rewrite our equation, after some simple algebraic manipulations, as
d=0
2h+1- h - 2.That looks familiar; it is a little less than the number of nodes in our heap, i.e., n-1-h. So the time for Build-Heap is just O(n). Since in the best case, Heapify will have to do O(1) work and still be called n/2 times, Build-Heap will take
(n) time, so
(n) is a tight bound
for Heapify.
Now let's look at the Heapsort algorithm itself. It takes the root of the tree, which we know must be the largest element in the array, and swaps it with the last element in the array; now the largest element is in the right place. The size of the heap is reduced by one, then Heapify is done to correct the damage done by putting a small element in the root's place. This process continues until the entire array has been processed and the very smallest element is swapped up to the top of the array. It's kind of like the selection sort algorithm in reverse, only Heapsort has a O(1) way of finding the maximum element in the array! Here it is:
void Heapsort (float v[], int n) {
int i;
Build_Heap (v, n);
for (i=n-1; i>=1; i--) {
swap (v, 0, i);
heap_size--;
Heapify (v, 0);
}
}
The call to Build-Heap takes time
(n), then we do
n-1 swaps and decrements (each of constant time) and calls to
Heapify, each of time O(ln n). So the
whole thing takes (n) +
O(n ln n) = O(n ln n).
Quicksort divides an array A[p..r] into two subarrays A[p..q] and A[q+1..r] such that everything in the first subarray is less than everything in the second subarray. It then sorts the two subarrays recursively.
Here is code for Quicksort, to sort an array A from indices p through r. To sort an array v[N], you would call Quicksort(v, 0, N-1);.
void Quicksort (float A[], int p, int r) {
int q;
if (p < r) {
q = Partition (A, p, r);
Quicksort (A, p, q);
Quicksort (A, q+1, r);
}
}
q is an index into the array A between p
and r. q is expected to lie roughly halfway between
p and r, so that when Quicksort is called
recursively, the subarrays A[p..q] and
A[q+1..r] are about the same size.
If p is less than r, then the subarray can be of size no more than 1. This is the base case of the recursion; an array of size 1 is by definition sorted.
Partition is an algorithm that separates A[p..r] into A[p..q] and A[q+1..r], returning the index q. Partition ensures that everything in the "left hand" side of the array, i.e., A[p..q], is less than or equal to A[q], and everything in the "right hand" side, i.e., A[q+1..r], is greater than or equal to A[q]. The "middle" element A[q] is called the "pivot" element since it is around this element the array is turned. The best choice for the pivot element is the median of all elements in A[p..r]. That way, we are assured that the array is divided into two even halves. However, computing the median is costly. The following code for Partition works very quickly, but may possibly divide the array in a less-than-optimal way:
int Partition (float A[], int p, int r) {
float x;
int i, j;
/* choose the pivot to be the first element */
x = A[p];
/* i and j start at opposite ends of the array */
i = p-1;
j = r+1;
for (;;) {
/* go down looking for something less than the pivot */
do { j--; } while (A[j] > x);
/* go up looking for something greater than the pivot */
do { i++; } while (A[i] < x);
/* if i and j haven't met, we have found two out of order
* elements; swap them and they'll be in order
*/
if (i < j)
swap (A, i, j);
else
/* otherwise we're done; everything to the left of
* j is <= the pivot, everything to the right
* is >= the pivot.
*/
return j;
}
}
This algorithm searches the two subarrays separated by the pivot (without
knowing beforehand what the index of the pivot will turn out to be) for
pairs of elements that are not in the right place, e.g., greater than
the pivot but in the left hand side. When it finds such a pair, it swaps
them, putting them both in the correct subarray. When the search for
elements that are too big meets the search for elements that are too small,
we have found the index where the two halves split and we are done with
Partition.
So the way Quicksort works is this:
x = A[p] = 5 Array index: i p r j Array contents: 5 4 6 7 2 3 8 1 9 initial state i j 1 4 6 7 2 3 8 5 9 swapped 1 with 5 p i j r 1 4 3 7 2 6 8 5 9 swapped 6 with 3 p i j r 1 4 3 2 7 6 8 5 9 swapped 7 with 2 p j i r 1 4 3 2 7 6 8 5 9 i exceeds j; we're done. Everything in A[p..j] is less than 5. Everything in A[i..r] is greater than or equal to 5.
(1) array elements each time
through the while True loop. This loop proceeds until i
reaches j, i.e., until all elements of
A[p..r] have been visited. This is
r - p + 1 elements; if we call this quantity n,
Partition takes
(n) time. Initially,
the first instance of Quicksort calls Partition on the
entire array, where n is the number of elements to be sorted.
To analyze Quicksort, we must first make an assumption that may or may not be true in practice. We must assume that x is always a good estimate of the median so that q ends up halfway from p to r. If this is true, then Quicksort behaves asymptotically exactly like merge sort. The time it takes can be characterized by:
T(n) =It turns out that this time is
- 0 otherwise.
(n ln n)
(you'll find out why in Analysis of Algorithms :-).
If we assume that all the elements of A are uniformly randomly
distributed, then we are likely to see this
(n ln n) behavior.
Even if the array is consistently split into one subarray of size
10% n and the other of 90% n, we will still see
(n ln n) time,
although in the rigorous analysis we will find a log base 10 term instead
of log base 2, making the constant absorbed into the big-Omega somewhat larger.
More formally, in the case of an array that is already sorted, the pivot will always remain at the beginning of the subarray, giving a left-hand subarray of size 1 and right-hand subarray of size n-1. This gives us a time of:
T(n) = T(n-1) +Once you count up all the recursive calls to Quicksort, this works out to:
nwhich gives us
k = 1
((n(n+1))/2) =
(n2).
That's just as bad as bubble sort or selection sort. Even worse, because bubble sort runs in time O(n) on already-sorted data. We can try to remedy this by picking different values for the pivot and tweaking Partition to try to predict what the best pivot will be, but there will always be some degenerate case that will exhibit this worst-case behavior. Another approach is to pick the pivot randomly. This way, the probability of the worst-case performance happening shifts from the very high chance that the data will already be somewhat sorted to the very low chance that we will pick an extremely unlikely sequence of random numbers. Let's make a new version of Partition that uses the standard C library function rand returning a "random" integer:
int Randomized_Partition (float A[], int p, int r) {
int i;
i = (rand () % (r - p)) + r;
swap (A, i, p);
return Partition (A, p, r);
}
This way, the pivot could be anything in the array, and has a much better
chance of being near the median even in already-sorted data.
The standard C function qsort() is a randomized version of Quicksort. It is very fast and sufficient for all but the most specialized sorting applications.
Another tweak to Quicksort has been to use something like selection sort when the number of elements goes below some empirically determined threshold. For some small values of n, selection sort might actually be faster than Quicksort, which has a high overhead because of all the recursion and Partitioning. The new tweaked version would look something like:
void Quicksort (float A[], int p, int r) {
int q;
if ((r - p) < some_threshold) {
selection_sort (A, p, r);
} else if (p < r) {
q = Partition (A, p, r);
Quicksort (A, p, q);
Quicksort (A, q+1, r);
}
}