The main point of the experiment is to show that evolving neural networks using NEAT allows a new, more powerful kind of competitive coevolution to take place. This powerful form of coevolution is called continual competitive coevolution. The idea is that because NEAT allows networks to add structure indefinitely, a competing population in competitive coevolution should always be able to supplement a strategy by complexifying that strategy through the addition of new structure. The hope is that increasingly sophisticated strategies will utilize increasingly complex structures, preventing the arms race from stagnating.
The competition
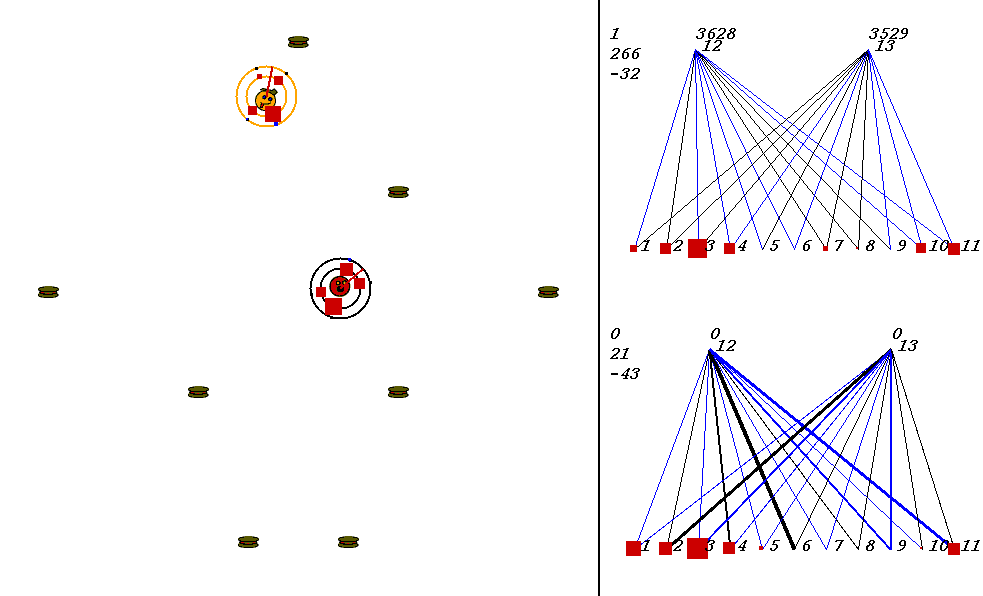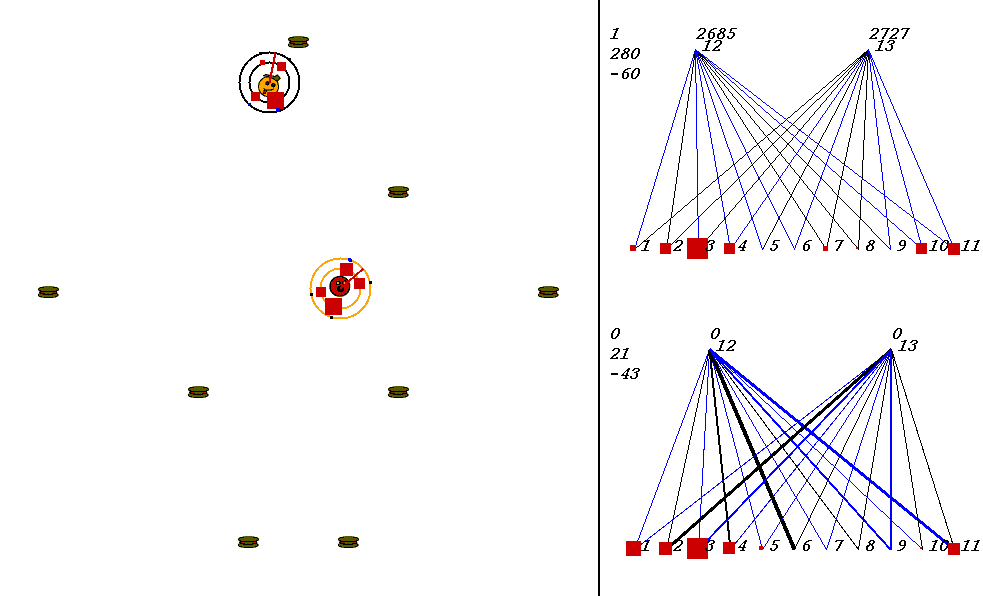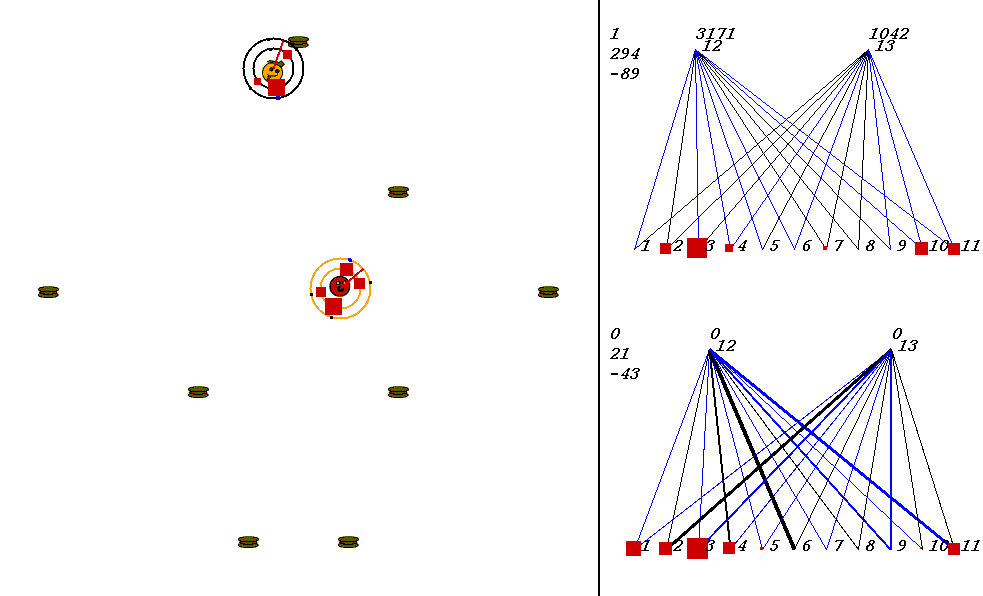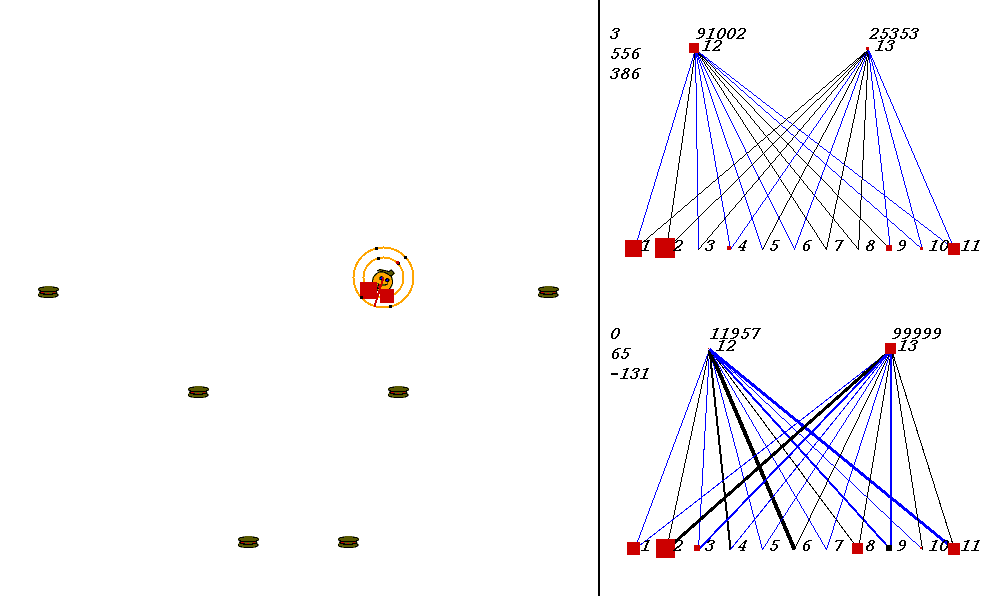
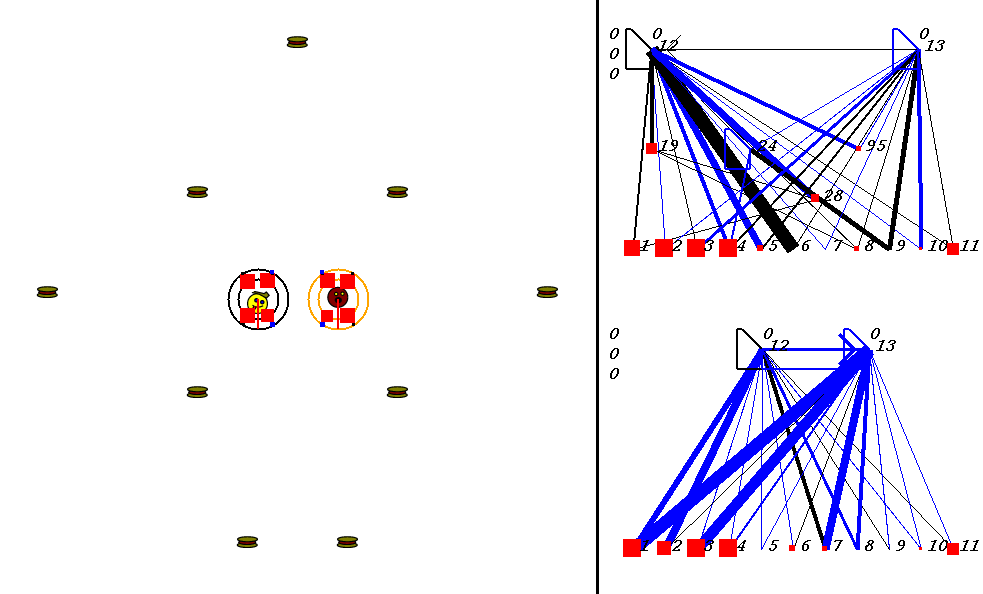
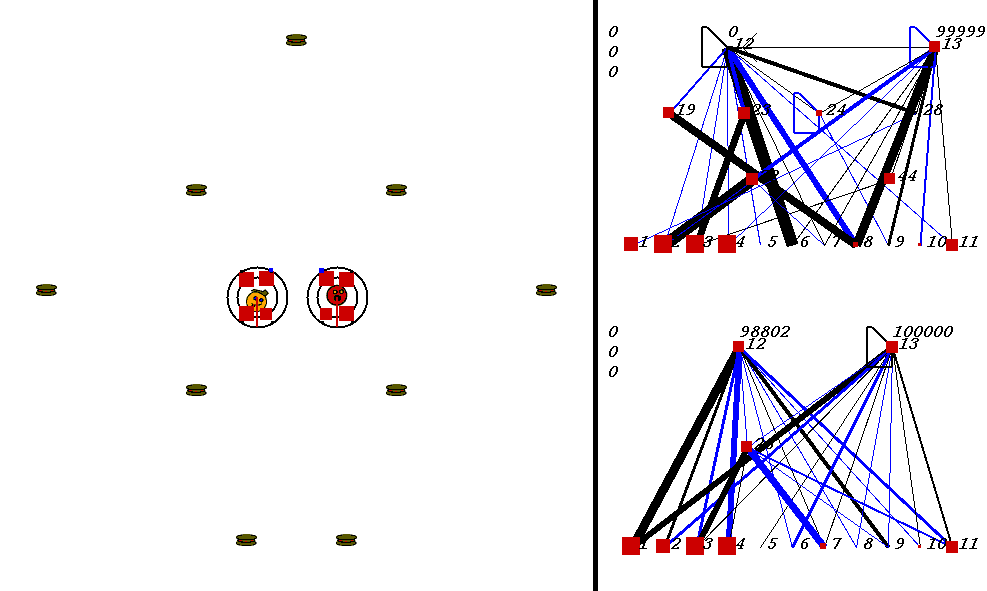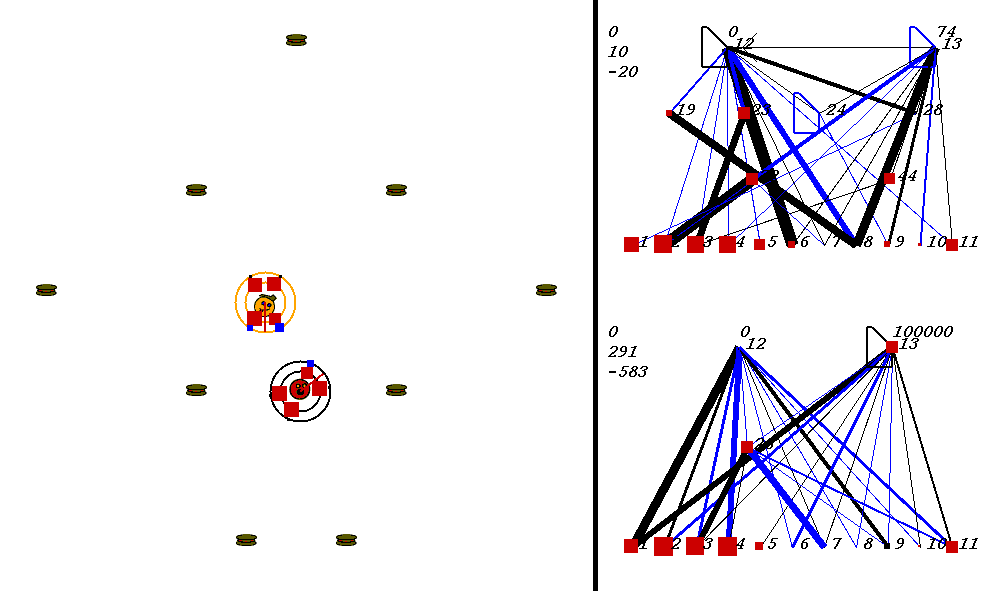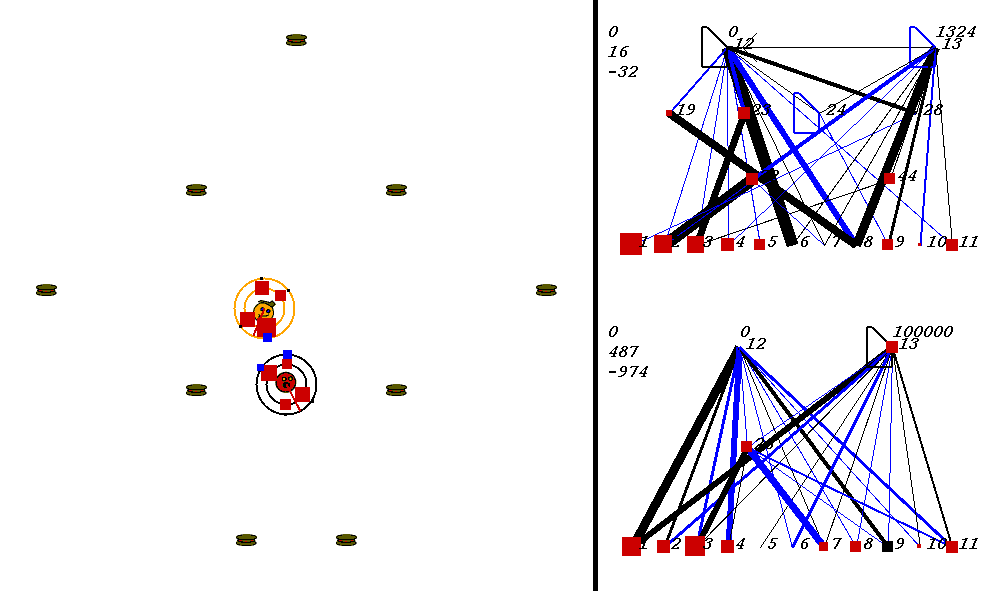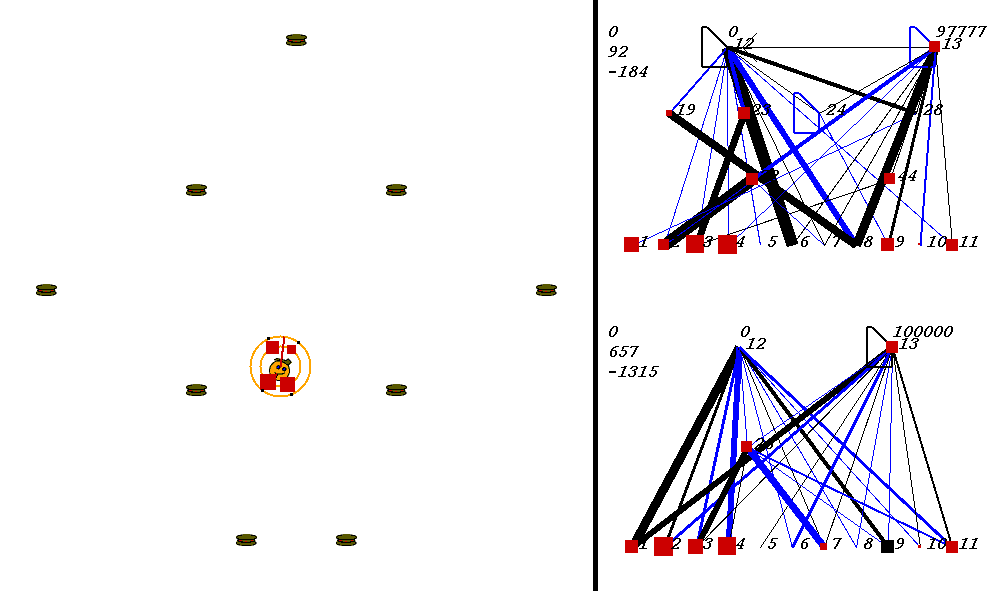
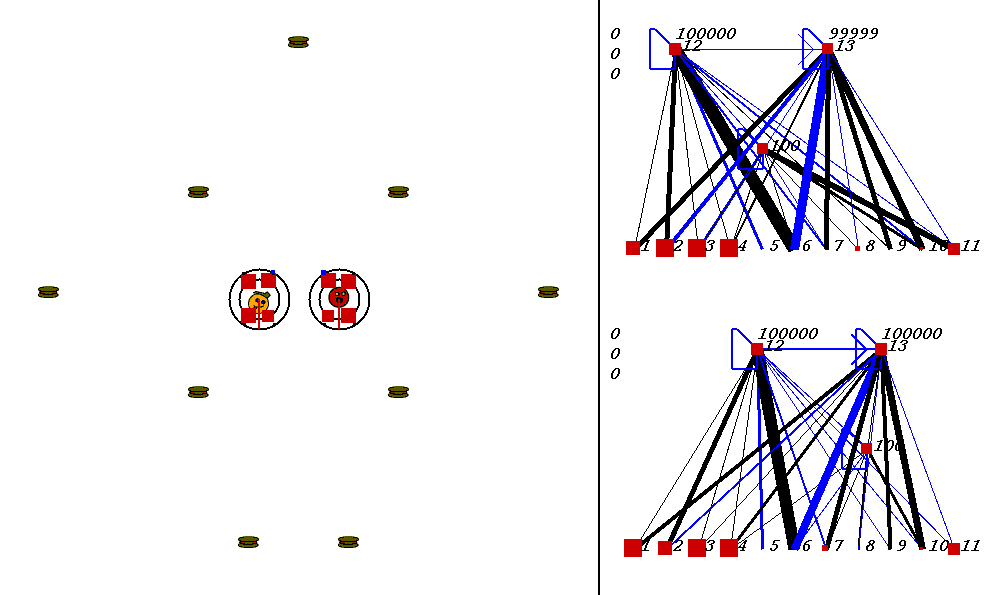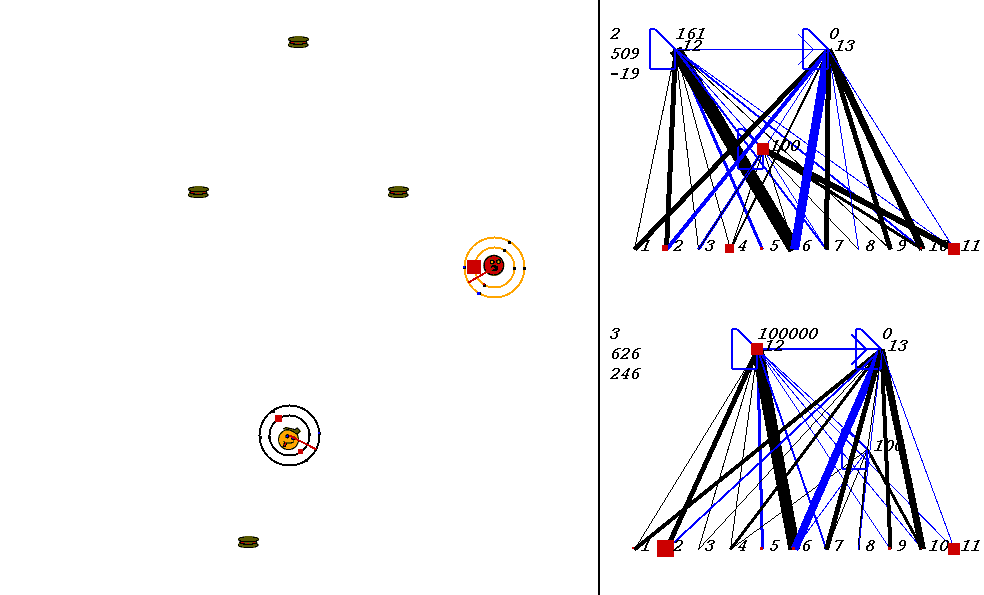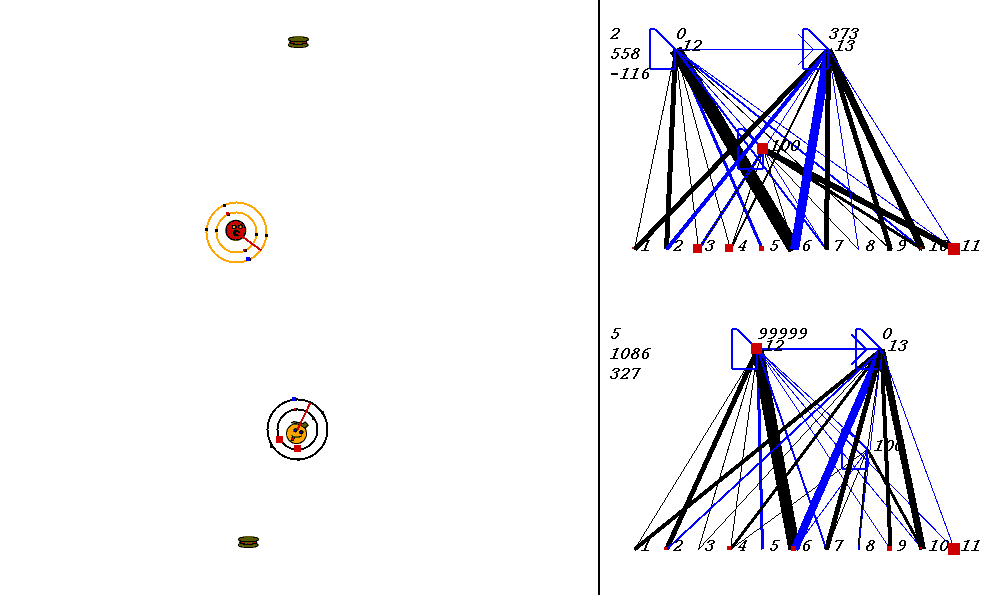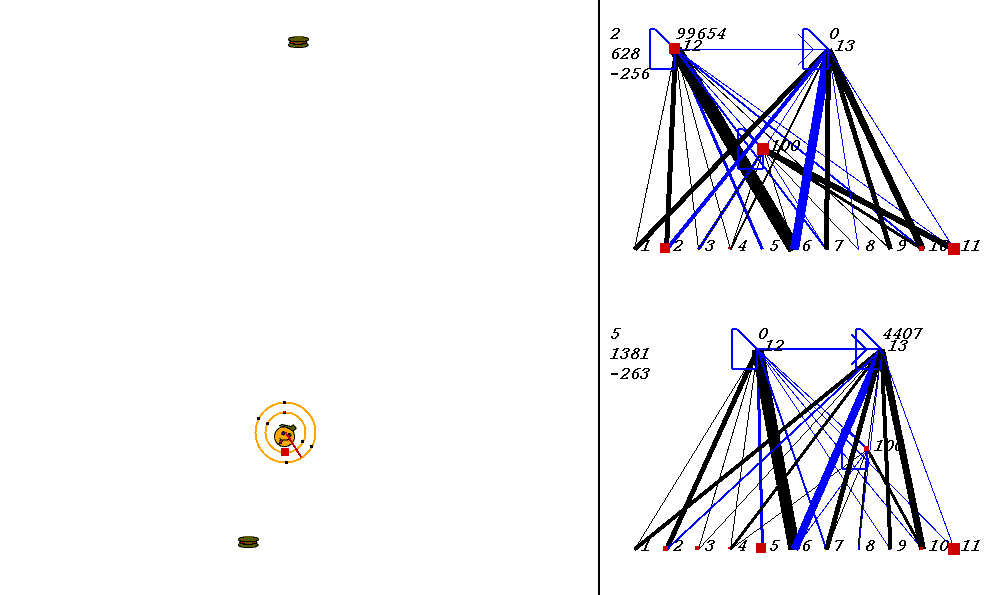
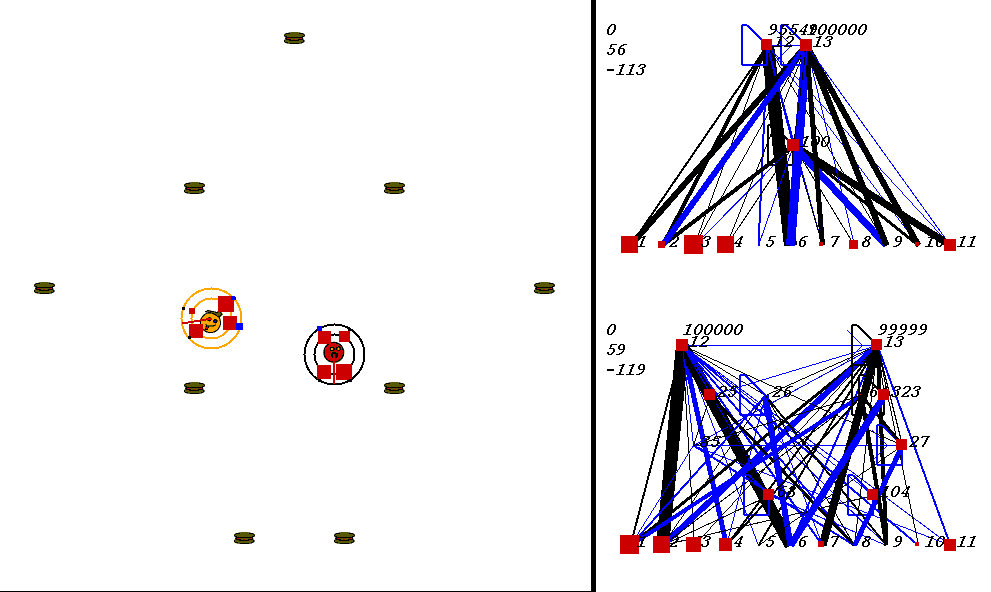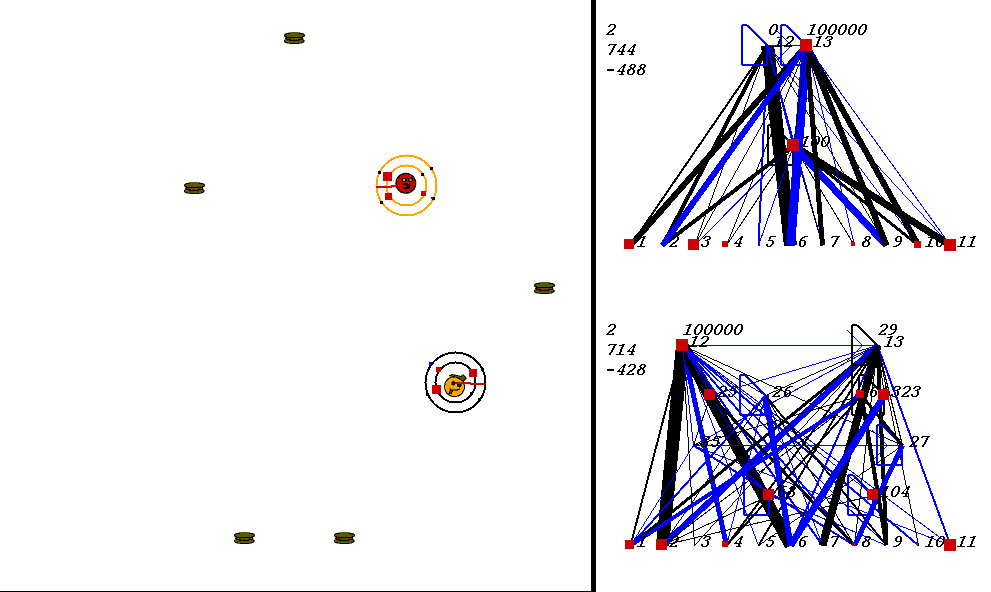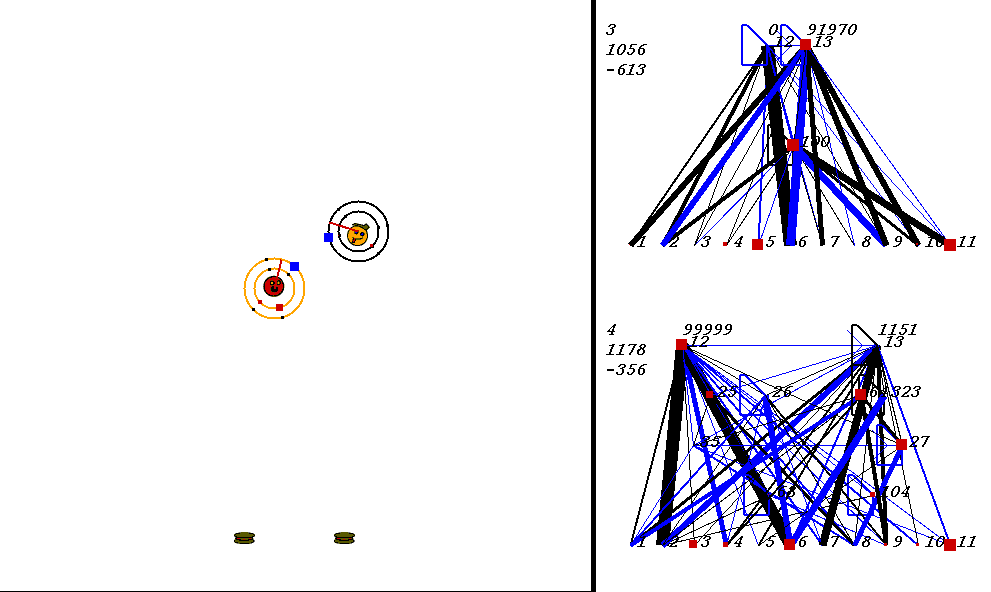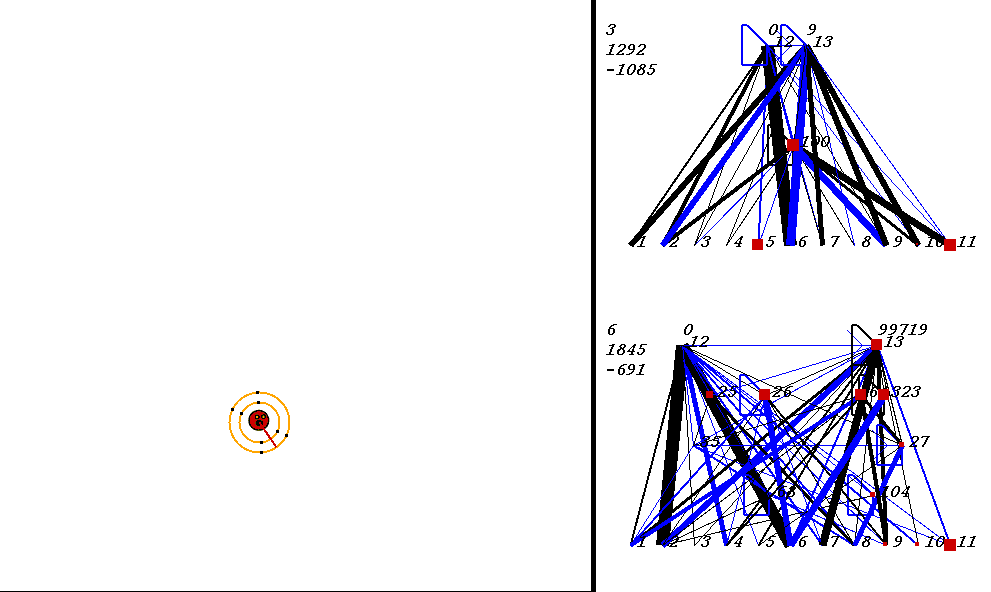
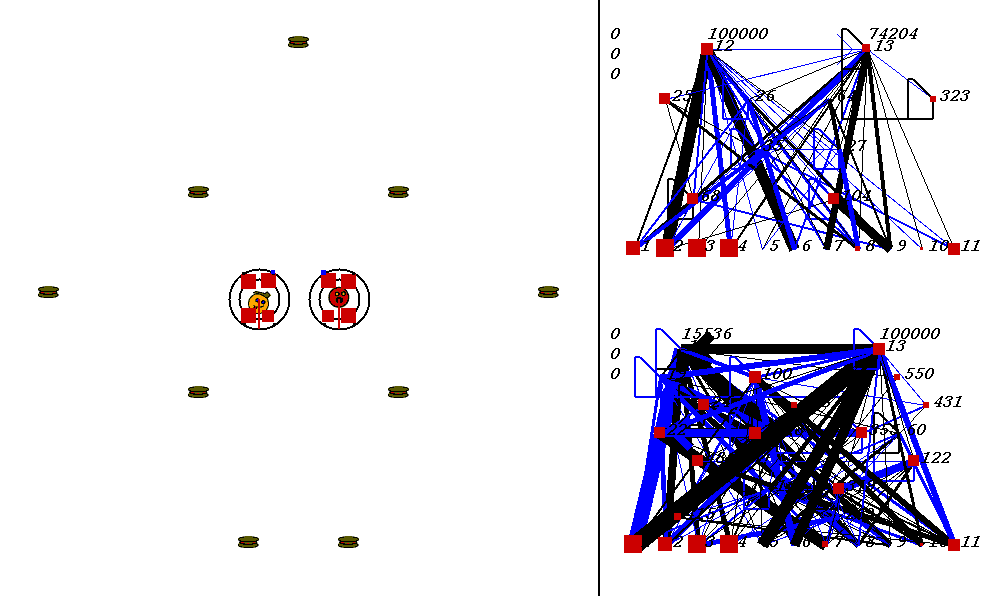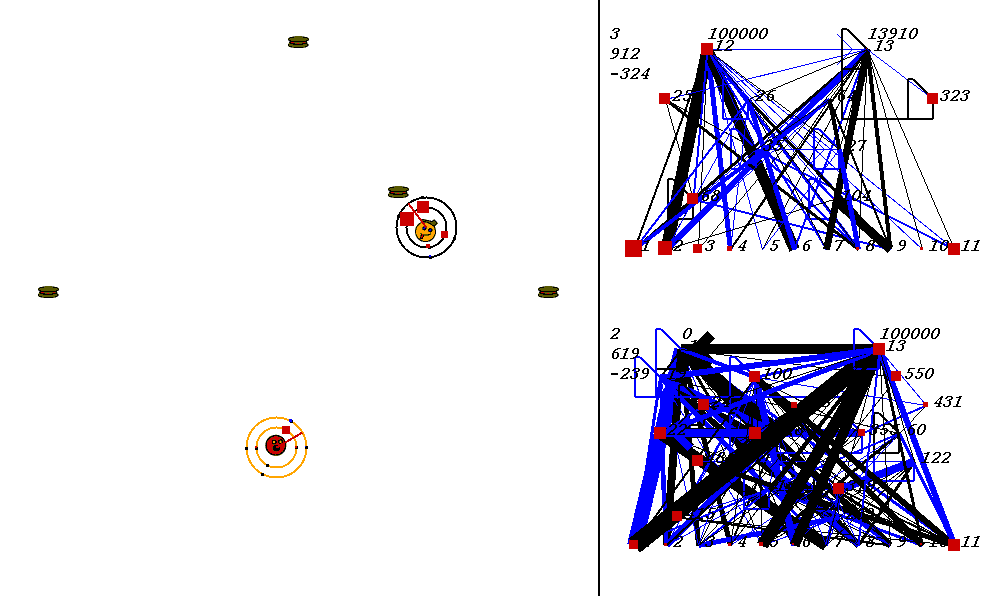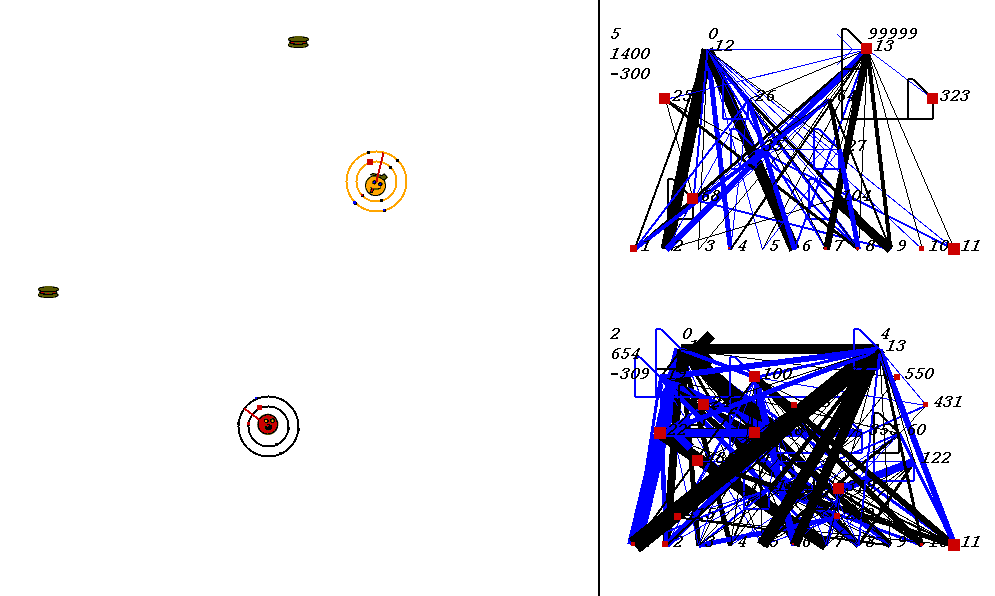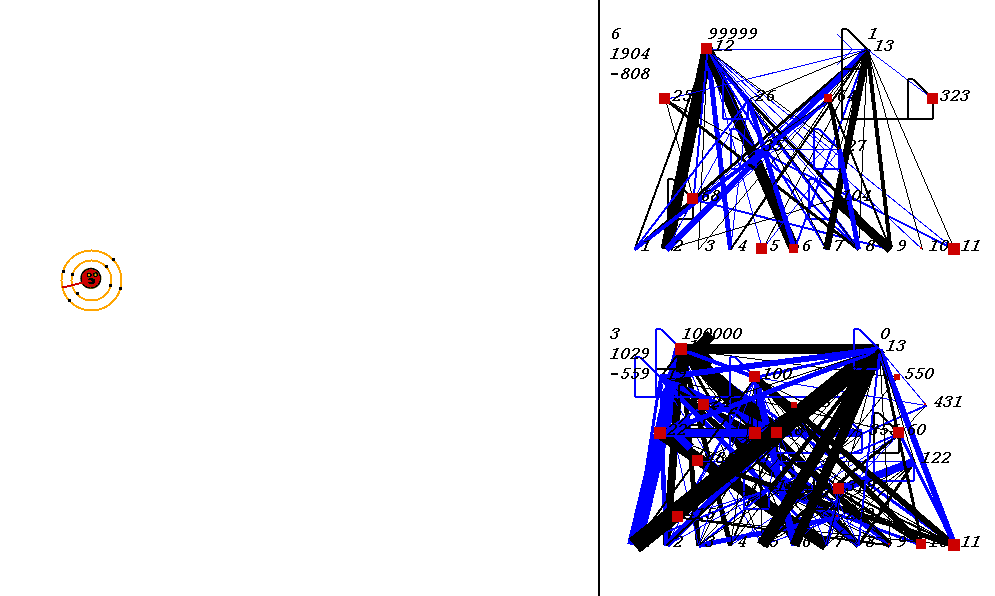
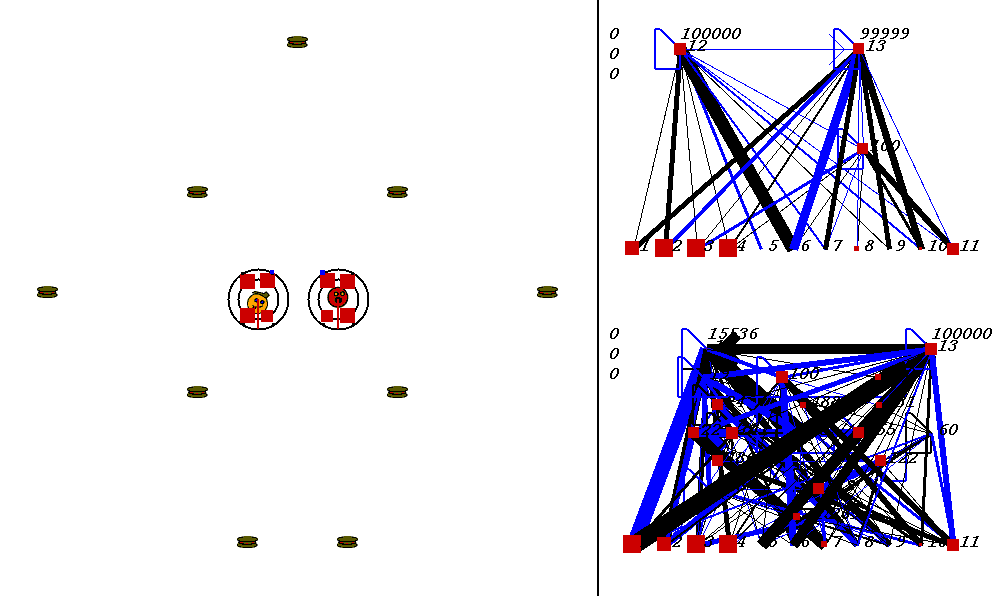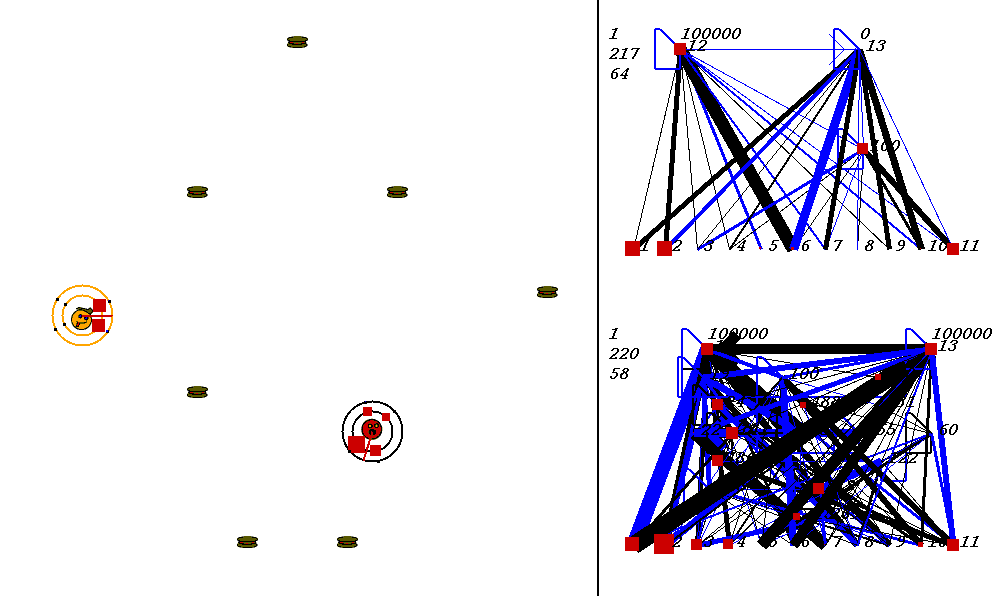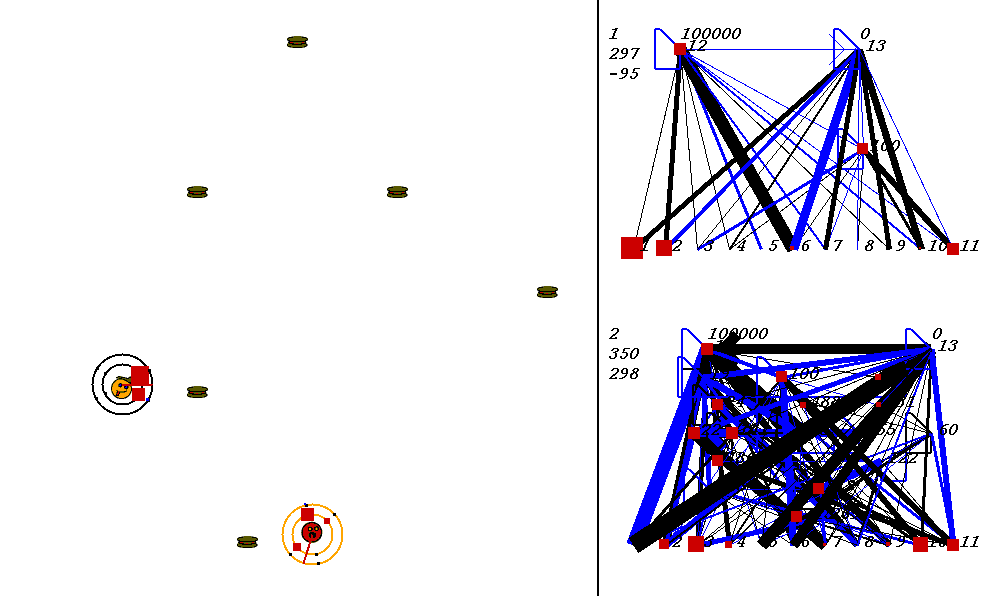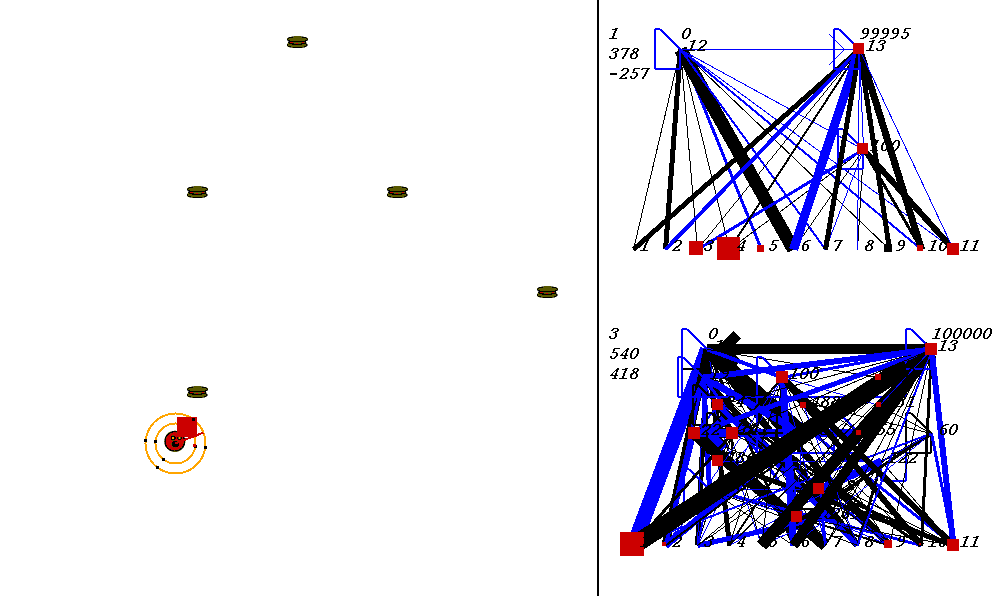
The competitive task is challenging. The robots always start out in a world with exactly the same configuration. 9 pieces of food are placed in the world, with the two robots in the center. The image below shows what the world looks like. Please adjust your browser so that the entire image is visible on your screen:
On the left of the image is the world where the robots collect food. On the right are the robots' neural network controllers. The yellow robot is controlled by the upper neural network, and the red robot is controlled by the lower network.
Each network has 3 numbers to its left. These numbers represent:
Whenever a robot encounters a piece of food, its energy goes up by 500. At the same time, energy decreases the more distance a robot travels. There is no limit to how low energy can go; it can easily sink below zero.
The only way for a robot to win the compition is to collide with its opponent while its energy is higher than its opponent's energy. This rule makes the game interesting, because the predator-prey relationship can constantly shift back and forth, depending on food being eaten. Energy is used for no other purpose than to determine who kills whom in a collision; it does not affect robot's ability to move, although moving can be risky when energy is low, especially when no food is available, since the robot with lower energy can be killed. As long as a robot has higher energy, it is safe.
The rules of the game encourage an unusual phenomenon to evolve: switching behavior. Robots must learn to change their goals quickly depending on which robot has the most energy at any given time. A robot with lower energy may decide to stay put and hope its opponent wastes energy by running around, or it may try to find more food. As you can imagine, complex strategies arise. The main reason that this scenario leads to complexity is that unlike in standard predator-prey tasks, both the predator and the prey are evolving to outwit each other, and networks must be capable of playing both roles.
Understanding the Movies
In the image above, the world contains two robots, each surrounded by 2 concentric rings. The rings represent rings of range sensors, which work like Khepera range sensors. However, one ring of sensors can detect robots, and the other can detect food. Each ring has 4 sensors with slightly overlapping arcs of sensitivity. The inner ring contains the food sensors, and the outer ring holds the robot sensors. When you watch the movies, you can actually see the sensor activation levels on the rings themselves, and you can see the sensors swiveling as the robots turn. Sensor activations are depicted as squares of different sizes. Note that the robot who currently has the higher energy level has yellow sensor rings, whereas the robot with lower energy has black sensor rings. This way, it is easy to see who could be playing predator at any given time.The sensors map to the inputs of of the neural networks on the right of the image. The inputs are at the bottom of each network:
Each network has two motor outputs (at the top). The outputs represent the force to be applied the left and right motor. Each motor drives a wheel. Thus, running the left motor alone causes a turn to the right, etc. Each output has a number above it representing its current activation on a scale of 0 to 100,000 (actual outputs are between 0 and 1).
The neural networks depict evolved topologies. They are composed of:
Since NEAT evolves arbitrary topologies, topologies can become quite complex. The visualizations are designed to do their best to display the networks as clearly as possible.
The experiment
As usual , NEAT begins with zero-hidden-node networks and evolves topologies and links from there. If you want to know more details about how the NEAT method works, see our paper. The initial generation contained two populations, A and B, all with uniform zero-hidden-node topologies. A and B were pitted against each other in a competitive coevolution host/parasite framework (see "New Method for Competitive Coevolution", Rosin and Belew, 1996). As the generations progress, an arms race built up between A and B. The results show that increasingly sophisticated structures continually arose (for hundreds of generations), each newly dominant strategy containing significantly more structure than the previous. Also, there was no circularity in the dominance relationships.Who's the best?
Before moving to the animations, we should address one serious question: How do we know that a network is better than another network from just a single competition? There are two answers to this question:First, the training scenarios are all deterministic (meaning that the food and robots start in exactly the same positions). Therefore, if a network wins against another network in this setup, it will always win, since we did not introduce noise to the sensors.
However, in testing the networks for superiority we should really play many different competitions to attain statistical significance demonstrating that one network really is better than another. Thus, we played each pair of competitors 1,000 times with slightly different food configurations. The superior network was verified by winning a significant majority of these 1,000 competitions. Thus, the movies below are not the reason that we say one network is dominant over another. Rather, they are interesting to observe after the fact, knowing which network is dominant. Knowing this, we can see what strategy the dominant network actually uses by watching the movies. It just so happens that in the movies below, the superior network is always the winner, which is not surprising, since it is what we expect probabilistically.