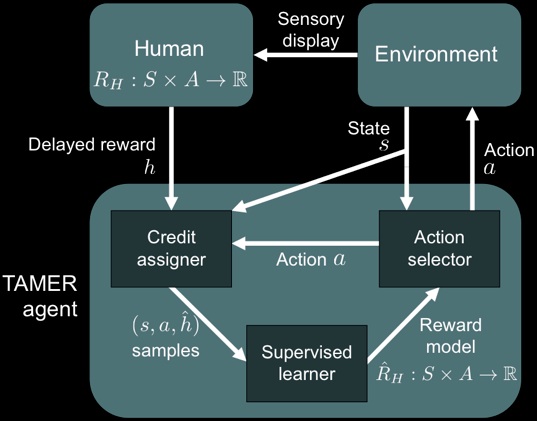
In our work on interactive shaping, we introduced a framework called Training an Agent Manually via Evaluative Reinforcement (TAMER). The TAMER framework, shown above, is an approach to the Interactive Shaping Problem. TAMER differs from past approaches to learning from human reward in three key ways:
-
1.TAMER addresses delays in human evaluation through credit assignment,
-
2.TAMER learns a predictive model of human reward,
-
3.and at each time step, TAMER chooses the action that is predicted to directly elicit the most reward, eschewing consideration of the action's effect on future state (i.e., in reinforcement learning terms, TAMER myopically values state-action pairs using a discount factor of 0).
TAMER is built from the intuition that human trainers can give feedback that constitutes a complete judgement on the long-term desirability of recent behavior. Chapter 3 of my dissertation gives the most current description of TAMER, which was originally introduced in several conference publications.
In Chapter 6, we investigate the impact of various reward discounting rates on agent trainability; our analysis there suggests even more powerful solutions to interactive shaping than TAMER and yields the first reported instance of learning successfully from human reward with a very low discount rate (i.e., a high discount factor).
Check out our videos of TAMER agents being trained.