Muon is a Nuclear Lion King#
|
We show that the recently proposed Muon optimizer ([JJB+24], [LSY+25]) is an instance of the Lion-\(\mathcal{K}\) optimizer [CLLL23] when equipped with the nuclear norm. Using the theoretical results of Lion-\(\mathcal{K}\), this immediately establishes that Muon (with weight decay) solves a constrained optimization problem that limits the maximum singular values of the weight matrices. Additionally, it entails a Lyapunov function for the continuous-time dynamics of the Muon optimizer, thereby confirming its asymptotic convergence. |
|

Lion-\(\mathcal{K}\) Optimizer#
Lion-\(\mathcal{K}\) [CLLL23] is a family of optimization algorithms developed to provide a theoretical foundation for the Lion optimizer, which was originally discovered via symbolic search [CLH+23]. Let \(\mathcal{F} \colon \mathbb{X} \to \mathbb{R}\) be an objective function on the domain \(\mathbb{X}\). Assume \(\mathbb{X} = \mathbb{R}^{n\times m}\), corresponding to the weight matrices in neural networks. The update rule for Lion-\(\mathcal{K}\) optimizers is
where \(\eta > 0\) is the learning rate, \(\beta_{\texttt{nesterov}}, \beta_{\texttt{polyak}} \in [0, 1]\) are two momentum coefficients, \(\lambda \geq 0\) is the weight decay coefficient, \(\mathcal{K} \colon \mathbb{X} \to \mathbb{R}\) is a convex function, and \(\nabla \mathcal{K}\) denotes the gradient of \(\mathcal K\), or one of its sub-gradient in non-differentiable cases.
Key Design Elements of Lion-\(\mathcal{K}\)
Lion-\(\mathcal{K}\) can be seen as mixing several fundamental design elements in optimization:
Polyak momentum \({M}_{t}\), which accumulates the exponential moving average of the gradients, controlled by the coefficient \(\beta_{\texttt{polyak}}\).
Nesterov momentum \(\tilde{{M}}_{t}\), which introduces extra gradient components into the update, controlled by the coefficient \(\beta_{\texttt{nesterov}}\).
Nonlinear Preconditioning: \(\nabla \mathcal{K}\) applies a transformation to the momentum before it is used to update the parameters. This is legitimate since \(\nabla \mathcal{K}\) is a monotone map, meaning that \(\langle \nabla \mathcal{K}(X) - \nabla \mathcal{K}(Y), X - Y \rangle \geq 0\), which follows from the convexity of \(\mathcal{K}\).
Weight Decay \(\lambda {X}_t\), which reduces the parameter magnitude in addition to the update \(\nabla \mathcal{K}(\tilde{{M}}_t)\). This introduces a regularization effect (see below) and is closely related to Frank-Wolfe style algorithms.
The Problem It Solves#
Due to the interplay of the weight decay and use of the \(\nabla \mathcal{K}(\cdot)\) mapping, the Lion-\({\mathcal{K}}\) optimizer solves the following regularized optimization problem:
where \({\mathcal{K}}^*\) denotes the convex conjugate function of \({\mathcal{K}}\), defined as
where \(\langle {X}, {Z} \rangle = \operatorname{trace}({X}^\top {Z})\).
To gain a quick heuristic understanding of how the regularization term arises, we can simply exam the fixed point of the optimizer. Assume the algorithm reaches a fixed point, such that \({M}_{t+1} = {M}_t\), \({X}_{t+1} = {X}_t\), we would have \({M}_{t+1} = \tilde{{M}}_{t+1} = - \nabla \mathcal{F}({X}_t)\) and \(\nabla \mathcal{K}(\tilde{{M}}_{t+1} ) - \lambda {X}_t = 0.\) This yields
Noting that \(\nabla \mathcal{K}^*(\cdot)\) is the inverse function of \(\nabla \mathcal{K}(\cdot)\) by convex conjugacy, we have
where we used \(\nabla_{X}(\frac{1}{\lambda}\mathcal{K}^*(\lambda X)) = \nabla\mathcal{K}^*(\lambda X)\). This suggests that every fixed point of the algorithm must be a stationary point of the regularized objective \(\hat{\mathcal{F}}\).
The Lyapunov Function#
The fixed point analysis alone does not guarantee the convergence of the algorithm. A full analysis was established in [CLLL23] using a Lyapunov function method. To understand this, it helps to focus on the limit of small step sizes, when the dynamics of Lion-\(\mathcal{K}\) can be modeled by the following ODE:
where the effect of Nesterov momentum is captured by \(\varepsilon \in [0,1]\).
It is not immediately obvious why the Lion-\(\mathcal{K}\) ODE would serve to minimize \(\hat{\mathcal{F}}({X})\), as the ODE does not necessarily guarantee a monotonic decrease in \(\hat{\mathcal{F}}({X})\). However, it was found that the ODE does monotonically minimize the following auxiliary function:
with
It can be shown that the Lion-\(\mathcal K\) ODE minimizes \(\mathcal{H}({X}, {M}) \) in the sense that it is monotonically decreased along the ODE trajectories, that is, \(\frac{d}{dt} \mathcal{H}({X}_t, {M}_t) \leq 0,\) until a local minimum is achieved. In other words, \(\mathcal{H}({X}, {M}) \) admits a Lyapunov function of the Lion-\(\mathcal K\) ODE. Here, \(\mathcal{H}({X}, {M})\) is a joint function of position \({X}\) and momentum \({M}\). It can be interpreted as a Hamiltonian function in a physical metaphor, where \(\hat{\mathcal{F}}(X)\) is the potential energy, and the additional term \(\mathcal{D}({M}, \lambda {X}) \) represents a form of kinetic energy.
Moreover, minimizing \(\mathcal{H}({X}, {M})\) is equivalent to minimizing the loss \(\hat{\mathcal{F}}({X})\), that is, \(\hat{\mathcal{F}}({X}) = \min_{{M}} \mathcal{H}({X}, {M}).\) This can be seen by Fenchel-Young inequality, which ensures that \(\mathcal{D}({M}, \lambda {X}) \geq 0\) and that the optimum \(\mathcal{D}({M}, \lambda {X}) = 0 \) can always be achieved by choosing \({M} = \nabla \mathcal{K}^*(\lambda {X})\) for any fixed \({X}\).
Constrained Optimization#
As shown in examples below, it is common to have the convex conjugate \(\mathcal K^*({X})\) to take positive infinite values. In this case, Lion-\(\mathcal{K}\) effectively solves a constrained optimization:
where \( \operatorname{dom} {\mathcal{K}}^* = \{X \colon \mathcal K^*(X) <+\infty\}\) denotes the finite-value domain of \(\K^*\).
If the algorithm is initialized outside this domain, the dynamics ensure that \({X}_t\) is driven into the domain rapidly and stays inside afterwards. Specifically, this process is guaranteed to be exponentially fast in time:
Here, \(\operatorname{dist}(\lambda {X}_t, \operatorname{dom} (\mathcal{K}^*))\) denotes the distance from the point \(\lambda {X}_t\) to the domain \(\operatorname{dom} (\mathcal{K}^*)\), measured using any distance metric that satisfies the triangle inequality. Consequently, \(\lambda {X}_t\) rapidly converges to \(\operatorname{dom} (\mathcal{K}^*)\) and remains within this domain once it arrives, where the Lyapunov function is finite and decreases monotonically.
Lion via Sign#
Lion-\(\mathcal{K}\) induces different algorithms with different choices of \(\mathcal{K}\). The Lion optimizer [CLH+23] yields an update of the form
where \(\operatorname{sign}(\cdot)\) is the element-wise signum function defined by \(\operatorname{sign}(x) =x /|x|\) for \(x\neq 0\), and \(\operatorname{sign}(0) =0\).
It is recovered as a Lion-\(\mathcal{K}\) with
where \(\delta\) is the Dirac indicator function:
Hence, the objective that Lion minimizes is \(\hat{\mathcal{F}}(X) = \mathcal{F}(X) + \frac{1}{\lambda} \delta (\|{\lambda X}\|_\infty \leq 1)\), which induces a bound-constrained optimization problem:
The bound \(\frac{1}{\lambda}\) is solely determined by the weight decay coefficient \(\lambda\). Without weight decay (\(\lambda = 0\)), it reduces to the original unconstrained optimization problem.
In fact, the bound constraint arises from any update of form \(X_{t+1} = X_t + \epsilon(\operatorname{sign}(\tilde M_{t+1}) - \lambda X_t)\), regardless of how \(\tilde M_{t+1}\) is updated. Intuitively, because \(\norm{\operatorname{sign}(\tilde M_{t+1}) }_\infty \leq 1\), the weight decay term would denominate the update whenever the constraint is not satisfied (i.e., \(\norm{\lambda X_t}_\infty > 1\)), leading to an exponential decrease in magnitude. The following result is a discrete-time variant of (1).
Proposition 1
For any update of form \(X_{t+1} = X_t + \epsilon(\operatorname{sign}(\tilde M_{t+1}) - \lambda X_t)\) with \(\epsilon \lambda \leq 1\) and \(\lambda >0\), we have
Let \(\Phi(X) = \max(\norm{X}_\infty - 1/\lambda, 0)\) so that \(\Phi(X)=0\) means the constraint of \(\norm{X}_\infty\leq 1/\lambda\) is satisfied. Then we have from above that
This suggests that the violation of constraint decreases exponentially fast.
Proof. Let \(O_t = \operatorname{sign}(\tilde M_{t+1})\), for which we have \(\norm{O_t}_\infty\leq 1\) by the property of the sign function. We have
Applying this recursively yields the result.
The bound analysis does not mean that \(\mathcal{F}(X)\) is minimized within the constrained set. Ultimately, we need to resort to the Lyapunov function, which is
Note that \(\mathcal{H}(X, M) \geq \mathcal{F}(X)\) when \(\norm{X}_\infty \leq1/\lambda\). Hence, the algorithm monotonically decreases an upper bound of \(\mathcal{F}(X)\) within the constrained set.
Muon via Matrix Sign#
The Muon optimizer [JJB+24, LSY+25], with Nesterov momentum and weight decay, has a form of
where \(\operatorname{msign}({X})\) is the matrix sign function, defined as
with \({X} = U \Sigma V\) the singular value decomposition of \({X}\), and \((\cdot)^{+1/2}\) the Moore-Penrose inverse of the matrix square root. The \(\operatorname{msign}({X})\) is also known as the Mahalanobis whitening, or zero-phase component analysis (ZCA) whitening, which stands as the optimal whitening procedure that minimizes the distortion with the original data. It is also closely related to the polar decomposition of \({X}\).
Muon can be viewed as the Lion-\(\mathcal{K}\) with \(\mathcal{K}\) taken as the nuclear norm of \({X}\):
for which we can take \(\nabla\mathcal{K}({X}) = \operatorname{msign}({X})\). Here, \(\mnorm{{X}}_p\) for \(p = [0,\infty]\) denotes the Schatten \(p\)-norm defined as
where \(\sigma_i({X})\) is the \(i\)th singular value of \({X}\). In particular, when \(p=1\) or \(\infty\), we have
where \(\mnorm{{X}}_1\) is known as the nuclear norm, or trace norm, and \(\mnorm{{X}}_\infty\) is the spectral norm.
Thus, the Muon optimizer solves a constrained optimization on an upper bound on the maximum singular values on the weight matrices:
The Lyapunov function is
|
|
|
|---|---|---|
\(\lambda = 0\) (unconstrained) |
\(\lambda = 1\) (constraint initially satisfied) |
\(\lambda = 2\) (constraint initially violated) |
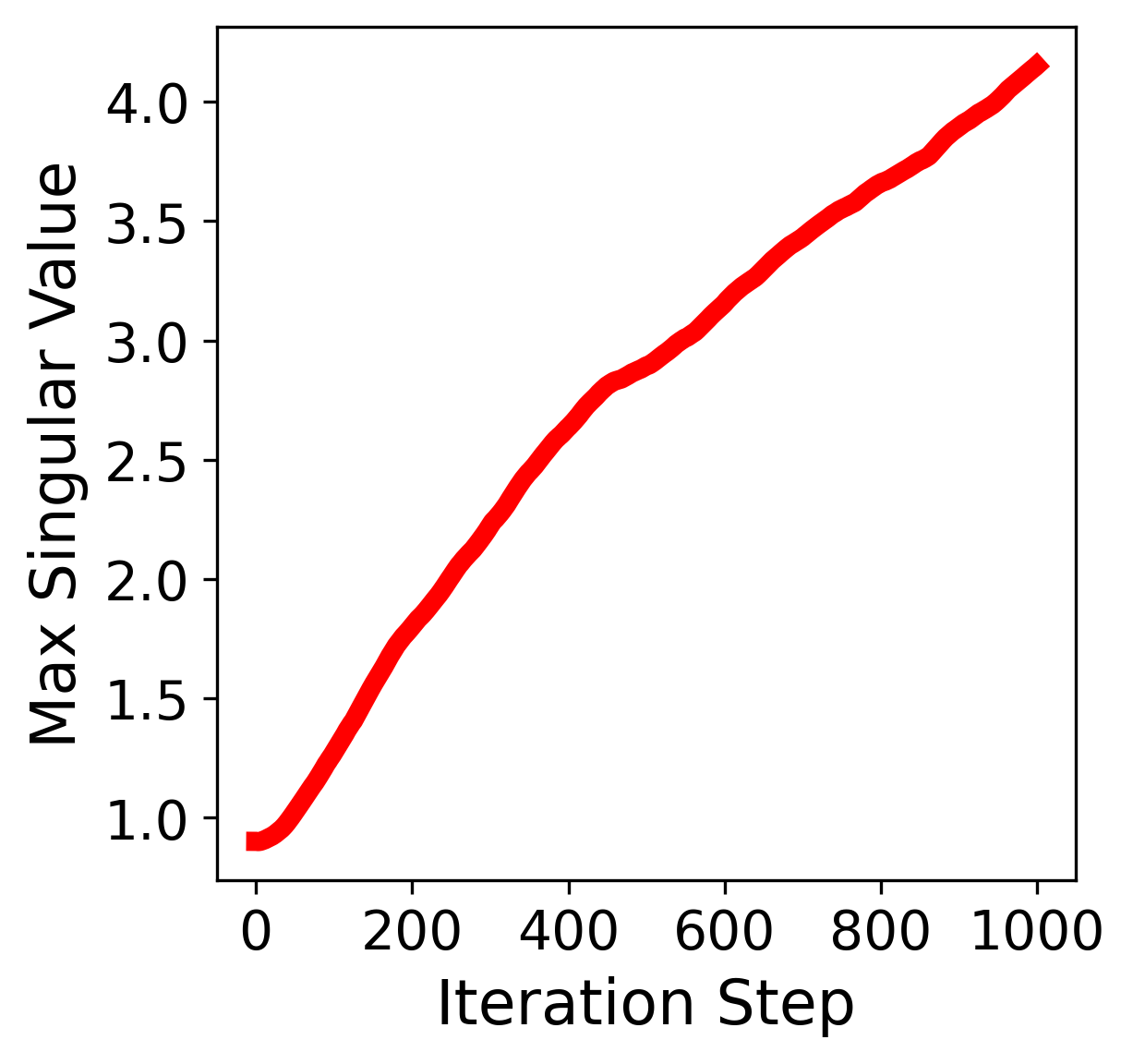
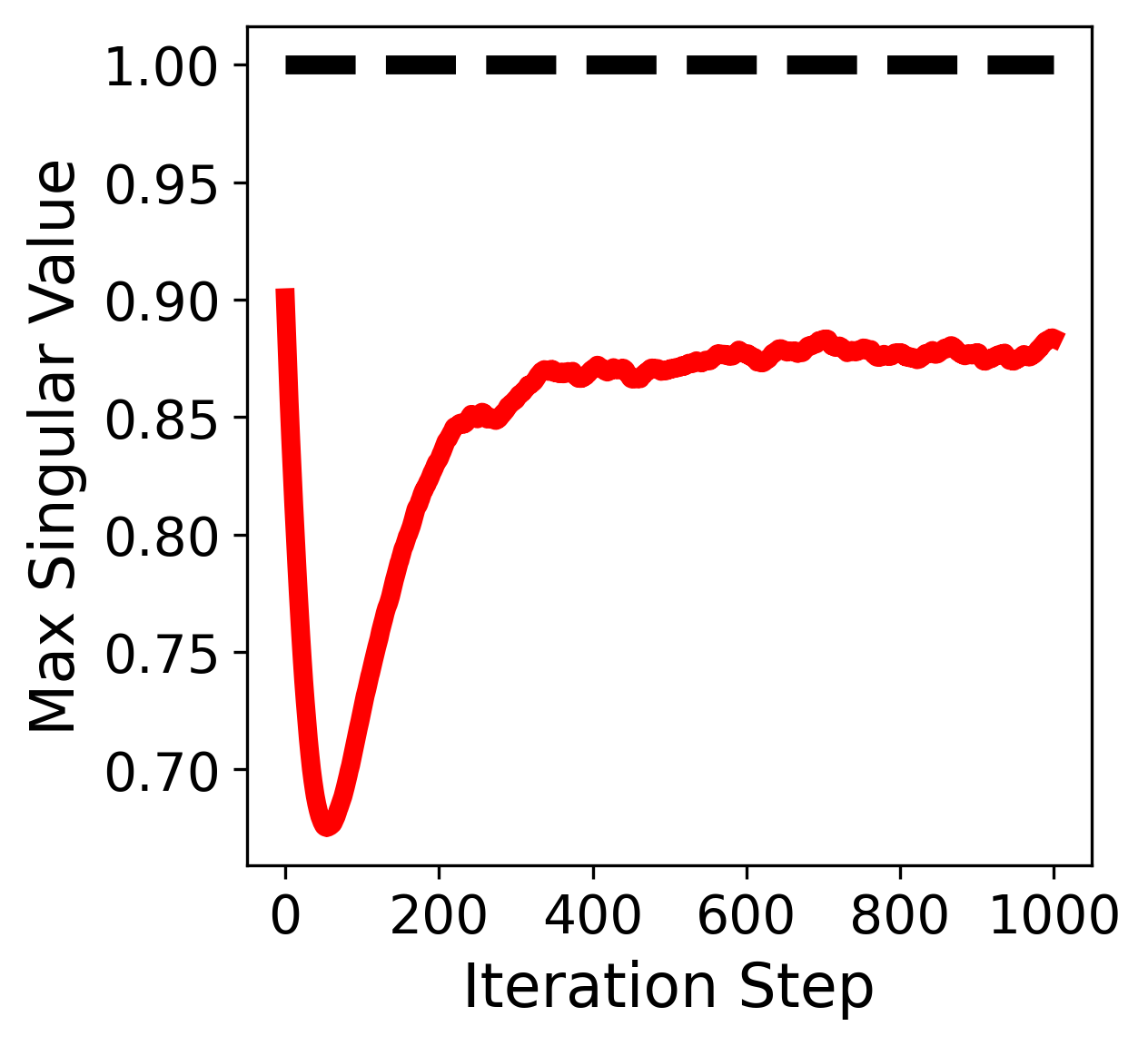
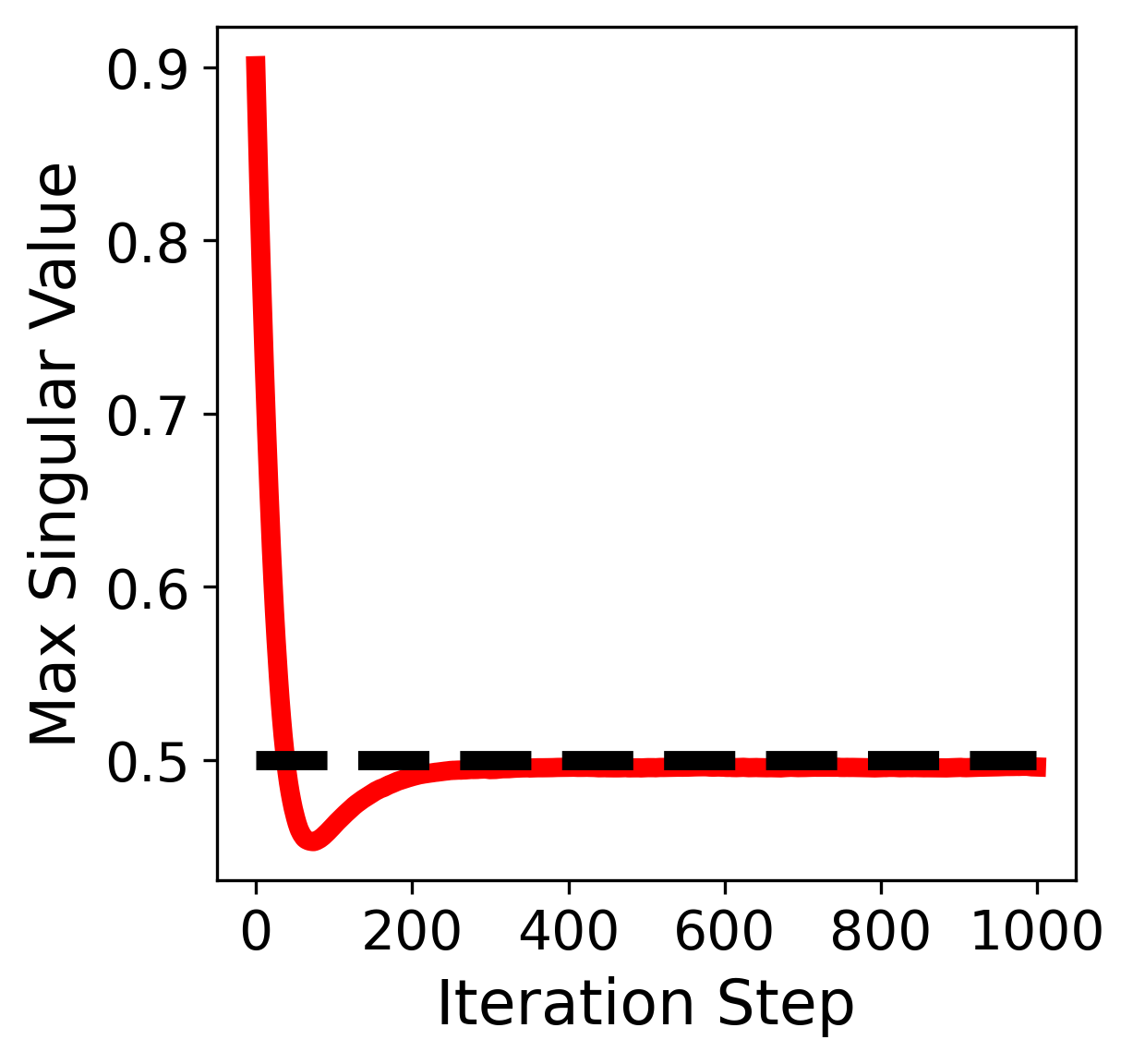
Figure: Maximum singular value \(\sigma_{\max}(X)\) vs. iteration when using Muon with different weight decay coefficients \(\lambda\).
Generalizing to Proposition 1 for Lion, the constraint enforcement property holds for any update of form \(X_{t+1} = X_t + \epsilon(O_t - \lambda X_t)\), where the update \(O_t\) is bounded in any notion of norm.
Proposition 2
Consider any update of form \(X_{t+1} = X_t + \epsilon(O_t - \lambda X_t)\) with \(\mnorm{O_t}\leq b\) and \(\epsilon \lambda \leq 1\), where \(\mnorm{\cdot}\) is any notion of norm (such as \(\mnorm{\cdot}_\infty\)), and \(b\) is a constant. Then for we have
Hence, if the constraint \(\mnorm{X_{0}} \leq \frac{b}{\lambda}\) is satisfied, it will remain so after the update, although \(\mnorm{X_{0}}\) may increase toward the bound \(\frac{b}{\lambda}\). On the other hand, if the constraint is not initially satisfied (i.e., \(\mnorm{X_{0}} > \frac{b}{\lambda}\)), the magnitude of the violation, given by \(\mnorm{X_{0}} - \frac{b}{\lambda}\), will decrease at least geometrically.
Proof. The proof follows the same idea as the one for Proposition 1.
Applying this recursively yields the result.
Matrix Spectral Functions
We can take \(\mathcal{K}\) to be a general matrix spectral function. Let \(g\colon [0,\infty)\to\mathbb{R}\) be a scalar function. Then one may define
Because \(\frac{\partial \sigma_i(X)}{\partial X} = u_i v_i ^\top\), where \(u_i, v_i\) are the singular vectors associated with \(\sigma_i\), the derivative of \(\nabla\mathcal{K}(X)\) above is given by
where \({X}={U}\,{\Sigma}\,{V}\) is the SVD decomposition with \({\Sigma}=\operatorname{diag}\bigl(\{\sigma_i\}_i \bigr).\)
Assume \(g\) is upper bounded by \(b\), i.e., \(\sup_{x\geq 0}g(x) = b\), then the update \(O_t = \nabla \mathcal{K}(\tilde{{M}}_{t+1})\) satisfies \(\mnorm{O_t}_\infty \leq b\). This yields a constraint of \(\mnorm{X}_\infty \leq b/\lambda\) following Proposition 2.
In the practical implementation of Muon, \(g\) is effectively taken as a high order polynomial motivated with Newton-Schulz iteration for calculating the matrix sign.
Norm Constraints
More generally, the constrained optimization problem \(\min_X \mathcal{F}(X) \ \text{s.t.} \ X \in \mathcal{D}\), where \(\mathcal{D}\) is a convex set, can be solved using Lion-\(\mathcal{K}\) with \(\mathcal{K}^*(X) = \delta(X \in \mathcal{D})\). As in the cases of Lion and Muon, a particularly important instance is when \(\mathcal{D}\) is a norm ball, i.e., \(\mathcal{D} = \{X : \mnorm{X} \leq 1\}\) for some chosen norm \(\mnorm{\cdot}\). In this setting, \(\nabla \mathcal{K}(X)\) corresponds to the solution of a linear minimization oracle problem \(\max_Z \left\{ \langle X, Z \rangle \ \text{s.t.} \ \mnorm{Z} \leq 1 \right\}\). Related discussions can be found, for example, in [BN24] and [PXA+25].
References#
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: an optimizer for hidden layers in neural networks. 2024. URL: https://kellerjordan.github.io/posts/muon/.
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, and others. Muon is scalable for llm training. arXiv preprint arXiv:2502.16982, 2025.
Lizhang Chen, Bo Liu, Kaizhao Liang, and Qiang Liu. Lion secretly solves constrained optimization: as lyapunov predicts. arXiv preprint arXiv:2310.05898, 2023.
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, and Quoc V Le. Symbolic discovery of optimization algorithms. Advances in neural information processing systems, 36:49205–49233, 2023.
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: an anthology. arXiv preprint arXiv:2409.20325, 2024.
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and Volkan Cevher. Training deep learning models with norm-constrained lmos. arXiv preprint arXiv:2502.07529, 2025.
Chris J Maddison, Daniel Paulin, Yee Whye Teh, and Arnaud Doucet. Dual space preconditioning for gradient descent. SIAM Journal on Optimization, 31(1):991–1016, 2021.
Chris J Maddison, Daniel Paulin, Yee Whye Teh, Brendan O'Donoghue, and Arnaud Doucet. Hamiltonian descent methods. arXiv preprint arXiv:1809.05042, 2018.