This article appears in Automating Software Design: Interactive Design, Workshop Notes from the Ninth National Conference on Artificial Intelligence (AAAI-91), Anaheim, CA, July 15, 1991, pp. 138-145.
This research has been supported in part by the U.S. Army Research Office under contract DAAG29-84-K-0060. Computer equipment used in this research was donated by Hewlett Packard and Xerox.
In programming, as in other kinds of design, new designs are constructed in large part by reuse and adaptation of existing components. In software design, the primary components are data structures and algorithms. We describe systems that allow reuse of generic algorithms by compilation of the algorithms through views, which describe how application data structures implement the generic data structures in terms of which the algorithms are written. Views can be specified through interactive graphical and menu interaction with the programmer; this allows existing generic algorithms to be adapted easily and rapidly for an application.
In programming, as in other kinds of design, new designs are constructed in large part by reuse and adaptation of existing components. Computer Science education teaches students about standard data structures, such as linked lists and trees, and standard algorithms to manipulate these data structures, such as appending lists or depth-first traversal of a tree. In writing an application program, the programmer chooses data structures and algorithms appropriate to the application and recodes the algorithms in the chosen language to work with the data structures that have been designed. In effect, much of the work of programming is adaptation of standard algorithms for particular applications.
Automation of the reuse of standard algorithms [biggerstaff] for applications would substantially improve programming by:
In order to be effective in improving the production of software, we believe that a system for automated software design must meet the following criteria:
These desiderata may seem obvious; perhaps some are controversial. The major point is that the user interface of a successful software design system needs to be much simpler than existing programming languages. Automobiles provide a useful analogy: there many be great complexity under the hood, but the driver sees only a simple interface. A successful software design system must keep its complexity ``under the hood''.
In this section, we present a conceptual overview of a user interface for a software design system. Later sections describe the parts of this interface that have been implemented and describe how usable code is generated from the resulting specifications.
We view software design as being an incremental process, in which both data structures and programs are frequently modified as the design proceeds. We envision the programmer as having a workstation that maintains a collection of data types, views, and programs that can be individually modified.
Program development will start with design of data types. Application data often will involve many aspects of complex objects rather than being simple, well-defined mathematical data. The system will help with design of application data by allowing the desired data fields to be chosen from sets of typical data for common kinds of application objects. For example, a person has a single birthdate which is a date, a single social security number, an optional spouse who is a person, a (typically small) number of children who are persons, an address, employer, home and work phone numbers, etc. Data types for applications involving such data can be rapidly constructed by selecting from menus the parts of the standard description that are desired. Forms for data input, display, and editing can also be automatically constructed. Application data will often involve aspects of several kinds of data; for example, a car-loan record may involve aspects of person, loan, and car.
Larger data structures should be specifiable at multiple levels of abstraction. For example, a symbol-table involves an entry record that contains a symbol and a method of organization. It should be possible to change the method of organization without changing the entry record, or vice versa.
The programmer will specify multiple views of application objects as abstract objects. A view describes how an application type implements an abstract type; use of views in compilation is described later. Some views will describe data structures, e.g., a record may be a part of a linked-list; other views will relate data to application area abstractions, e.g., a car-loan may have a view as an asset of a bank.
A collection of programs, associated with the data structures, will be developed. Many of the programs will be derived from generic programs that have been compiled with respect to views of the application data, resulting in specialized versions of the generic programs that operate directly on the application data. Much of the program development process will be done by graphical and menu negotiation rather than entry of program text.
Dependency records will be maintained to indicate the dependencies of compiled generic program instances on application data types, other programs, etc. When a change is made that invalidates a specialized version of a generic program, automatic recompilation will produce a new version.
Parts of this programming system have been implemented. The following sections describe the GLISP compiler that is the basis of the system, views and clusters of related data types, how generic programs are compiled through views, and implemented parts of the user interface that allow fast and easy specification of programs using views.
GLISP [novak:glisp,novak:aaai83,novak:gluser,novak:sigplan83] is a high-level language with abstract data types that is compiled into Lisp. It allows the programmer to describe the actual data structure of an object, computed properties of the object, and operations that can be performed on it. Object classes can inherit properties and behavior from parent classes. Since objects and operations on them can be described separately from application code, programs can be written in terms of objects and operations on objects rather than in terms of the implementations of the objects.
Many features of GLISP are easily understood as extensions to object-oriented programming; run-time message sending is supported. The compiler keeps track of the types of objects at compile time and uses type inference to infer the types of derived objects. When the type of an object is known, the interpretation of an operation on the object can often be determined at compile time; compilation of a direct call to the corresponding function eliminates the overhead of message interpretation at runtime. Further, the operation can be open compiled, in effect macro-expanded in place, or compiled as a specialized closed function; this expansion is recursive at compile time and keeps track of object types. Recursive compilation allows a simple operation to undergo multiple levels of expansion, with parts of the expansion being drawn from different places and depending on the actual types of the objects involved. Symbolic optimization removes unnecessary code, performs conditional compilation, and combines operations where appropriate. Code inversion automatically inverts arithmetic expressions or other ways of deriving computed properties from existing data structures, allowing results to be stored back ``through messages'' when appropriate.
Data structures are a serious barrier to reuse in most languages: the form of program code often depends on the particular kind of data structure used, preventing reuse of the code for different data. We believe that any data representation and data structure should be able to be described and used within the programming system, and that the form of program code should not depend on the form of data; genuine reuse depends on meeting these conditions, since any assumptions made about the form of data will limit reuse to cases that satisfy those assumptions.
GLISP has a data description language that is sufficient for describing most data structures used in Lisp programs. This language has been extended to allow generic data structures (e.g. tuples and sets) to be described. It is also possible to define data types and operations that are outside Lisp, and thus it is possible to compile code for languages other than Lisp.
The syntax of GLISP allows stored and computed properties of objects to be referenced in the same manner; this has important implications for reuse:
The following examples illustrate how the same code can be used with data that are represented in different ways.
(circle (list (center vector) (radius real)) prop ( (area (pi * radius ^ 2)) ) ) (dcircle (cons (diameter real) (color symbol)) prop ( (radius (diameter / 2)) ) supers (circle))circle stores radius, while dcircle stores diameter in a different data structure; dcircle inherits properties such as area from circle. Stored and computed properties of objects are referenced in the same way in GLISP; the following examples show source and compiled code for similar functions on these different types:
(gldefun t1 (c:circle) (area c)) (LAMBDA (C) (* PI (EXPT (CADR C) 2))) (gldefun t2 (c:dcircle) (area c)) (LAMBDA (C) (* 0.7853982 (EXPT (CAR C) 2)))In example t2, the definition of area is inherited from circle and expanded; the reference to the radius is then expanded to be diameter / 2, and diameter becomes a data reference. Symbolic optimization folds the constants in the resulting code; open compilation combined with constant folding can result in substantial performance improvements [berlin-weise].
In order to reuse code, it must be possible not only to ``read'' data that is not represented directly, but also to to ``store into'' it; this is done by algebraic inversion:Properties into which one would want to ``store'' can generally be inverted automatically. If inversion is not possible or is ambiguous, an error message results.
(gldefun t3 (c:dcircle v:real) ((area c) := v) c) (LAMBDA (C V) (RPLACA C (* 1.128379 (SQRT V))) C)These techniques handle differences in data structures and in which kinds of data are represented; similar techniques also handle differences in units of measurement (e.g., use of fahrenheit or centigrade temperatures). It is also possible for application data to lack properties of the abstract data (e.g., it is possible to get the area of a circle whose center point is not defined) and to have additional properties defined.
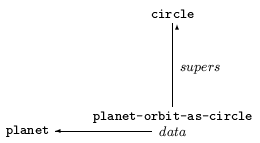
A view of an object describes how it can be viewed as an instance of an abstract type; [goguen] presented a proposal for views as a means of specifying programs. For example, the orbit of a planet might be viewed as a circle. It is not the case that a planet is a circle, so direct inheritance from circle is not an appropriate model. A view can be thought of as a class that mediates between an actual object type and an abstract type; the mediating class has the actual type as its stored implementation, the abstract type as a super-class, and properties that express the features required by the abstract type in terms of features of the actual type. We refer to such a class as a view class. The diagram below illustrates a view class, planet-orbit-as-circle, that has a planet as its stored representation and circle as a super-class; it describes how to obtain features required by circle, e.g. radius, from data available for a planet. Abstract algorithms defined for a circle can be obtained for a planet by compiling them through the view type, planet-orbit-as-circle. [novak:nipaper] describes this process in more detail.
Views such as this one can be described in a more compact form, e.g.,
(planet ...
views ((orbit circle
(radius (orbit-radius))) ))
Because views are separate from object types, it is possible to have multiple views of objects, including several different views as the same abstract type. For example, a planet could have views of its orbit as a circle, of the planet itself as a circle (e.g., to calculate how much solar radiation it intercepts), and of the planet as a sphere.
The GLISP compiler can specialize an abstract algorithm, written in terms of abstract data types, for particular data types that are instances of the abstract types. Specialization is done by compiling through view classes. When a property of an object is compiled through a view class, the definition of the property is expanded, either through open compilation or compilation of a specialized closed function, into code to access the corresponding property of the application data:
(gldefun t4 (p:planet) (area (orbit p))) (LAMBDA (P) (* PI (EXPT (GET P 'ORBIT-RADIUS) 2)))The expansion process keeps track of the types of the objects involved by means of type inference and is recursive at compile time. Recursive compilation can cause a small amount of source code to expand into a large amount of output code, drawn from multiple sources and depending on the types of the objects involved.
The recursive compilation process allows algorithms from separate sources to be combined, since a single property can expand into a combination of other properties that are defined in separate classes. For example, a priority queue can be defined as a composition of an indexing method that maps from an integer (the priority) to something (in this case, a queue), a queuing method that maintains a queue of things, and the type of records to be kept in the queue. There are many possible indexing methods (array, linked list, binary tree) and many possible queuing methods (simple linked list, linked list with end pointer, circular queue within an array). Any combination of these methods could be used to construct a priority queue, and any might be the method of choice for some application. By specifying the indexing method and queuing method for an application, generic routines defined for priority queues expand into the appropriate code for the methods selected.
We have developed libraries of generic programs for manipulating data structures such as linked lists, queues made from linked lists, priority queues, and trees. We have also developed sets of test data and functions that demonstrate the use of these generic programs on application data that are quite diverse implementations of the abstract types. Testing on ``perverse'' data structures verifies the robustness of the generic programs and data representations when it works, and often reveals where unwitting assumptions about the form of data have been made when it fails.
We have described views as being sets of connections between properties of an abstract type and corresponding properties of an application type. However, it is not easy to create correct views by hand. Doing so requires specifying all the needed properties of the abstract type and how they can be derived from the application type. In addition, for more complicated views, it is necessary to pay careful attention to result type declarations so that type inference will infer types at the correct level of abstraction. Clearly this is not something that application programmers should be expected to do.
We have developed user interfaces that allow views to be specified through an easily used graphical or menu negotiation process.
The GEV data inspector [novak:aaai83] allows simple looping programs to be constructed by menu selection. The user specifies by menu an operation to be performed during the loop (say, finding a TOTAL), a set of data over which to iterate, and a field within the set element data that is to be used in the operation (e.g., the data to be summed for the TOTAL). The user's menu selections are used to create a GLISP program that is compiled and run to provide the answer:

The process of finding the field to be used is a simple but important one. Starting from an application data type (e.g., a contract), the user specifies steps to be taken to derive data that satisfy a goal type (e.g., a number for input to the summation). This set of steps can be viewed as a path down a tree of data types, whose root is the application data type. At each node, the choices available are the stored and computed data that are defined for the type at that node; these are presented to the user as a menu. When the user finally selects an item whose type matches the goal type, the search terminates; the result is the list of field or property names that specify the path from the application type to the goal. The sets of possibilities that are presented to the user can be filtered using knowledge of the goal type, reducing the number of choices the user has to read.
Extensions to this basic process are used in the interfaces described below. As a user interface, this process is fast and easy to use; it is suitable even for non-technical users who understand the structure of their data.
Use of a pre-written library program typically requires that an interface program be written to reformat the existing application data into the form expected by the library program. Man-Lee Wan has written a program, LINK [wan,novak:nipaper], that automates this process. It is assumed that the application data type has been defined using the GLISP data description language; the library program is likewise assumed to have a description of its required data. From these two descriptions, LINK conducts a menu-based negotiation to determine how the requirements of the program can be satisfied by the user data. The required data are satisfied recursively:
For example, a program that draws a pie chart might expect as input a list of pairs, where each pair consists of a label for a slice of the pie and a number representing the size of the slice. The user could specify that, from a set of data representing divisions of a company, a pie chart is desired where the label of each pie slice is the name of the division and the size corresponds to net profit of the division. From these specifications, LINK produces an interface program that reads and filters the given data set and produces output in the proper format, then calls the program with this data set.
Reuse by copying and reformatting data is an efficient method when the data sets are small or where the interfaces cannot be modified, e.g. where the interface is defined by hardware or is a remote server over a network. A similar process may be required to reformat the results returned by the called program. The process we have described does not handle recursive graph structures; see [lamb,herlihy].
Another way of reusing existing programs for a given data type is to rewrite a generic program, by compilation through view classes, to work directly with the application data. However, making view classes to allow a generic program to be specialized is difficult. Fredrick Hill has written a program [hill,novak:nipaper] that allows a view class to be constructed automatically from specifications of how application data match the abstract data required by the algorithm; these specifications are acquired through a menu-based negotiation process similar to that described above. Following the negotiation process, the generic algorithm is compiled using the view class, which results in a version of the algorithm that is specialized for the user's data.
Hill used as an example a generic program for drawing a diagram of a tree structure. In the negotiation process, the user specifies the data type that is the node of a tree, how to tell whether a node is terminal, how to get the children of a node, and what printed representation is desired for a node. The result is a specialized algorithm to draw the user's tree in the desired fashion. A given tree can be drawn in various ways; Figure 1 shows a family tree drawn to show only the females [empty boxes represent unmarried males]. Figure 2 shows an integer drawn as a tree; successors are obtained by dividing the bits in the binary representation of the integer into left and right halves until a single bit or a value of zero is reached. These examples illustrate how the same generic algorithm can be automatically recompiled to operate on quite different data.
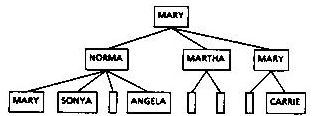
Fig. 1: A Family Tree Showing Only Females
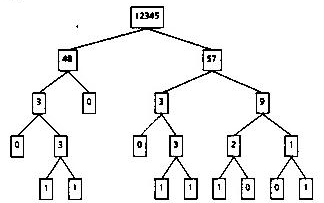
Fig. 2: An Integer Viewed as a Tree
Hill's work demonstrates the power of this technique: several pages of specialized Lisp code can be produced in a few seconds. However, his program considers only a single main data type and a program that deals with that type. There is a need to expand these capabilities to deal with multiple types and composed programs.
We have implemented an alternative user interface that allows views to be specified graphically by connecting corresponding properties of source types and goal types. The components of each type are expanded and drawn as stacks of boxes in a window. The user can connect a required property with the application data that satisfies it by clicking on each box; a line is then drawn connecting the two on the display. Expressions can also be specified using operation menus.
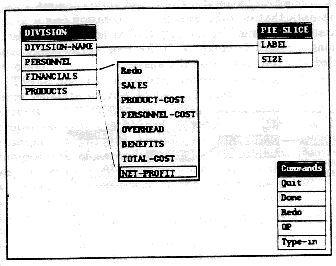
Fig. 3: Graphical Connection Interface
While this interface is conceptually similar to the menu interfaces described earlier, it has several advantages:
In general, programs deal with multiple types that are related; we call a set of related types, functions, and other information a cluster, using the terminology of CLU [liskov]. We have developed techniques for describing a cluster of related abstract types, and also for representing cluster views, i.e., extending the view mechanisms described earlier so that a cluster of related application types can be viewed as a corresponding cluster of abstract types. It is necessary to have such a mechanism because a generic routine associated with one type must sometimes refer to a related type within the cluster.
A simple example of a cluster is a linked-list. An abstract linked-list consists of a record type and a pointer type; a record contains a link field that is a pointer and a contents that is arbitrary; a pointer either is null or denotes a record.
Although one could attempt to use only a single type to represent a linked list (presumably the record type, with the pointer being the ``standard'' pointer to the record type defined for the language), it is actually necessary to make both types part of the cluster in order to achieve true representation independence. In general, a pointer must be a type in its own right. A typical pointer is the address of a data structure in main memory; however, a pointer could also be represented by an index into an array, or a disk address, or a structured data type such as a pair (row, column) on a chess board.
We have implemented an experimental system, called VIEWAS, that will automatically or semi-automatically make a view of user types as matching an abstract type cluster. All of the generic algorithms defined for the abstract cluster are then available for the user type by automatic specialization.
VIEWAS operates by matching a cluster specification to the specified application types to create a cluster view, i.e., a set of view types that have the abstract cluster types as superclasses and are related to each other in a way that is isomorphic to the relations in the abstract cluster. The matching process is automatic when it is unambiguous and asks the user to specify choices by menu where multiple possibilities exist.
A simple example is viewing a user record as a linked list. The cluster for a linked list consists of a record type and a pointer type. The user-specified record matches the linked-list record. The type of the pointer to the user-specified record can usually be inferred. The abstract description of a linked-list record is that it contains a link, whose type is the pointer type, and contents. If the record has only one field whose type matches the pointer type, it is automatically inferred to be the link; if there are multiple possibilities, the user is asked to choose one by menu. For example, a person might have fields mother, father, and best-friend, each of which is a person; any of these could be used in a linked-list view. The contents of the record is defined in the specification as everything in the record except the link; this is needed for operations such as copying a list.
Once VIEWAS has produced a view of the user object as a linked list, all of the usual linked list functions are available for the user type by automatic specialization of generic library functions. As an example, consider a ``backwards'' linked list in Lisp, which we call bl. bl has as a record a cons cell, with the link in the car part of the cell and the value in the cdr part:
(bl (cons (nxt (^ bl))
(val integer))
viewspecs ((ext-linked-list)))
The viewspecs property specifies that bl is thought of as
being an external-linked-list; this will cause VIEWAS to be called to
make a view for it automatically when needed. In this case, VIEWAS
will work automatically, since there is only one candidate for the
link field of this linked list.
Given this short specification for bl, library functions defined for linked lists can be invoked, causing specialized versions of the library functions to be compiled as needed. For example, the following function invokes the library nreverse function:
(gldefun t5 (b:bl) (nreverse (ext-linked-list b))) (LAMBDA (B) (NREVERSE-1 B))NREVERSE-1 is the specialized version of the library nreverse function that is compiled automatically when the referencing function t5 is compiled or used:
(setq mybl
'(((((NIL . 5) . 4) . 3) . 2) . 1) )
(t5 mybl)
= (((((NIL . 1) . 2) . 3) . 4) . 5)
The generic library function nreverse is shown below, followed by the specialized compiled version, NREVERSE-1 :
(gldefun generic-nreverse
(l:linked-list-pointer)
(result (typeof l))
(let (prev next)
(prev := (null-value l))
(while l is not null do
(next := (rest l))
((rest l) := prev)
(prev := l)
(l := next))
prev))
(LAMBDA (L)
(LET (PREV NEXT)
(SETQ PREV NIL)
(TAGBODY GLLABEL1701
(WHEN L (SETQ NEXT (CAR L))
(RPLACA L PREV)
(SETQ PREV L)
(SETQ L NEXT)
(GO GLLABEL1701)))
PREV))
Although this is a relatively small function, a human programmer
would probably need to spend several minutes to write and debug it;
the amount of work required to invoke it from the library is minimal.
The compiled code illustrates the efficiency of our techniques, since
the reverse-in-place function is performed directly on the application
data.
Views of user data as more complex abstract types can also be handled. A sorted linked list is a linked list plus a specification of a field to sort on and a sort direction. A queue can be built from a linked list (in several ways) by keeping the appropriate pointers. A priority queue can be built from a method for keeping queues. The user can request a view at a higher level, e.g. a priority queue of application records. The system will ask the user to specify the type of queue desired, the type of the sequence of queues, and the size; it will also create subordinate views, such as a linked-list view needed for the queue. From these specifications, the necessary clusters of view types will be created to allow the routines associated with priority queues to be specialized automatically.
We plan to continue development of improved methods for specifying clusters of types at the abstract level and more easily used ways of invoking and parameterizing a cluster. It appears that expert systems could assist in many of the choices of data structures; the preferred implementation(s) could be presented to the programmer for confirmation or choice, and ``obvious'' choices could be made automatically. Many of the choices to be made involve performance tradeoffs rather than correctness, so it is safe to allow an expert system to make them [kant].
The specifications and restrictions associated with cluster parameters are very important. They can be used to ensure that a parameter meets the conditions for its correct use. They can also be used for filtering choices presented to the user. For example, the children slot of a tree-node must be filled by something whose type is a sequence of the tree-node type; often there will be only one possibility, which can be chosen automatically.
Wherever possible, we treat failure to meet specifications not as an error, but as a subproblem that remains to be solved; in many cases, the nature of the failure can allow the system to help the user to solve it. For example, suppose that the user describes a sorted linked list of person records, but that no comparison predicate for two persons exists. The system could then help the user to create such a predicate by choosing a field on which to sort and a direction for sorting or by allowing construction of a comparison function, either as an expression or by presenting a function skeleton to be filled in. In most cases, a few mouse clicks (e.g., choosing to sort ascending on name) will be all that is needed. By such techniques, reasoning about the program being constructed can have the effect of making programming easier, while retaining correctness.
We have described methods for automating production of executable program code by specialization of generic programs through views. We also described methods to allow views to be easily specified by graphical and menu interaction with the programmer. Initial versions of these have been implemented and tested; they allow programs to be created rapidly and easily. We plan to extend these methods toward the goal of a comprehensive programming system.
[barstow:psi] Barstow, David 1984. A Perspective on Automatic Programming, A.I. Magazine, 5(1):5-27.
[berlin-weise] Berlin, A. and Weise, D. 1990. Compiling Scientific Code Using Partial Evaluation, IEEE Computer 24(12):25-37.
[biggerstaff] Biggerstaff, Ted J. and Perlis, Alan J. 1989. Software Reusability. ACM Press / Addison-Wesley.
[goguen] Goguen, Joseph 1986. Reusing and Interconnecting Software Components. IEEE Computer 19(2):16-28.
[herlihy] Herlihy, M. and Liskov, B. 1982. A Value Transmission Method for Abstract Data Types. ACM Trans. on Programming Languages and Systems 4(4):527-551.
[hill] Hill, Fredrick N. 1985. Negotiated Interfaces for Software Reusability. Technical Report AI-85-16, C.S. Dept., University of Texas at Austin.
[kant] Kant, Elaine 1983. On the Efficient Synthesis of Efficient Programs. Artificial Intelligence 20:253-306.
[lamb] Lamb, David A. 1983. Sharing Intermediate Representations: The Interface Description Language. Technical Report CMU-CS-83 129, C.S. Dept., Carnegie-Mellon University.
[liskov] Liskov, Barbara et al. 1981. CLU Reference Manual. Springer-Verlag.
[novak:nipaper] Novak, G. and Hill, F. and Wan, M. and Sayrs, B. 1991. Negotiated Interfaces for Software Reuse. Submitted to IEEE Trans. on Software Engineering.
[novak:gluser] Novak, Gordon S. 1982. GLISP User's Manual. Technical Report STAN-CS-82-895, C.S. Dept., Stanford University.
[novak:sigplan83] Novak, Gordon S. 1983. Data Abstraction in GLISP. ACM SIGPLAN Notices 18(3).
[novak:glisp] Novak, Gordon S. 1983. GLISP: A LISP-Based Programming System With Data Abstraction. AI Magazine 4(3):37-47.
[novak:aaai83] Novak, Gordon S. 1983. Knowledge Based Programming Using Abstract Data Types. In Proc. National Conference on Artificial Intelligence.
[wan] Wan, Man-Lee 1985. Menu-Based Creation of Procedures for Display of Data. Technical Report AI-85-18, C.S. Dept., University of Texas at Austin. }