
Unit 4.3.1 Lots of loops to parallelize
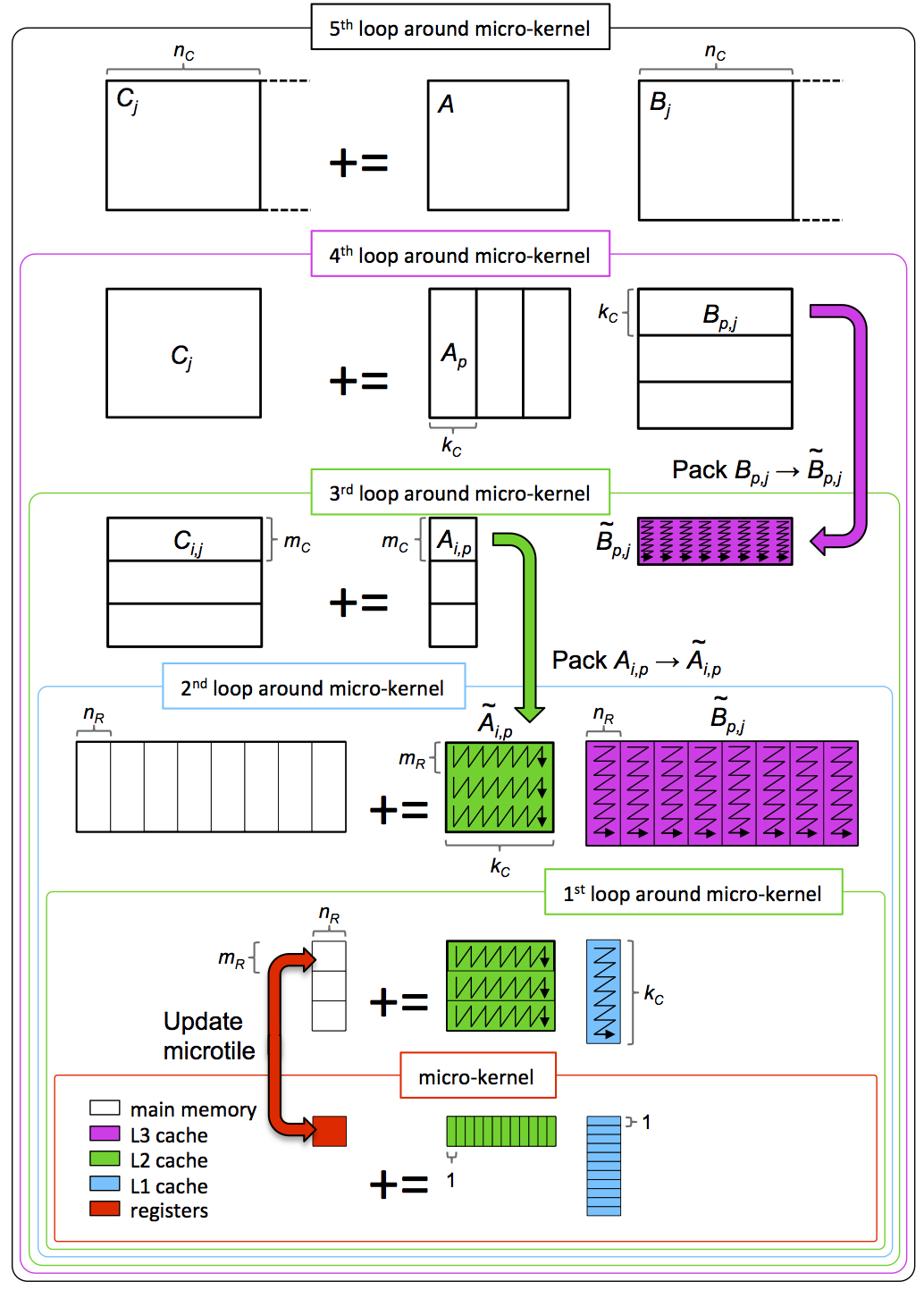
¶Let's again consider the five loops around the micro-kernel:
Homework 4.3.1.1.
In directory Assignments/Week4/C, execute
export OMP_NUM_THREADS=1 make Five_Loops_Packed_8x6Kernelto collect fresh performance data. In the Makefile, MC and KC have been set to values that yield reasonable performance in our experience. Transfer the resulting output file (in subdirectory data) to Matlab Online Matlab Online and test it by running
Plot_MT_Performance_8x6.mlxIf you decide also to test a 12x4 kernel or others, upload their data and run the corresponding Plot_MT_Performance_??x??.mlx to see the results. (If the .mlx file for your choice of \(m_R \times n_R \) does not exist, you may want to copy one of the existing .mlx files and do a global search and replace.)
Solution
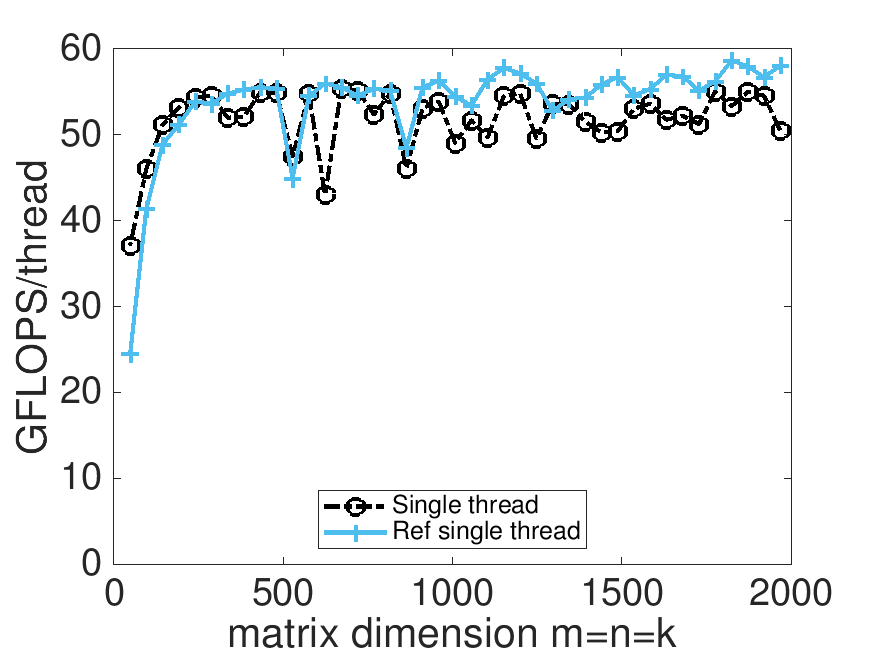 This reminds us: we are doing really well on a single core!
This reminds us: we are doing really well on a single core!
On Robert's laptop:
Remark 4.3.1.
Here and in future homework, you can substitute 12x4 for 8x6 if you prefer that size of micro-tile.
Remark 4.3.2.
It is at this point in my in-class course that I emphasize that one should be careful not to pronounce "parallelize" as "paralyze." You will notice that sometimes if you naively parallelize your code, you actually end up paralyzing it...