
Unit 4.5.4 Matrix-matrix multiplication on GPUs
¶Matrix-matrix multiplications are often offloaded to GPU accellerators due to their cost-effective performance achieved with low power consumption. While we don't target GPUs with the implementations explored in this course, the basic principles that you now know how to apply when programming CPUs also apply to the implementation of matrix-matrix multiplication on GPUs.
The recent CUDA Templates for Linear Algebra Subroutines (CUTLASS) [16] from NVIDIA expose how to achieve high-performance matrix-matrix multiplication on NVIDIA GPUs, coded in C++.

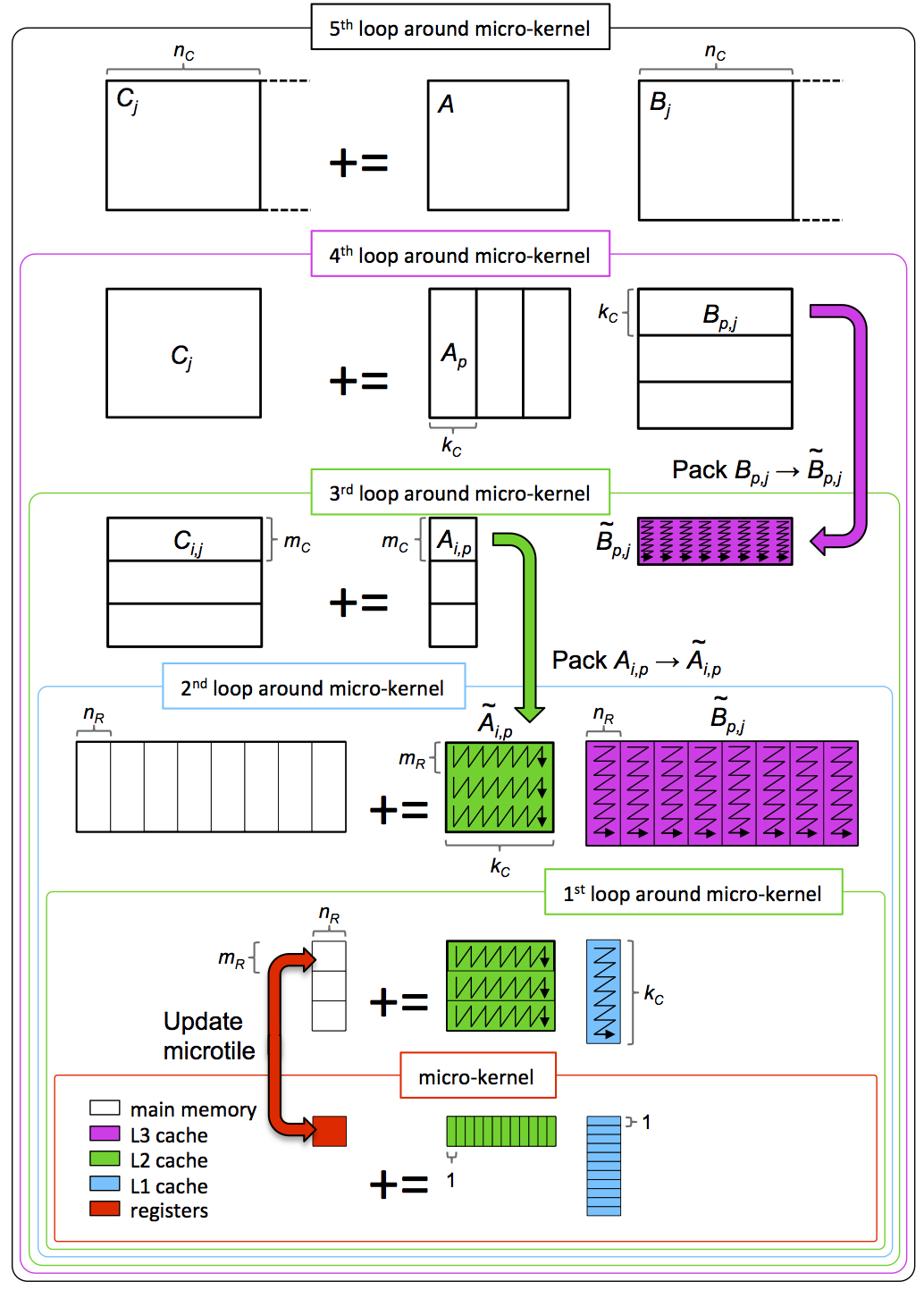
The explanation in [16] is captured in Figure 4.5.4, taken from [13]
Jianyu Huang, Chenhan D. Yu, and Robert A. van de Geijn, Strassen’s Algorithm Reloaded on GPUs, ACM Transactions on Mathematics Software, in review.