Imagine yourself again as the agent in this setup. Suppose that you have a very important match to play tomorrow and in your diligent way, you decide to learn for a single ball position whether it is best to pass or to shoot. You convince your teammate to come and stand in the place where you plan to pass, and then you convince your goalie to start in several different positions for two attempts: one shot and one pass. Of course the goalie will move to try to block the ball, but being a consistent goalie, you know that she will always move in the same way. Therefore you need only try shooting and passing once for each starting position. After a short amount of time, you have learned perfectly whether you should shoot or pass when the goalie is in a given position (with only a little error due to the necessity of rounding the goalie's position to the nearest position used for training).
The next day you turn up at the big game confident that if the ball is in your chosen spot, you will be able to choose correctly whether to shoot or to pass. You know that the opposing goalie is just as consistent as your own, so you believe that everything you learned yesterday should apply. But alas, your first attempt at a shot--one that you were sure would score--is blocked by the opposing goalie. What happened? The goalie's behavior is still deterministic, but it has changed completely: the new goalie is slower than your own. If you keep acting based on your experiences in practice, you are not going to score much, so you had better start adapting your memory to the current situation.
The memory-based technique we have been using so far works well when
the defender's motion is deterministic and remains unchanged over
time. However, if some noise is added to the defender's motion or if
the defender changes its speed over time, then we need to use a more
powerful technique. The technique we have used to this point
converges monotonically since it assumes that once ![]() has
been learned perfectly at a memory location, then
has
been learned perfectly at a memory location, then ![]() need never
change. If there is a training example
need never
change. If there is a training example ![]() , then no
number of nearby conflicting examples
, then no
number of nearby conflicting examples ![]() will
alter the value in Mem[
will
alter the value in Mem[ ![]() ].
].
In our current scenario, memory needs to be able to adapt in
response to new conflicting examples. In order to accommodate this
requirement, we change our method of storing experiences to memory.
We continue to scale the result of an experience ![]() stored
to Mem[
stored
to Mem[ ![]() ] by
] by ![]() , but rather than only storing the
result of the experience with
, but rather than only storing the
result of the experience with ![]() closest to
closest to ![]() , we now let
each experience with
, we now let
each experience with ![]() affect Mem[
affect Mem[ ![]() ] in proportion to the distance
] in proportion to the distance ![]() .
In particular, Mem[
.
In particular, Mem[ ![]() ] keeps running sums of the magnitudes of
scaled results, Mem[
] keeps running sums of the magnitudes of
scaled results, Mem[ ![]() ].total-a-results, and of scaled
positive results, Mem[
].total-a-results, and of scaled
positive results, Mem[ ![]() ].positive-a-results, affecting
].positive-a-results, affecting
![]() , where ``a'' stands for ``s'' or ``p'' as before. Then
at any given time,
, where ``a'' stands for ``s'' or ``p'' as before. Then
at any given time, ![]() . The ``-1'' is for the
lower bound of our probability range, and the ``
. The ``-1'' is for the
lower bound of our probability range, and the `` ![]() '' is to scale the
result to this range. Call this our adaptive memory storage
technique:
'' is to scale the
result to this range. Call this our adaptive memory storage
technique:

For example, ![]() would set both
total-p-results and positive-p-results for Mem[120] (and
Mem[100]) to 0.5 and consequently
would set both
total-p-results and positive-p-results for Mem[120] (and
Mem[100]) to 0.5 and consequently ![]() (and
(and ![]() ) to 1.0.
But then
) to 1.0.
But then ![]() would increment total-p-results for
Mem[120] by .75, while leaving positive-p-results unchanged.
Thus
would increment total-p-results for
Mem[120] by .75, while leaving positive-p-results unchanged.
Thus ![]() becomes
becomes ![]() .
.
This method of storing to memory is effective both for time-varying concepts and for concepts involving random noise. It performs better than the basic memory storage technique described earlier because it is able to deal with conflicting examples within the range of the same memory slot.
Figure 3 demonstrates the effectiveness of adaptive memory when the defender's speed changes.
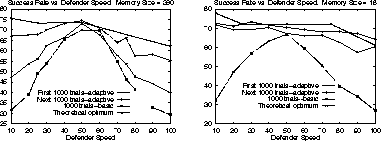
Figure 3: For all trials shown in these graphs, the agent began with a
memory trained for a defender moving at constant speed 50. Adaptive
memory outperforms basic memory for memories of size both 360 (left)
and 18 (right). Since the basic memory does not change over time,
the next 1000 trials produced the same results as the first 1000, and
therefore are not plotted.
In all of the experiments represented in these graphs, the agent
started with a memory trained by attempting a single pass and a single
shot with the defender starting at each position ![]() for which
Mem[
for which
Mem[ ![]() ] is defined and moving in its circle at
speed 50. We tested the agent's performance with the defender moving
at various (constant) speeds.
] is defined and moving in its circle at
speed 50. We tested the agent's performance with the defender moving
at various (constant) speeds.
Notice that in both graphs of Figure 3, basic memory causes
performance to degrade as the defender's speed moves farther from 50.
At the extremes, performance even becomes worse than random action,
which leads to roughly a 40% success rate. In contrast, with
adaptive memory, the agent is able to unlearn the training that no
longer applies and approach optimal behavior: it re-learns the
new setup. During the first 1000 trials the agent suffers from having
practiced in a different situation (especially for the less
generalized memory, M = 360), but then it is able to approach
optimal behavior over the next 1000 trials. Remember that optimal
behavior, represented in the graph, leads to roughly a 70% success
rate, since at many starting positions, neither passing nor shooting
is successful. As in Table 1, we can see that the smaller
memory converges to ![]() more quickly than does the larger memory.
more quickly than does the larger memory.
From these results we conclude that our adaptive memory can effectively deal with time-varying concepts. It can also perform well when the defender's motion is nondeterministic, as we show next.