Once able to judge the likelihood that a pass will succeed, a real or simulated soccer player is ready to start making decisions in game-like situations. When considering what to do with the ball, the player can pass to a strategically positioned teammate, dribble, or shoot. To verify that the second level of learning could be incorporated into game-like situations, we implemented a set play that uses the passing decision described in the previous section.
As illustrated in Figure 15, a player starts with the ball in front of it and dribbles towards the opponent's goal. When it notices that there is an opponent in its path, it then decides to stop dribbling and considers its options. Noticing that it is too far away to shoot and that dribbling forward is no longer an option, it decides to pass. Thus, in accordance with the sequence laid out in the previous section, it announces its intention to pass and gets responses from the two nearest players. It then uses the DT to decide which teammate is the more likely to successfully receive the pass.
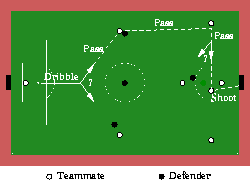
Figure 15: An illustration of the implemented set play. Players are
emphasized for improved visibility. Every player uses at least one of
the learned skills described earlier in the article.
In Figure 15, the passer chooses the topmost receiver and passes the ball. The receiver and the adjacent defender then both try to intercept the ball using the trained NN ball-interception skill. If the defender gets the ball, it kicks it back towards the left goal and the play starts over. However, if the receiver gets the ball, it immediately kicks the ball to its teammate on the wing. Since the winger is not covered, it can easily collect the ball and begin dribbling towards the goal. Using the same behavior as its teammate that began the set play, the winger notices defenders in its path and decides that it is not at a good angle to shoot. So rather than shooting or dribbling, it uses the trained DT to choose one of the two nearby teammates to pass to. If the chosen receiver is able to get to the ball before the defenders, it immediately shoots towards the goal.
We ran this set play several times in order to verify that the learned behaviors are both robust and reliable. Since the defenders are all equipped with the same ball-interception skill as the receivers, the defenders are sometimes able to break up the play. However, the fact that the attacking team can sometimes successfully string together three passes and a shot on goal when using the learned behaviors demonstrates that these behaviors are appropriate for game-like situations. Furthermore, this implemented set play suggests a number of possibilities for the next layer of learning.
In the set play described above, the player that starts with the ball dribbles until it sees an opponent at a predetermined distance. This distance was chosen so as to allow the player to pass without the central opponent taking the ball. However, a more flexible and powerful approach would be to allow the dribbling player to learn when to continue dribbling, when to pass, and when to shoot. With these three possibilities as the action space and with appropriate predicates to discretize the state space, TD-lambda and other reinforcement learning methods will be applicable. By keeping track of whether an opponent or a teammate possesses the ball next, a player can propagate reinforcement values for each decision made while it possesses the ball.
Another candidate for the next layer of learned behavior is on the part of the receivers. When it appears that a teammate might be getting ready to pass (or when a teammate directly communicates that it is), a player that might be able to receive the pass could learn to move into a better position. In the current implementation of the set play, as in the DT learning phase, the passer chooses a receiver from among stationary teammates. However, if the receivers are given the goal of being chosen as the receiver as often as possible, they can learn a moving behavior that is built upon the learned passing DT. In effect, they will learn to satisfy the preconditions of a successful pass.
Finally, the next level of learning could be the one that introduces adversarial issues. In addition to learning to cooperate with teammates, players can learn to thwart the opponents. For example, the counterpart to the receivers learning to move to receive a pass is to have the defenders learn to move so as to prevent a pass. However, this defensive behavior could potentially become even more complex if the defender is given the goal of actually intercepting a pass, rather than simply preventing it. Then the defender's optimal behavior would be to move to a position such that the passer thinks that the pass will succeed, yet such that the defender is still able to intercept the ball.
Once adversarial behaviors are introduced, some additional issues must be considered. First, if the adversaries are allowed to continually adjust to each other, they may evolve increasingly complex behaviors with no net advantage to either side. This potential stumbling block in competitive coevolution has been identified and addressed by several researchers who work with genetic algorithms [6, 7, 15]. Second, since a robotic soccer team must be able to play against many different opponents, often for only a single match, it must be able to adapt quickly to opponent behaviors without permanently harming performance against other opponents. We anticipate addressing these and other adversarial learning issues while continuing to build our soccer playing agents.
As we move to higher-level behaviors, we will continue to consider a wide range of learning methods. In addition to NNs and DTs, we are hoping to test TD-lambda and genetic type learning methods. Continuing to build one learned layer at a time, we aim to eventually reach team-level strategies that consider the perceived strategies of opponents.