of an unshifted QR algorithm can be staged as the computation and application of a sequence of Givens' rotations. Obviously, one could explicitly form \(A^{(k)} - \mu_k
I \text{,}\) perform these computations with the resulting matrix, and then add \(\mu_k I \) to the result to compute
\begin{equation*}
\begin{array}{l}
A^{(k)} - \mu_k I \rightarrow Q^{(k)}
R^{(k)} \\
A^{(k+1)} \becomes R^{(k)} Q^{(k)} + \mu_k I .
\end{array}
\end{equation*}
The Francis QR Step combines these separate steps into a single one, in the process casting all computations in terms of unitary similarity transformations, which ensures numerical stability.
The first Givens' rotation is computed from \(\left(
\begin{array}{c}
\alpha_{0,0} - \mu\\
\alpha_{1,0}
\end{array}
\right)
\text{,}\) yielding \(\gamma_{1,0} \) and \(\sigma_{1,0} \) so that
has a zero second entry. Now, to preserve eigenvalues, any orthogonal matrix that is applied from the left must also have its transpose applied from the right. Let us compute
Next, from \(\left(
\begin{array}{c}
\widehat{\alpha}_{1,0} \\
\widehat{\alpha}_{2,0}
\end{array}
\right),\) one can compute \(\gamma_{2,0} \) and \(\sigma_{2,0} \) so that
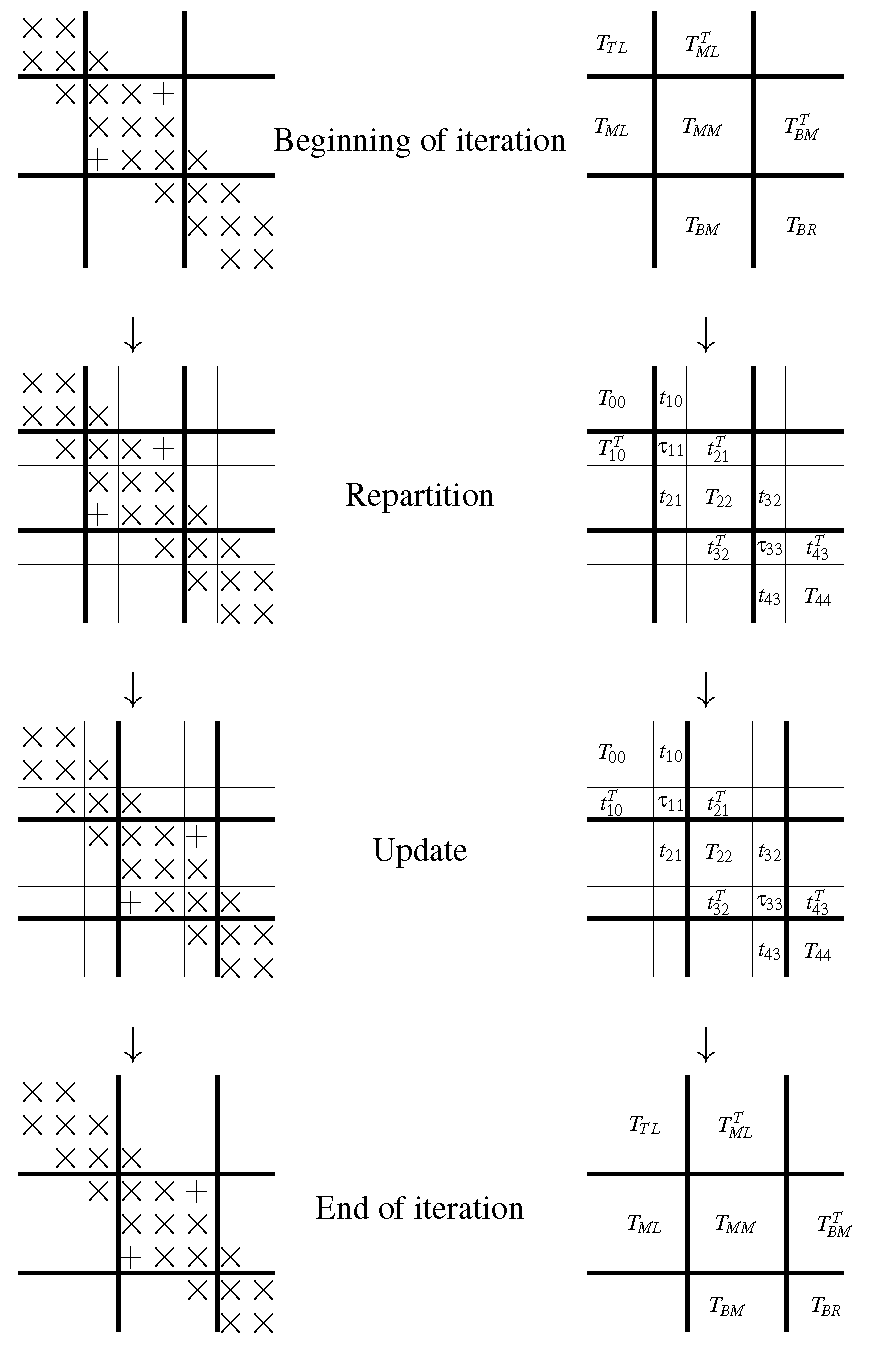
yielding a tridiagonal matrix. The process of transforming the matrix that results from introducing the bulge (the nonzero element \(\widehat \alpha_{2,0}\)) back into a tridiagonal matrix is commonly referred to as "chasing the bulge." Moving the bulge one row and column down the matrix is illustrated in Figure 10.3.5.1. The process of determining the first Givens' rotation, introducing the bulge, and chasing the bulge is know as a Francis Implicit QR step. An algorithhm for this is given in Figure 10.3.5.2.
Figure10.3.5.1. Illustration of how the bulge is chased one row and column forward in the matrix.
\begin{equation*}
% Define the operation to be computed
\newcommand{\routinename}{ T \becomes \mbox{ChaseBulge}( T )}
% Step 3: Loop-guard
\newcommand{\guard}{
m( T_{BR} ) > 0
}
% Step 8: Insert the updates required to change the
% state from that given in Step 6 to that given in Step 7
% Note: The below needs editing!!!
\newcommand{\update}{
\begin{array}{l}
\mbox{Compute } ( \gamma,\sigma ) \mbox{ s.t. } G_{\gamma, \sigma}^T t_{21} =
\left(
\begin{array}{c}
\tau_{21} \\
0
\end{array}
\right), \mbox{ and assign }
t_{21} := \left( \begin{array}{c} \tau_{21} \\ 0 \end{array} \right) \\
T_{22} := G_{\gamma, \sigma}^T T_{22} G_{\gamma, \sigma} \\[2mm]
t_{32}^T := t_{32}^T G_{\gamma, \sigma}
{\rm ~~~~~~(not~performed~during~final~step)}\\
\end{array}
}
% Step 4: Redefine Initialize
\newcommand{\partitionings}{
T \rightarrow
\left( \begin{array}{ c | c | c }
T_{TL} \amp \star \amp \star \\ \hline
T_{ML} \amp T_{MM} \amp \star \\ \hline
0 \amp T_{BM} \amp T_{BR}
\end{array} \right)
}
\newcommand{\partitionsizes}{
T_{TL} \mbox{ is } 0 \times 0 \mbox{ and } T_{MM} \mbox{ is } 3 \times 3
}
% Step 5a: Repartition the operands
\newcommand{\repartitionings}{
\left( \begin{array}{ c | c | c }
T_{TL} \amp \star \amp 0 \\ \hline
T_{ML} \amp T_{MM} \amp \star \\ \hline
0 \amp T_{BM} \amp T_{BR}
\end{array} \right)
\rightarrow
\left( \begin{array}{ c | c c | c c }
T_{00} \amp \star \amp 0 \amp 0 \amp 0 \\ \hline
t_{10}^T \amp \tau_{11} \amp \star \amp 0 \amp 0 \\
0 \amp t_{21} \amp T_{22} \amp \star \amp 0 \\ \hline
0 \amp 0 \amp t_{32}^T \amp \tau_{33} \amp \star \\
0 \amp 0 \amp 0 \amp t_{43} \amp T_{44}
\end{array} \right)
}
\newcommand{\repartitionsizes}{
\tau_{11} \mbox{ and } \tau_{33} \mbox{ are scalars} \\
\mbox{(during final step,} \tau_{33} \mbox{ is } 0 \times 0 \mbox{)}
}
% Step 5b: Move the double lines
\newcommand{\moveboundaries}{
\left( \begin{array}{ c | c | c }
T_{TL} \amp \star \amp 0 \\ \hline
T_{ML} \amp T_{MM} \amp \star \\ \hline
0 \amp T_{BM} \amp T_{BR}
\end{array} \right)
\leftarrow
\left( \begin{array}{ c c | c c | c }
T_{00} \amp \star \amp 0 \amp 0 \amp 0 \\
t_{10}^T \amp \tau_{11} \amp \star \amp 0 \amp 0 \\ \hline
0 \amp t_{21} \amp T_{22} \amp \star \amp 0 \\
0 \amp 0 \amp t_{32}^T \amp \tau_{33} \amp \star \\ \hline
0 \amp 0 \amp 0 \amp t_{43} \amp T_{44}
\end{array} \right)
}
\FlaAlgorithm
\end{equation*}
Figure10.3.5.2. Algorithm for "chasing the bulge" that, given a tridiagonal matrix with an additional nonzero \(\alpha_{2,0}\) element, reduces the given matrix back to a tridiagonal matrix.
The described process has the net result of updating \(A^{(k+1)} = Q^T A^{(k)} Q^{(k)} \text{,}\) where \(Q \) is the orthogonal matrix that results from multiplying the different Givens' rotations together:
is exactly the same first column had \(Q \) been computed as in Subsection 10.3.3(10.3.1). Thus, by the Implicit Q Theorem, the tridiagonal matrix that results from this approach is equal to the tridiagonal matrix that would be computed by applying the QR factorization from that section to \(A - \mu I \text{,}\) \(A - \mu I \rightarrow QR \) followed by the formation of \(R Q + \mu I \) using the algorithm for computing \(R Q \) in Subsection 10.3.3.
Remark10.3.5.3.
In Figure 10.3.5.2, we use a variation of the notation we have encountered when presenting many of our algorithms, n including most recently the reduction to tridiagonal form. The fact is that when implementing the implicitly shifted QR algorithm, it is best to do so by explicitly indexing into the matrix. This tridiagonal matrix is typically stored as just two vectors: one for the diagonal and one for the subdiagonal.
Homework10.3.5.1.
A typical step when "chasing the bulge" one row and column further down the matrix involves the computation
Since the subscripts will drive us crazy, let's relabel, add one of the entries above the diagonal, and drop the subscripts on \(\gamma \) and \(\sigma \text{:}\)