
Unit 3.3.5 Implementation: five loops around the micro-kernel, with packing
¶
Below we illustrate how packing is incorporated into the "Five loops around the micro-kernel".
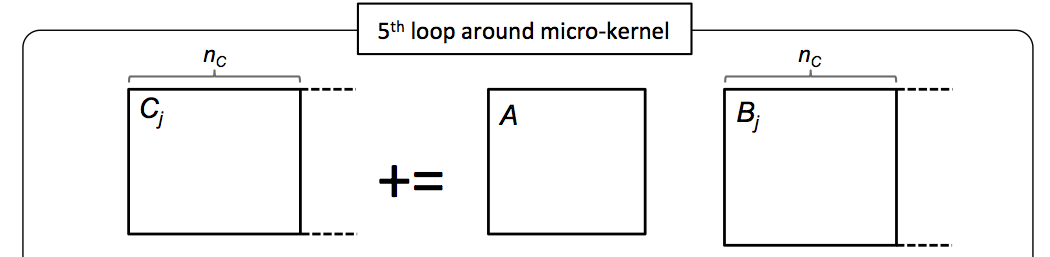
void LoopFive( int m, int n, int k, double *A, int ldA,
double *B, int ldB, double *C, int ldC )
{
for ( int j=0; j<n; j+=NC ) {
int jb = min( NC, n-j ); /* Last loop may not involve a full block */
LoopFour( m, jb, k, A, ldA, &beta( 0,j ), ldB, &gamma( 0,j ), ldC );
}
}
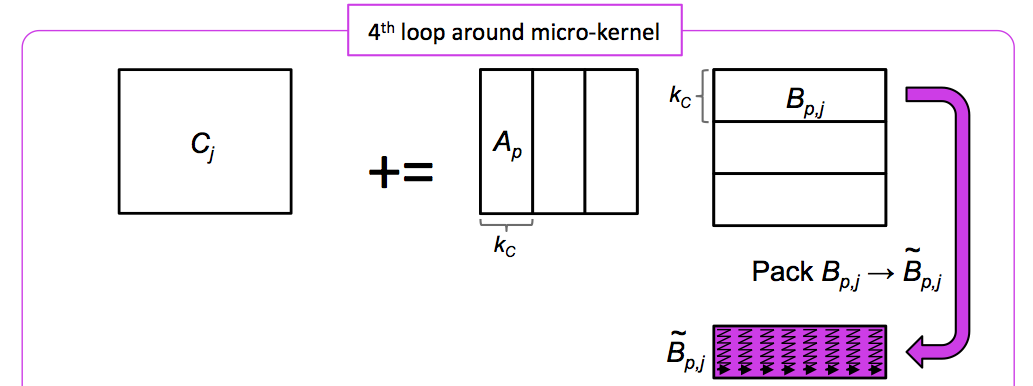
void LoopFour( int m, int n, int k, double *A, int ldA, double *B, int ldB,
double *C, int ldC )
{
double *Btilde = ( double * ) malloc( KC * NC * sizeof( double ) );
for ( int p=0; p<k; p+=KC ) {
int pb = min( KC, k-p ); /* Last loop may not involve a full block */
PackPanelB_KCxNC( pb, n, &beta( p, 0 ), ldB, Btilde );
LoopThree( m, n, pb, &alpha( 0, p ), ldA, Btilde, C, ldC );
}
free( Btilde);
}
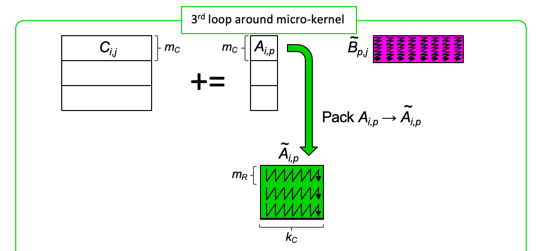
void LoopThree( int m, int n, int k, double *A, int ldA, double *Btilde, double *C, int ldC )
{
double *Atilde = ( double * ) malloc( MC * KC * sizeof( double ) );
for ( int i=0; i<m; i+=MC ) {
int ib = min( MC, m-i ); /* Last loop may not involve a full block */
PackBlockA_MCxKC( ib, k, &alpha( i, 0 ), ldA, Atilde );
LoopTwo( ib, n, k, Atilde, Btilde, &gamma( i,0 ), ldC );
}
free( Atilde);
}
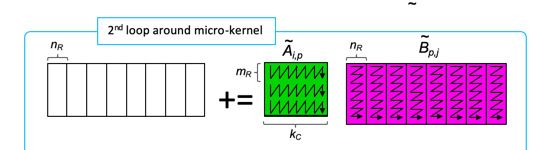
void LoopTwo( int m, int n, int k, double *Atilde, double *Btilde, double *C, int ldC )
{
for ( int j=0; j<n; j+=NR ) {
int jb = min( NR, n-j );
LoopOne( m, jb, k, Atilde, &Btilde[ j*k ], &gamma( 0,j ), ldC );
}
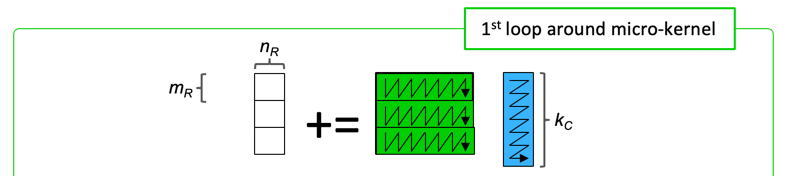
void LoopOne( int m, int n, int k, double *Atilde, double *Micro-PanelB, double *C, int ldC )
{
for ( int i=0; i<m; i+=MR ) {
int ib = min( MR, m-i );
Gemm_MRxNRKernel_Packed( k,Ã[ i*k ], Micro-PanelB, &gamma( i,0 ), ldC );
}
}