Unit 1.6.1 Additional exercises
¶We start with a few exercises that let you experience the BLIS typed API and the traditional BLAS interface.
Homework 1.6.1.1. (Optional).
In Unit 1.3.3 and Unit 1.3.5, you wrote implementations of the routine
MyGemv( int m, int n, double *A, int ldA, double *x, int incx, double *y, int incy )The BLIS typed API (Unit 1.5.2) includes the routine
bli_dgemv( trans_t transa, conj_t conjx, dim_t m, dim_t n,
double* alpha, double* a, inc_t rsa, inc_t csa,
double* x, inc_t incx,
double* beta, double* y, inc_t incy );
which supports the operations
and other variations on matrix-vector multiplication.
To get experience with the BLIS interface, copy Assignments/Week1/C/Gemm_J_Gemv.c into Gemm_J_bli_dgemv.c and replace the call to MyGemv with a call to bli_dgemv instead. You will also want to include the header file blis.h,
#include "blis.h"replace the call to MyGemv with a call to bli_dgemv and, if you wish, comment out or delete the now unused prototype for MyGemv. Test your implementation with
make J_bli_dgemvYou can then view the performance with Assignments/Week1/C/data/Plot_Outer_J.mlx.
Replace
MyGemv( m, k, A, ldA, &beta( 0, j ), 1, &gamma( 0,j ), 1 );with
double d_one=1.0; bli_dgemv( BLIS_NO_TRANSPOSE, BLIS_NO_CONJUGATE, m, k, &d_one, A, 1, ldA, &beta( 0,j ), 1, &d_one, &gamma( 0,j ), 1 );Note: the BLIS_NO_TRANSPOSE indicates we want to compute \(y := \alpha A x + \beta y \) rather than \(y := \alpha A^T x + \beta y \text{.}\) The BLIS_NO_CONJUGATE parameter indicates that the elements of \(x \) are not conjugated (something one may wish to do with complex valued vectors).
The ldA parameter in MyGemv now becomes two paramters: 1, ldA. The first indicates the stride in memory between elements in the same column by consecutive rows (which we refer to as the row stride) and the second refers to the stride in memory between elements in the same row and consecutive columns (which we refer to as the column stride).
Homework 1.6.1.2. (Optional).
The traditional BLAS interface (Unit 1.5.1) includes the Fortran call
DGEMV( TRANSA, M, N, ALPHA, A, LDA, X, INCX, BETA, Y, INCY )which also supports the operations
and other variations on matrix-vector multiplication.
To get experience with the BLAS interface, copy Assignments/Week1/C/Gemm_J_Gemv.c (or Gemm_J_bli_dgemv) into Gemm_J_dgemv and replace the call to MyGemv with a call to dgemv. Some hints:
In calling a Fortran routine from C, you will want to call the routine using lower case letters, and adding an underscore:
dgemv_
You will need to place a "prototype" for dgemv_ near the beginning of Gemm_J_dgemv:
void dgemv_( char *, int *, int *, double *, double *, int *, double *, int *, double *, double *, int * );
Fortran passes parameters by address. So,
MyGemv( m, k, A, ldA, &beta( 0, j ), 1, &gamma( 0,j ), 1 );
becomes{ int i_one=1; double d_one=1.0; dgemv_( "No transpose", &m, &k, &d_one, A, &ldA, &beta( 0, j ), &i_one, &d_one, &gamma( 0,j ), &i_one ); }
Test your implementation with
make J_dgemvYou can then view the performance with Assignments/Week1/C/data/Plot_Outer_J.mlx.
On Robert's laptop, the last two exercises yield
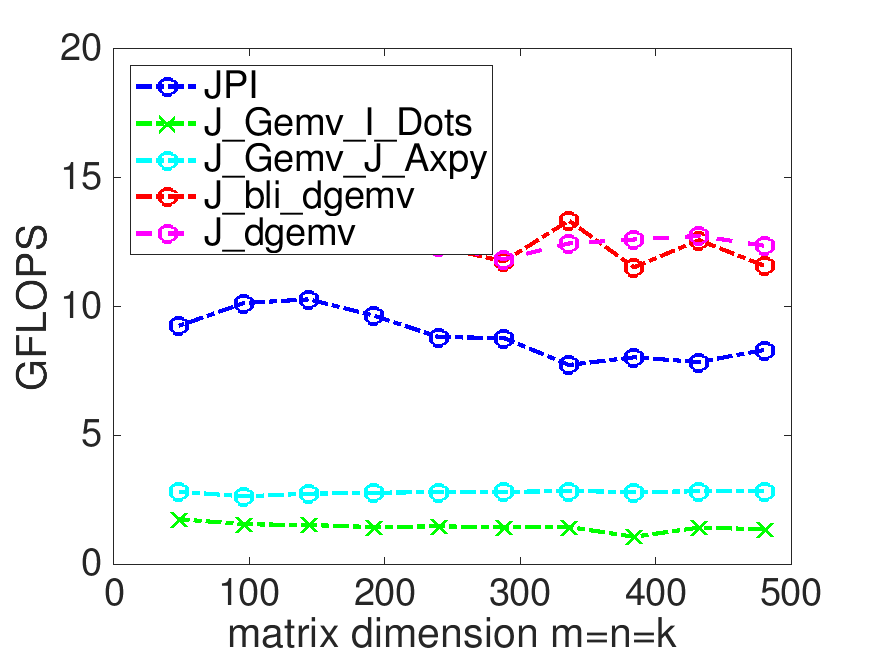
Linking to an optmized implementation (provided by BLIS) helps.
The calls to bli_dgemv and dgemv are wrappers to the same implementations of matrix-vector multiplication within BLIS. The difference in performance that is observed should be considered "noise."
It pays to link to a library that someone optimized.
Homework 1.6.1.3. (Optional).
In Unit 1.4.1, You wrote the routine
MyGer( int m, int n, double *x, int incx, double *y, int incy, double *A, int ldA )that compues a rank-1 update. The BLIS typed API (Unit 1.5.2) includes the routine
bli_dger( conj_t conjx, conj_t conjy, dim_t m, dim_t n,
double* alpha, double* x, inc_t incx, double* y, inc_t incy,
double* A, inc_t rsa, inc_t csa );
which supports the operation
and other variations on rank-1 update.
To get experience with the BLIS interface, copy Assignments/Week1/C/Gemm_P_Ger.c into Gemm_P_bli_dger and replace the call to MyGer with a call to bli_dger. Test your implementation with
make P_bli_dgerYou can then view the performance with Assignments/Week1/C/data/Plot_Outer_P.mlx.
Replace
MyGer( m, n, &alpha( 0, p ), 1, &beta( p,0 ), ldB, C, ldC );with
double d_one=1.0; bli_dger( BLIS_NO_CONJUGATE, BLIS_NO_CONJUGATE, m, n, &d_one, &alpha( 0, p ), 1, &beta( p,0 ), ldB, C, 1, ldC );The BLIS_NO_CONJUGATE parameters indicate that the elements of \(x \) and \(y \) are not conjugated (something one may wish to do with complex valued vectors).
The ldC parameter in MyGer now becomes two paramters: 1, ldC. The first indicates the stride in memory between elements in the same column by consecutive rows (which we refer to as the row stride) and the second refers to the stride in memory between elements in the same row and consecutive columns (which we refer to as the column stride).
Homework 1.6.1.4. (Optional).
The traditional BLAS interface (Unit 1.5.1) includes the Fortran call
DGER( M, N, ALPHA, X, INCX, Y, INCY, A, LDA );which also supports the operation
To get experience with the BLAS interface, copy Assignments/Week1/C/Gemm_P_Ger.c (or Gemm_P_bli_dger) into Gemm_P_dger and replace the call to MyGer with a call to dger. Test your implementation with
make P_dgerYou can then view the performance with Assignments/Week1/C/data/???.
Replace
Ger( m, n, &alpha( 0,p ), 1, &beta( p,0 ), ldB, C, ldC );with
double d_one=1.0; int i_one=1; dger_( m, n, &d_one, &alpha( 0,p ), &i_one, &beta( p,0 ), \amp;ldB, C, \amp;ldC );The _ (underscore) allows C to call the Fortran routine. (This is how it works for most compilers, but not all.) The "No transpose" indicates we want to compute \(y := \alpha A x + \beta y \) rather than \(y := \alpha A^T x + \beta y \text{.}\) Fortran passes parameters by address, which is why d_one and i_one are passed as in this call.
On Robert's laptop, the last two exercises yield
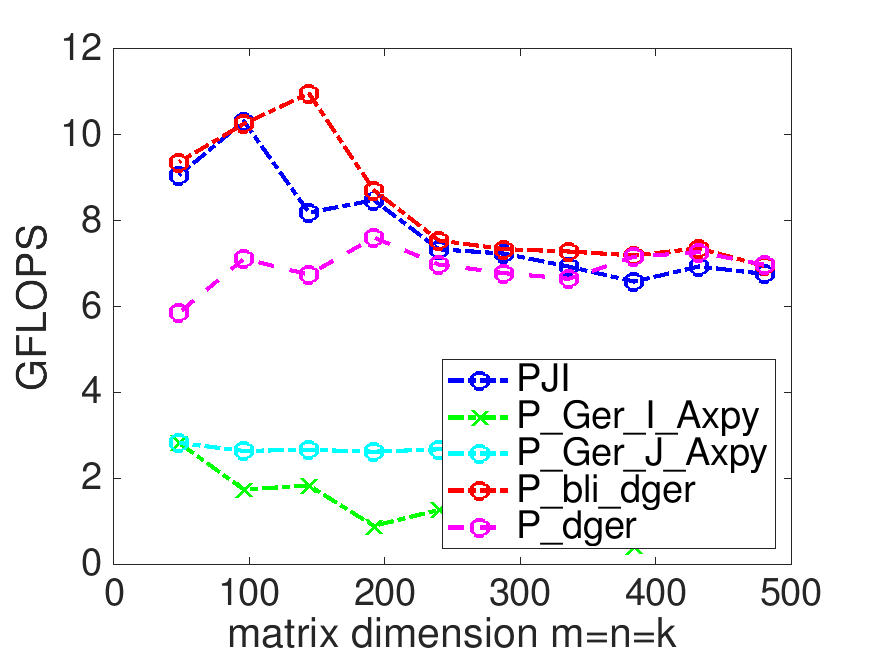
Linking to an optmized implementation (provided by BLIS) does not seem to help (relative to PJI).
The calls to bli_dger and dger are wrappers to the same implementations of matrix-vector multiplication within BLIS. The difference in performance that is observed should be considered "noise."
It doesn't always pay to link to a library that someone optimized.
Next, we turn to computing \(C := A B + C \) via a series of row-times-matrix multiplications.
Recall that the BLAS include the routine dgemv that computes
What we want is a routine that computes
What we remember from linear algebra is that if \(A = B \) then \(A^T = B^T \text{,}\) that \(( A + B)^T = A^T + B^T \text{,}\) and that \((A B)^T = B^T A^T \text{.}\) Thus, starting with the the equality
and transposing both sides, we get that
which is equivalent to
and finally
So, updating
is equivalent to updating
It this all seems unfamiliar, you may want to look at Linear Algebra: Foundations to Frontiers
Now, if
\(m \times n \) matrix \(A \) is stored in array A with its leading dimension stored in variable ldA,
\(m \) is stored in variable m and \(n \) is stored in variable n,
vector \(x \) is stored in array x with its stride stored in variable incx,
vector \(y \) is stored in array y with its stride stored in variable incy, and
\(\alpha \) and \(\beta \) are stored in variables alpha and beta, respectively,
then \(y := \alpha A^T x + \beta y \) translates, from C, into the call
dgemv_( "Transpose", &m, &n, &alpha, A, &ldA, x, &incx, &beta, y, &incy );
Homework 1.6.1.5.
In directory Assignments/Week1/C complete the code in file Gemm_I_dgemv.c that casts matrix-matrix multiplication in terms of the dgemv BLAS routine, but compute the result by rows. Compile and execute it with
make I_dgemv
View the resulting performance by making the necessary changes to the Live Script in Assignments/Week1/C/Plot_All_Outer.mlx. (Alternatively, use the script in Assignments/Week1/C/data/Plot_All_Outer_m.mlx.)
The BLIS native call that is similar to the BLAS dgemv routine in this setting translates to
bli_dgemv( BLIS_TRANSPOSE, BLIS_NO_CONJUGATE, m, n, &alpha, A, ldA, 1, x, incx, &beta, y, incy );
Because of the two parameters after A that capture the stride between elements in a column (the row stride) and elements in rows (the column stride), one can alternatively swap these parameters:
bli_dgemv( BLIS_NO_TRANSPOSE, BLIS_NO_CONJUGATE, m, n, &alpha, A, ldA, 1, x, incx, &beta, y, incy );
Homework 1.6.1.6.
In directory Assignments/Week1/C complete the code in file Gemm_I_bli_dgemv.c that casts matrix-matrix mulitplication in terms of the bli_dgemv BLIS routine. Compile and execute it with
make I_bli_dgemv
View the resulting performance by making the necessary changes to the Live Script in Assignments/Week1/C/Plot_All_Outer.mlx. (Alternatively, use the script in Assignments/Week1/C/data/Plot_All_Outer_m.mlx.)
On Robert's laptop, the last two exercises yield
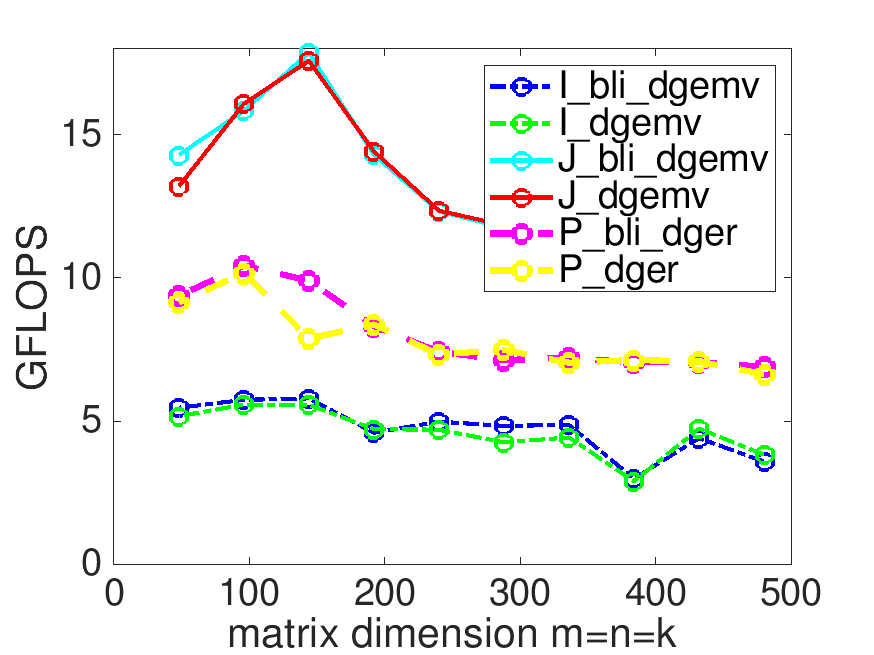
Casting matrix-matrix multiplication in terms of matrix-vector multiplications attains the best performance. The reason is that as columns of \(C \) are computed, they can stay in cache, reducing the number of times elements of \(C \) have to be read and written from main memory.
Accessing \(C \) and \(A \) by rows really gets in the way of performance.