

Figure 1 shows the general architecture of the system. Faces are represented as rectangular graphs by layers of neurons. Each neuron represents a node and has a jet attached. A jet is a local description of the grey-value distribution based on the Gabor transform [9,20]
Topographical relationships between nodes are encoded by excitatory
and inhibitory lateral connections. The model graphs are scaled
horizontally and vertically and aligned manually, such that certain
nodes of the graphs are placed on the eyes and the mouth
(cf. the Data Base section). Model layers
(10 10 neurons) are smaller than the image layer (16
10 neurons) are smaller than the image layer (16 17
neurons). Since the face in the image may be arbitrarily translated,
the connectivity between model and image domain has to be
all-to-all initially. The connectivity matrices are initialized
using the similarities between the jets of the connected neurons.
DLM serves as a process to restructure the connectivity matrices and
to find the correct mapping between the models and the image (see
Figure 2). The models cooperate with the image
depending on their similarity. A simple winner-take-all mechanism
sequentially rules out the least active and least similar models, and
the best-fitting one eventually survives.
17
neurons). Since the face in the image may be arbitrarily translated,
the connectivity between model and image domain has to be
all-to-all initially. The connectivity matrices are initialized
using the similarities between the jets of the connected neurons.
DLM serves as a process to restructure the connectivity matrices and
to find the correct mapping between the models and the image (see
Figure 2). The models cooperate with the image
depending on their similarity. A simple winner-take-all mechanism
sequentially rules out the least active and least similar models, and
the best-fitting one eventually survives.
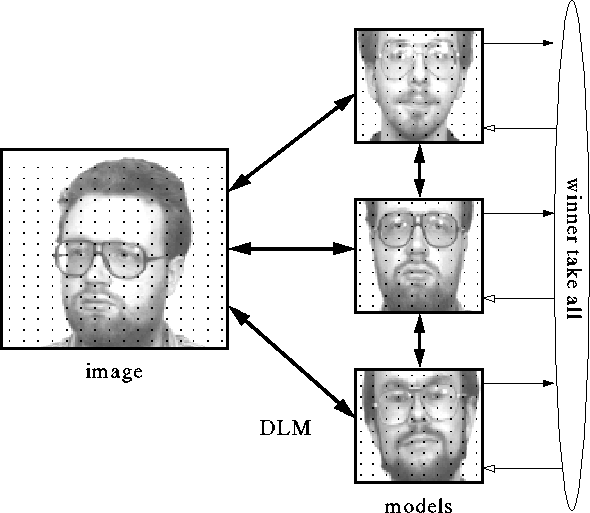
Figure 1: Architecture of the DLM face
recognition system. Several models are stored as neural layers of
local features on a 10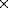 10 grid, as indicated by the black
dots. A new image is represented by a 16
10 grid, as indicated by the black
dots. A new image is represented by a 16 17 layer of nodes.
Initially, the image is connected all-to-all with the models.
The task of DLM is to find the correct mapping between the
image and the models, providing translational invariance and
robustness against distortion. Once the correct mapping is found, a
simple winner-take-all mechanism can detect the model that is most
active and most similar to the image.
17 layer of nodes.
Initially, the image is connected all-to-all with the models.
The task of DLM is to find the correct mapping between the
image and the models, providing translational invariance and
robustness against distortion. Once the correct mapping is found, a
simple winner-take-all mechanism can detect the model that is most
active and most similar to the image.
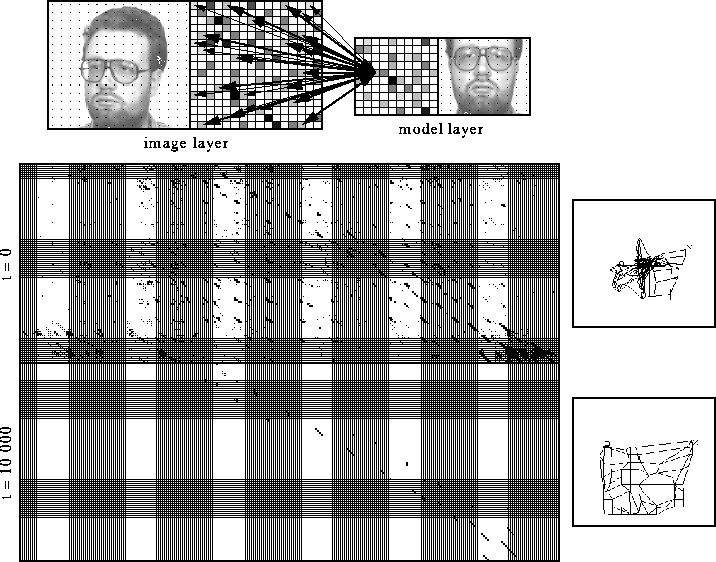
Figure 2: (click on the image to view a larger version) Initial and final connectivity for
DLM. Image and model are represented by layers of 16 17 and
10
17 and
10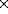 10 nodes respectively. Each node is labeled with a local
feature indicated by small texture patterns. Initially, the image
layer and the model layer are connected all-to-all with synaptic
weights depending on the feature similarities of the connected nodes,
indicated by arrows of different line widths. The task of DLM is to
select the correct links and establish a regular one-to-one
mapping. We see here the initial connectivity at t=0 and the final
one at t=10000. Since the
connectivity between a model
and the image is a four-dimensional matrix, it is difficult to
visualize it in an intuitive way. If the rows of each layer are
concatenated to a vector, top row first, the connectivity matrix
becomes two-dimensional. The model index increases from left to
right, the image index from top to bottom. High similarity values
are indicated by black squares. A second way to illustrate the
connectivity is the net display shown at the right. The image layer
serves as a canvas on which the model layer is drawn as a net. Each
node corresponds to a model neuron, neighboring neurons are connected
by an edge. The location of the nodes indicate the center of gravity
of the projective field of the model neurons considering synaptic
weights as physical mass. In order to favor strong links, the masses
are taken to the power of three. (see
Figure 5 for connectivity development in
time)
10 nodes respectively. Each node is labeled with a local
feature indicated by small texture patterns. Initially, the image
layer and the model layer are connected all-to-all with synaptic
weights depending on the feature similarities of the connected nodes,
indicated by arrows of different line widths. The task of DLM is to
select the correct links and establish a regular one-to-one
mapping. We see here the initial connectivity at t=0 and the final
one at t=10000. Since the
connectivity between a model
and the image is a four-dimensional matrix, it is difficult to
visualize it in an intuitive way. If the rows of each layer are
concatenated to a vector, top row first, the connectivity matrix
becomes two-dimensional. The model index increases from left to
right, the image index from top to bottom. High similarity values
are indicated by black squares. A second way to illustrate the
connectivity is the net display shown at the right. The image layer
serves as a canvas on which the model layer is drawn as a net. Each
node corresponds to a model neuron, neighboring neurons are connected
by an edge. The location of the nodes indicate the center of gravity
of the projective field of the model neurons considering synaptic
weights as physical mass. In order to favor strong links, the masses
are taken to the power of three. (see
Figure 5 for connectivity development in
time)
The dynamics on each layer is such that it produces a running blob of activity which moves continuously over the whole layer. An activity blob can easily be generated from noise by local excitation and global inhibition . It is caused to move by delayed self-inhibition , which also serves as a memory for the locations where the blob has recently been. Since the models are aligned with each other, it is reasonable to enforce alignment between their running blobs by excitatory connections between neurons representing the same facial location. The blobs on the image and the model layers cooperate through the connection matrices; they tend to align and induce correlations between corresponding neurons. Then, fast synaptic plasticity and a normalization rule coherently modify the synaptic weights, and the correct connectivities between models and image layer can develop. Since the models get different input from the image, they differ in their total activity. The model with strongest connections from the image is the most active one. The models compete on the basis of their total activity. After a while the winner-take-all mechanism suppresses the least competitive models, and eventually only the best model survives. Since the image layer may be significantly larger than the model layers, we introduce an attention window in form of a large blob. It interacts with the running blob, restricts its region of motion, and can be shifted by it to the actual face position.
The equations of the system are given in Table 1; the respective symbols are listed in Table 2. In the following sections, we will explain the system step by step: blob formation, blob mobilization, interaction between two layers, link dynamics, attention dynamics, and recognition dynamics; in order to make the description clearer, parts of the equations in Table 1 corresponding to these functions will be repeated.

Table 1: Formulas of the DLM face recognition
system

Table 2: Variables and parameters of
the DLM face recognition system