Layered Learning is a Multiagent Learning paradigm designed to allow agents to learn to work together in a real-time, noisy environment in the presence of both teammates and adversaries. Layered Learning allows for a bottom-up definition of agent capabilities at different levels in a complete multiagent domain. Machine Learning opportunities are identified when hand-coding solutions are too complex to generate. Individual and collaborative behaviors in the presence of adversaries are organized, learned, and combined in a layered fashion (see Figure 1).
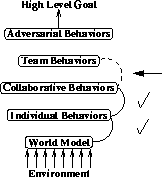
Figure 1: An overview of the Layered Learning framework. It is
designed for use in domains that are too complex to learn a mapping
straight from sensors to actuators. We use a hierarchical, bottom-up
approach. Two low-level behaviors have been previously learned. The
work reported in this paper creates a team behavior that facilitates
higher-level learning.
To date, two levels of learned behaviors have been implemented [13]. First, Soccer Server clients used a Neural Network (NN) to learn a low-level individual skill: how to intercept a moving ball. Then, using this learned skill, they learned a higher-level, more ``social,'' skill: one that involves multiple players. The second skill, the ability to estimate the likelihood that a pass to a particular teammate will succeed, was learned using a Decision Tree (DT). The DT was trained using C4.5 [8] under the assumption that the player receiving the ball uses the trained NN when trying to receive the pass. This technique of incorporating one learned behavior as part of another is an important component of Layered Learning. As a further example, the output of the decision tree could be used as the input to a higher-level learning module, for instance a reinforcement learning module, to learn whether or not to pass, and to whom.
The successful combination of the learned NN and DT demonstrated the feasibility of the Layered Learning technique. However, the combined behavior was trained and tested in a limited, artificial situation which does not reflect the full range of game situations. In particular, a passer in a fixed position was trained to identify whether a particular teammate could successfully receive a pass. Both the teammate and several opponents were randomly placed within a restricted range. They then used the trained NN to try to receive the pass.
Although the trained DT was empirically successful in the limited situation, it was unclear whether it would generalize to the broader class of game situations. The work reported in this paper incorporates the same trained DT into a complete behavior using which players decide when to chase the ball, and after reaching the ball, what to do with it.
First, a player moves to the ball-using the NN-when it does not perceive any teammates who are likely to reach it more quickly. Then, using a pre-defined communication protocol, the player probes its teammates for possible pass receivers (collaborators). When a player is going to use the DT to estimate the likelihood of a pass succeeding, it alerts the teammate that the pass is coming, and the teammate, in turn, sends some data reflecting its view of the world back to the passer. The DT algorithm used is C4.5 [8], which automatically returns confidence factors along with classifications. These confidence factors are useful when incorporating the DT into a higher level behavior capable of controlling a client in game situations.