To this point, we have shown that the inputs we used to train our neural network have allowed training in a particular part of the field to apply to other parts of the field. In this section we describe experiments that show that the 4-input neural network shooting policy described in Section 4.2 is flexible still further. All experiments in this section use exactly the same shooting policy with no further retraining.
Since the inputs are all relative to the Contact Point,
we predicted that the trajectory with which the ball approached the
shooter would not affect the performance of the neural network adversely. In
order to test this hypothesis we changed the initial positions of the
ball and the passer so that the ball would cross the shooter's path
with a different heading ( ![]() as opposed to
as opposed to ![]() ). This
variation in the initial setup is illustrated in
Figure 6. The ball's speed still varied as in
Section 4.2.
). This
variation in the initial setup is illustrated in
Figure 6. The ball's speed still varied as in
Section 4.2.
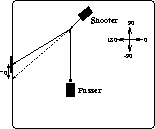
Figure 6: When the ball approached with a trajectory of ![]() instead of
instead of
![]() , the shooter had to change its aiming policy to aim 70 units
wide of the goal instead of 170 units wide.
, the shooter had to change its aiming policy to aim 70 units
wide of the goal instead of 170 units wide.
Indeed, the shooter was able to consistently make contact with the ball and redirect it towards the goal. However, it never scored because its steering line was aiming it too wide of the goal. Due to the ball's changed trajectory, aiming 170 units wide of the goal was no longer an appropriate aiming policy.
With the ball always coming with the same trajectory, we could simply change the steering line such that the shooter was aiming 70 units wide of the center of the goal. Doing so led to a success rate of 96.3%--even better than the actual training situation. This improved success rate can be accounted for by the fact that the ball was approaching the agent more directly so that it was slightly easier to hit. Nonetheless, it remained a difficult task, and it was successfully accomplished with no retraining. Not only did our learned shooting policy generalize to different areas of the field, but it also generalized to different ball trajectories.
Having used the same shooting policy to successfully shoot balls moving at 2 different trajectories, we knew that we could vary the ball's trajectory over a continuous range and still use the same policy to score. The only problem would be altering the shooter's aiming policy. Thus far we had chosen the steering line by hand, but we did not want to do that for every different possible trajectory of the ball. In fact, this problem gave us the opportunity to put the principal espoused by this article into use once again.
For the experiments described in the remainder of this section, the
ball's initial trajectory ranged randomly over ![]() (
( ![]() ). Figure 4(b) illustrates this range. The
policy used by the shooter to decide when to begin accelerating was
exactly the same one learned in Section 4.2 with no
retraining of the neural network. On top of this neural network, we added a new one to
determine the direction in which the shooter should steer. The
steering line determined by this direction and the shooter's current
position could then be used to compute the predicates needed as input
to the original neural network.
). Figure 4(b) illustrates this range. The
policy used by the shooter to decide when to begin accelerating was
exactly the same one learned in Section 4.2 with no
retraining of the neural network. On top of this neural network, we added a new one to
determine the direction in which the shooter should steer. The
steering line determined by this direction and the shooter's current
position could then be used to compute the predicates needed as input
to the original neural network.
For this new neural network we again chose parameters that would allow it to generalize beyond the training situation. The new input we chose was the angle between the ball's path and the line connecting the shooter's initial position with the center of the goal: the Ball-Agent Angle. The output was the Angle Wide of this second line that the shooter should steer. These quantities are illustrated in Figure 7(a). We found that performance improved slightly when we added as a second input an estimate of the ball's speed. However, since the neural network in the 4-input neural network shooting policy could only be used after the shooter determined the steering line, we used an estimate of Ball Speed after just two position readings. Then, the shooter's steering line was chosen by the learned aiming policy and the 4-input neural network shooting policy could be used to time the shot.
To gather training data for the new neural network, we ran many trials with the ball passed with different speeds and different trajectories while the Angle Wide was set to a random number between 0.0 and 0.4 radians. Using only the 783 positive examples, we then trained the neural network to be used for the shooters' learned aiming policy. Again, the inputs and the outputs were scaled to fall roughly between 0.0 and 1.0, there were two hidden units and two bias units, the weights were initialized randomly, and the learning rate was .01. The resulting neural network is pictured in Figure 7(b). Training this neural network for 4000 epochs gave a mean squared error of .0421.
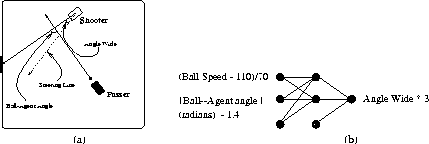
Figure 7: (a) The predicates we used to describe the world for the
purpose of learning an aiming policy. (b) The neural network used to learn
the aiming policy. The neural network has 2 hidden units with a bias unit at both
the input and hidden layers.
Using this 2-input neural network aiming policy to decide where to aim and the old 4-input neural network shooting policy to decide when to accelerate, the shooter scored 95.4% of the time while the ball's speed and trajectory varied. Using a neural network with just 1 input (omitting the speed estimate) and one hidden unit, or the 1-input neural network aiming policy, gave a success rate of 92.8%. Being satisfied with this performance, we did not experiment with other neural network configurations.