To test if the learned aiming policy could generalize beyond its training situation, we then moved the goal by a goal-width both down and up along the same side of the field (see Figure 4(c)). One can think of this variation as the shooter aiming for different parts of a larger goal (see Section 5.2). Changing nothing but the shooter's knowledge of where the goal was located, the shooter scored 84.1% of the time on the lower goal and 74.9% of the time on the upper goal (see Table 4). The discrepancy between these values can be explained by the greater difficulty of shooting a ball in a direction close to the direction that it was already travelling. As one would expect, when the initial situation was flipped so that the shooter began in the lower quadrant, these two success rates also flipped: the shooter scored more frequently when shooting at the higher goal. Notice that in this case, the representation of the output was as important as the inputs for generalization beyond the training situation.
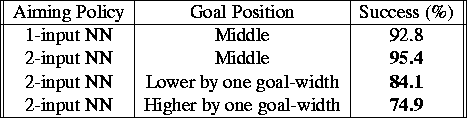
Table 4: When the ball's trajectory varied, a new aiming policy was
needed. Results are reasonable even when the goal is moved to a new
position.