For the task of shooting a moving ball, the passer's behavior was predetermined: it accelerated as fast as it could until it hit the ball. We varied the velocity (both speed and trajectory) of the ball by simply starting the passer and the ball in different positions.
However, in a real game, the passer would rarely have the opportunity to pass a stationary ball that is placed directly in front of it. It too would have to learn to deal with a ball in motion. In particular, the passer would need to learn to pass the ball in such a way that the shooter could have a good chance of putting the ball in the goal (see Figure 8).
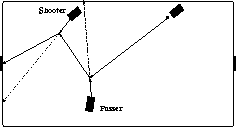
Figure 8: A collaborative scenario: the passer and
the shooter must both learn their tasks in such a way that they can
interact successfully.
Our approach to this problem is to use the low-level template learned in Section 4 for both the shooter and the passer. By fixing this behavior, the agents can learn an entirely new behavior level without worrying about low-level execution. Notice that once the passer and shooter have learned to cooperate effectively, any number of passes can be chained together. The receiver of a pass (in this case, the ``passer'') simply must aim towards the next receiver in the chain (the ``shooter'').
The parameters to be learned by the passer and the shooter are the point at which to aim the pass and the point at which to position itself respectively. While in Section 4 the shooter had a fixed goal at which to aim, here the passer's task is not as well-defined. Its goal is to redirect the ball in such a way that the shooter has the best chance of hitting it. Similarly, before the ball is passed, the shooter must get itself into a position that gives the passer the best chance at executing a good pass.
Figure 9 illustrates the inputs and outputs of the
passer's and shooter's behavior in this collaborative scenario. Based
on the Passer-Shooter Angle, the passer must choose the
Lead Distance, or the distance from the shooter (on the line
connecting the shooter to the goal) at which it should aim the
pass.![]() Notice that the input to the passer's
learning function can be manipulated by the shooter before the passer
aims the pass. Based on the passer's relative position to the goal,
the shooter can affect the Passer-Shooter Angle by positioning itself
appropriately. Since the inputs and outputs to these tasks are
similar to the task learned in Section 4, similar
neural network techniques can be used.
Notice that the input to the passer's
learning function can be manipulated by the shooter before the passer
aims the pass. Based on the passer's relative position to the goal,
the shooter can affect the Passer-Shooter Angle by positioning itself
appropriately. Since the inputs and outputs to these tasks are
similar to the task learned in Section 4, similar
neural network techniques can be used.
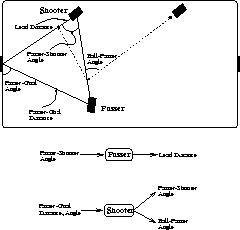
Figure 9: The parameters of the learning functions for the passer and
the shooter.
Since both the passer and the shooter are learning, this scenario satisfies both aspects of Weiß's definition of multiagent learning: more than one agent is learning in a situation where multiple agents are necessary. The phenomenon of the different agents' learning parameters interacting directly is one that is common among multiagent systems. The novel part of this approach is the layering of a learned multiagent behavior on top of another.
Continuing up yet another layer, the passing behavior can be incorporated and used when a player is faced with the decision of which teammate to pass to. Chaining passes as described above assumes that each player knows where to pass the ball next. However, in a game situation, given the positioning of all the other players on the field, the receiver of a pass must choose where it should send the ball next. In a richer and more widely used simulator environment [NodaNoda1995], the authors have used decision tree learning to enable a passer to choose from among possible receivers in the presence of defenders [Stone VelosoStone Veloso1996b]. In addition, in this current simulator, they successfully reimplemented the neural network approach to learning to intercept a moving ball as described in this article.