


Dynamic Motion Planning of Character Animation
The project provides an approach that automatically generates motion plans for character animation in novel situations. Although motion capture animation has become prevalent in the computer graphics industry, characters animated with this approach are only capable of the motions that have been previously recorded. The aim of this project is to address those limitations of motion capture animation.


Goal-Oriented Movement Recording
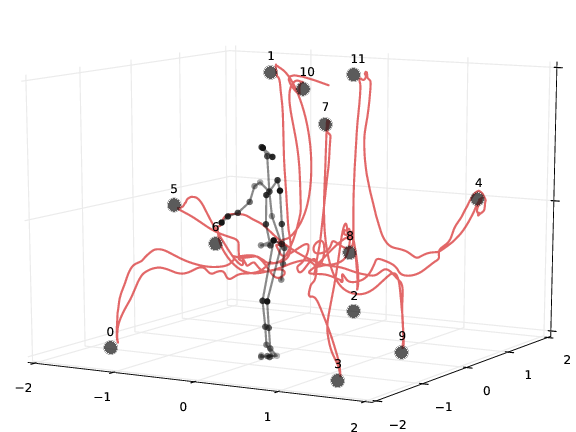
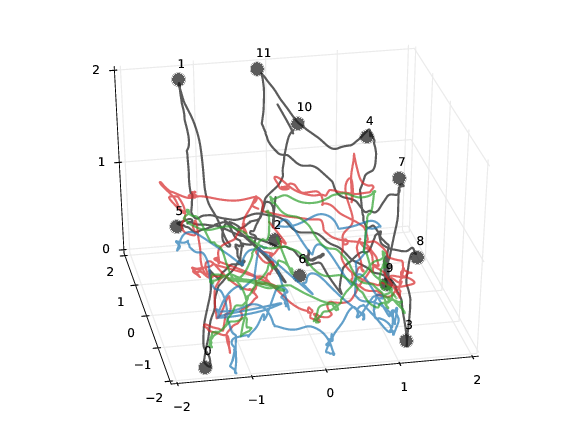
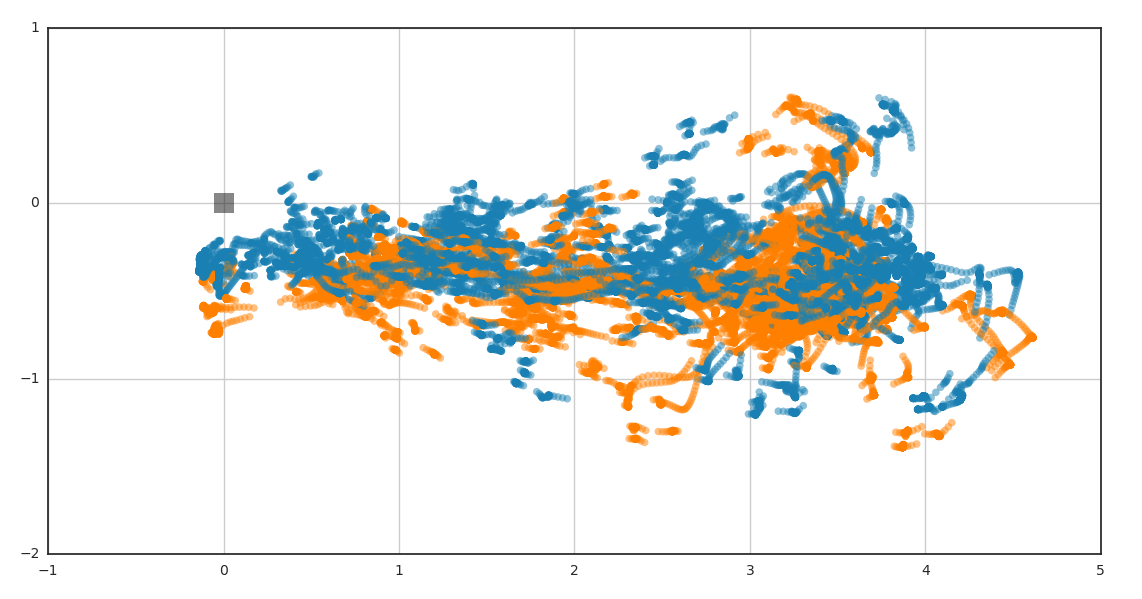
This project was aimed at measuring and recording unrestricted, whole-body movements during a goal-oriented reaching task. Subjects in the study were instructed to locate and touch (using the right index finger) each of 12 targets arranged at fixed locations in a 4m x 5m laboratory space. The resulting movements reveal striking regularity in behavior across subjects, and the known locations of the goals for the task permit quantitative analysis of the Jacobian that maps from intrinsic space to goal space.
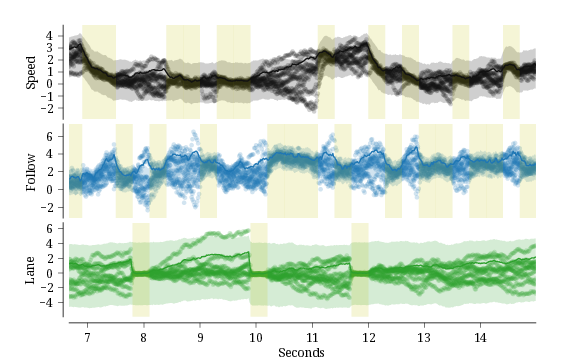
Soft Barrier Model for Ongoing Attention Allocation
Foveated vision requires active allocation of gaze, particularly in scenarios where multiple tasks are being performed simultaneously. Building on previous work, we developed a probabilistic model of attention allocation that juggles uncertain state estimates across multiple tasks, and allocates gaze dynamically to reduce reward-weighted uncertainty.


The Role of Reward and Uncertainty in Eye Movements
Human beings in the natural world must simultaneously perform a range of tasks, each of which may rely on different information from the scene. Eye movements are an important way of gathering necessary information, and the timing and choice of targets for gaze is critical for efficiently performing tasks. Actions, in turn, are chosen to maximize expected reward, which reflects the intrinsic importance of different behavioral goals for the subject. Sprague et al. (2007) proposed a model of gaze deployment based on the rewards and uncertainty associated with the tasks at hand (video). We have designed a novel virtual reality environment that allows us to systematically vary both the task rewards and the uncertainty of the information for each task. Subjects traverse the room on a path, while contacting targets and avoiding obstacles. Location information is made more uncertain by having targets and obstacles move. By varying the task structure and the uncertainty of the environment, we can investigate the roles of intrinsic reward and uncertainty in making eye movements and acting in the world.
Modular Inverse Reinforcement Learning
Inverse reinforcement learning can be used to model and understand human behaviors by estimating the intrinsic reward function. However, due to the curse of dimensionality, its use as a model for human behavior has been limited. Inspired by observed natural behaviors, one approach is to decompose complex tasks into independent sub-tasks, or modules. We developed what we called a modular maximum likelihood inverse reinforcement learning algorithm. We test our algorithm using tasks like human virtual driving, walking, and game playing.
Gaze and Gait Control During Locomotion over Real-world Rough Terrain
When walking over rough terrain, walkers must gather information about the layout of the upcoming path to support stable and efficient locomotion. In this context, the biomechanics of human gait define the task constraints that organize eye movements when traversing difficult terrain. However, very little is known about gaze patterns while walking outside a laboratory setting. We developed a novel experimental apparatus that records the eye movements and full-body kinematics of subjects walking over real-world terrain. For the first time, we can precisely record gaze and body movement data during natural behavior in unconstrained outdoor environments. Using this data, we hope to discover the way that humans extract information from real-world environments to facilitate safe and stable locomotion over rough and difficult terrain.
Spatial Memory and Visual Attention in Naturalistic Environments
Strategies of attention allocation may evolve as experience grows in daily environments. We combined immersive virtual reality and eye-tracking in this project to to characterize the development of memory representations and attention deployment in three-dimensional environments. Freely-moving subjects performed visual search tasks in virtual reality environments. This allows us to understand the cognitive process within the context of natural behaviors.