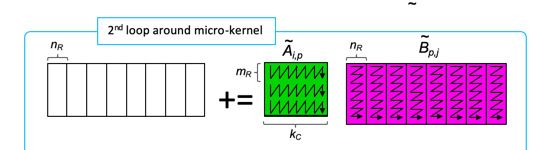
Let us next consider how to parallelize the second loop around the micro-kernel:
This time, the situation is very similar to that considered in Unit 4.1.1 when parallelizing the JPI loop ordering. There, in Homework 4.1.1.2 we observed that if \(C \) and \(B\) are partitioned by columns, the matrix-matrix multiplication can be described by
\begin{equation*}
\begin{array}{rcl}
\left( \begin{array}{c | c | c }
c_0 \amp \cdots \amp c_{n-1}
\end{array} \right)
\amp:= \amp A \left( \begin{array}{c | c | c }
b_0 \amp \cdots \amp b_{n-1}
\end{array} \right)
+
\left( \begin{array}{c | c | c }
c_0 \amp \cdots \amp c_{n-1}
\end{array} \right) \\
\amp = \amp
\left( \begin{array}{c | c | c }
A b_0 + c_0 \amp \cdots \amp A b_{n-1} + c_{n-1}
\end{array} \right).
\end{array}
\end{equation*}
We then observed that the update of each column of \(C\) can proceed in parallel.
The matrix-matrix multiplication
performed by the second loop around the micro-kernel instead partitions the row panel of \(C \) and the row panel of \(B \) into micro-panels.
\begin{equation*}
\begin{array}{rcl}
\left( \begin{array}{c | c | c }
C_0 \amp \cdots \amp C_{N-1}
\end{array} \right)
\amp:= \amp A \left( \begin{array}{c | c | c }
B_0 \amp \cdots \amp B_{N-1}
\end{array} \right)
+
\left( \begin{array}{c | c | c }
C_0 \amp \cdots \amp C_{N-1}
\end{array} \right) \\
\amp = \amp
\left( \begin{array}{c | c | c }
A B_0 + C_0 \amp \cdots \amp A B_{N-1} + C_{N-1}
\end{array} \right).
\end{array}
\end{equation*}
The bottom line: the updates of the micro-panels of \(C \) can happen in parallel.
Homework4.3.3.1.
In directory Assignments/Week4/C,
Copy Gemm_MT_Loop1_MRxNRKernel.c. into Gemm_MT_Loop2_MRxNRKernel.c.
Modify it so that only the second loop around the micro-kernel is parallelized.
Execute it with
export OMP_NUM_THREADS=4
make MT_Loop2_8x6Kernel
Be sure to check if you got the right answer!
View the resulting performance with data/Plot_MT_performance_8x6.mlx, changing 0 to 1 for the appropriate section.
Parallelizing the second loop appears to work very well. The granuarity of the computation in each iteration is larger. The ratio between NC and NR is typically large: in the makefile I set NC=2016 and NR=6, so that there are \(2016/6 = 336 \) tasks that can be scheduled to the threads. The only issue is that all cores load their L2 cache with the same block of \(A\text{,}\) which is a waste of a valuable resource (the aggregate size of the L2 caches).