
Unit 4.3.4 Parallelizing the third loop around the micro-kernel
¶Moving right along, consider how to parallelize the third loop around the micro-kernel:
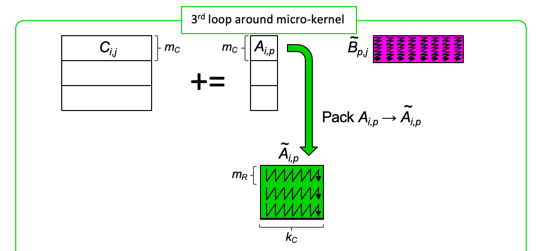
except that now the sizes of the row panels of \(C\) and blocsk of \(A \) are larger. The bottom line: the updates of the row-panels of \(C \) can happen in parallel.
Homework 4.3.4.1.
In directory Assignments/Week4/C,
Copy Gemm_MT_Loop2_MRxNRKernel.c. into Gemm_MT_Loop3_MRxNRKernel.c.
Modify it so that only the third loop around the micro-kernel is parallelized.
Execute it with
export OMP_NUM_THREADS=4 make MT_Loop3_8x6Kernel
Be sure to check if you got the right answer! Parallelizing this loop is a bit trickier... When you get frustrated, look at the hint. And when you get really frustrated, watch the video in the solution.
View the resulting performance with data/Plot_MT_performance_8x6.mlx, uncommenting the appropriate sections.
Parallelizing the third loop is a bit trickier. Likely, you started by inserting the #pragma statement and got the wrong answer. The problem lies with the fact that all threads end up packing a different block of \(A \) into the same buffer \(\widetilde A \text{.}\) How do you overcome this?
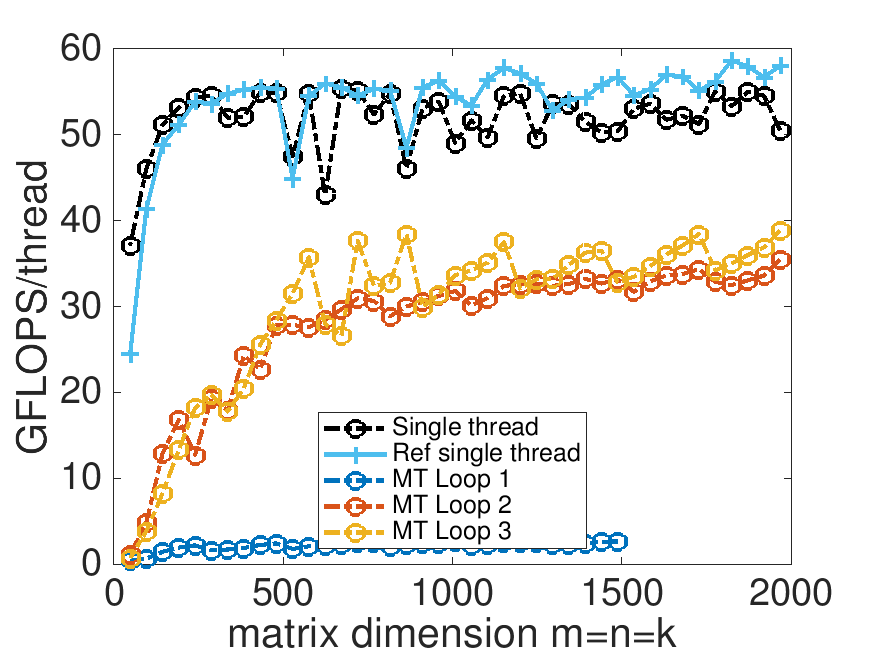
So what is the zigzagging in the performance graph all about? This has to do with the fact that \(m / MC \) is relatively small. If \(m = 650\text{,}\) \(MC = 72 \) (which is what it is set to in the makefile), and we use \(4 \) threads, then \(m / MC = 9.03 \) and hence two threads are assigned the computation related to two blocks of \(A \text{,}\) one thread is assigned three such blocks, and one thead is assigned a little more than two blocks. This causes load imbalance, which is the reason for the zigzagging in the curve.
So, you need to come up with a way so that most computation is performed using full blocks of \(A \) (with \(MC\) rows each) and the remainder is evenly distributed amongst the threads.
Homework 4.3.4.2.
Copy Gemm_MT_Loop3_MRxNRKernel.c. into Gemm_MT_Loop3_MRxNRKernel_simple.c to back up the simple implementation. Now go back to Gemm_MT_Loop3_MRxNRKernel.c and modify it so as to smooth the performance, inspired by the last video.
Execute it with
export OMP_NUM_THREADS=4 make MT_Loop3_8x6Kernel
Be sure to check if you got the right answer!
View the resulting performance with data/Plot_MT_performance_8x6.mlx.
You may want to store the new version, once it works, in Gemm_MT_Loop3_MRxNRKernel_smooth.c.
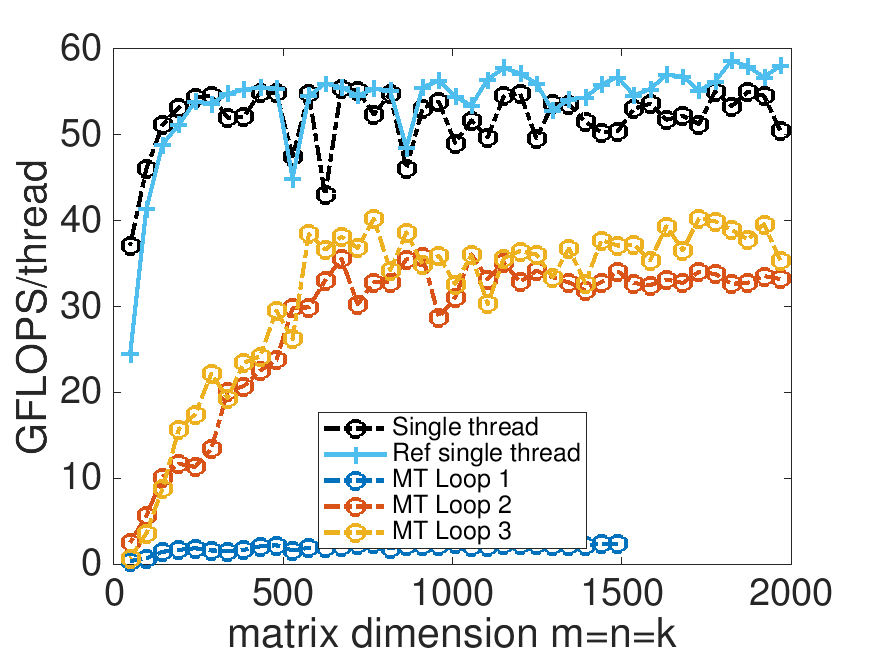
What you notice is that the performance is much smoother. Each thread now fills most of its own L2 cache with a block of \(A \text{.}\) They share the same row panel of \(B \) (packed into \(\widetilde B \)). Notice that the packing of that panel of \(B \) is performed by a single thread. We'll get back to that in Section 4.4.