Section 5.2 Monday Aug. 28
Subsection 5.2.1 Monday 8:30 - 8:55: Coffee and muffins
Subsection 5.2.2 Monday 8:55 - 9:00 Welcome by Robert van de Geijn
Subsection 5.2.3 Monday 9:00 - 10:45 Session 1
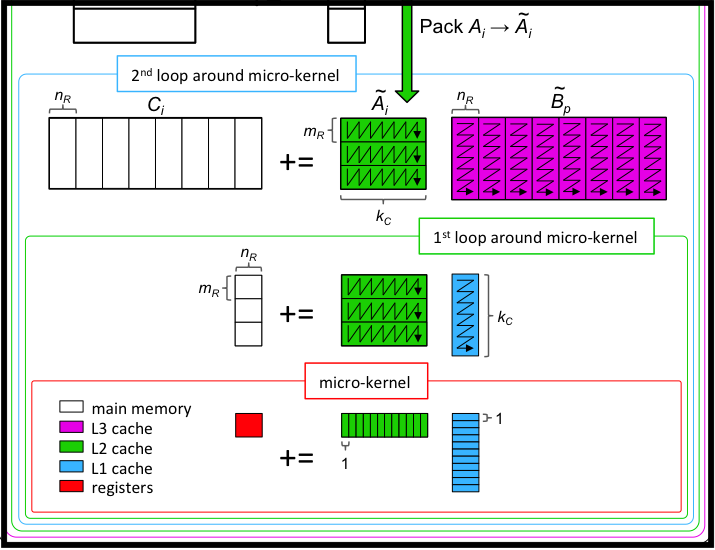
Subsubsection 5.2.3.1 BLIS V: The Final Frontier
Devin MatthewsSouthern Methodist University
Abstract:
BLIS makes BLAS better...more expressive and flexible interfaces, rapid instantiation on new architectures, well-documented and clean codebase...there's a lot about BLIS to love. But, BLIS has been evolving. What is and should BLIS be? Where is BLIS going in the future? Will BLIS ever be "done"? I will discuss these and similar questions, centering around work funded by the NSF over the past 3 years to expand the range of BLIS functionality.
Related materials
Subsubsection 5.2.3.2 L1 and L2 API Optimizations
Harihara SudhanAMD India
Subsubsection 5.2.3.3 Performance improvements of NRM2
Eleni VlachopoulouAMD UK
Related materials
Subsubsection 5.2.3.4 Additional Discussion
Subsection 5.2.4 Monday 10:45 - 11:00 Break
Subsection 5.2.5 Monday 11:00 - 12:30 Session 2
Subsubsection 5.2.5.1 The CLAG Framework: The Arm Performance Libraries approach to implementing BLAS
Joe DobsonArm UK
Abstract:
An overview of the design and implementation decisions behind Arm Performance Libraries' BLAS framework.
Subsubsection 5.2.5.2 Updates on Practical Strassen's Algorithms
Rodrigo BrandaoUT Austin
Collaborative work with Devangi Parikh
Abstract:
In this talk we will discuss a practical implementation of Strassen's and other Fast-Matrix Multiplication (FMM) Algorithms. With the recent interest in of discovering faster matrix multiplication algorithms using reinforcement learning, we investigate to see if these new algorithms have a practical benefit.Related materials
Subsubsection 5.2.5.3 Updates on casting higher precision in lower precision
Greg HenryUT Austin
Collaborative work with Devangi Parikh.
Related paper: Cascading GEMM: High Precision from Low Precision 4
Subsubsection 5.2.5.4 Additional Discussion
Subsection 5.2.6 Monday 12:30 - 1:30 Lunch
Subsection 5.2.7 Monday 1:30 - 3:00 Session 3
Subsubsection 5.2.7.1 Status of acceleration with libflame and BLIS
Johannes DieterichAMD Austin
Related materials not available. You may want to contact the speaker with questions.
Subsubsection 5.2.7.2 A Generalized Micro-kernel Abstraction for GPU Linear Algebra
Vijay ThakkarNVIDIA and Georgia Tech
Collaborative work with Cris Cecka
Related software:
https://github.com/nvidia/cutlass.
Subsubsection 5.2.7.3 An introduction to the SMaLL Framework for ML libraries
Upasana SridharCMU
Abstract:
We describe the SMaLL framework, a framework for rapidly developing high performance ML libraries for CPU-based platforms. We adopt a similar approach to BLIS by restricting the design effort to only a small set of kernels via a standard loop nest bodies. This allow us to target new hardware rapidly and avoids the overheads associated with translating ML primitives to linear algebra.
Related materials
Subsubsection 5.2.7.4 Additional Discussion
Subsection 5.2.8 Monday 3:00-3:15 Break
Subsection 5.2.9 Monday 3:15 - 5:00 Session 4
Subsubsection 5.2.9.1 Code Generation for BLIS/BLAS via Exo
Grace DinhUC Berkeley
Subsubsection 5.2.9.2 RandBLAS, An aspiring standard library and why it matters
Kaiwen HePurdue University
Related materials
Subsubsection 5.2.9.3 Auto-generated GEMM kernels for RISC-V RVV
Stepan NassyrJülich Supercomputing Centre
Related materials
Subsubsection 5.2.9.4 Ask me anything
Field Van ZeeUT Austin
Subsubsection 5.2.9.5 Additional Discussion
slides/Devin_blisretreat2023.pdfslides/BLIS_retreat_nrm2.pdfslides/Rodrigo_BLISRetreat2023.pdfhttps://arxiv.org/abs/2303.04353slides/Thakkar_BLISRetreat2023.pdfslides/Upasala_BLISRetreat2023.pdfslides/RandLAPACK_presentations.pdfhttps://arxiv.org/pdf/2302.11474.pdfslides/Generating_GEMM_for_RISC_V_RVV.pdf