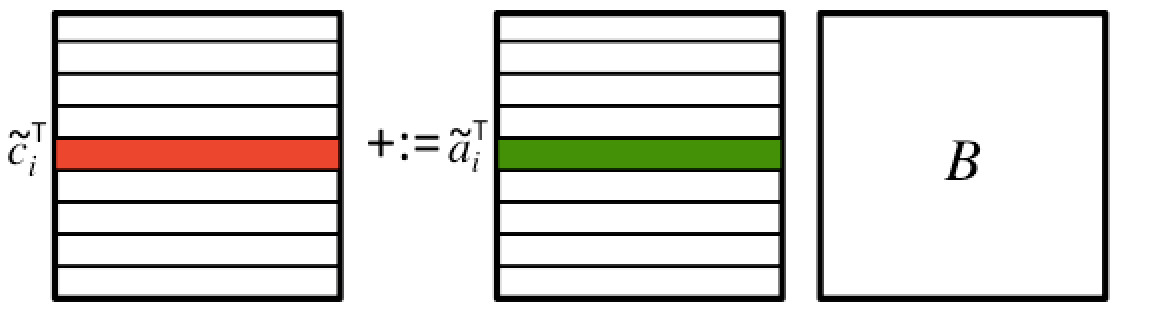
The way one is usually taught to compute this operations is that each element of \(y \text{,}\) \(\psi_i \text{,}\) is updated with the dot product of the corresponding row of \(A \text{,}\) \(\widetilde a_i^T \text{,}\) with vector \(x \text{.}\) With our notation, we can describe this as
What it demonstrates is how matrix-vector multiplication can be implemented as a sequence of dot operations.
Homework1.4.2
In directory Assignments/Week1/C complete the implementation of matrix-vector multiplication in terms of dot operations
#define alpha( i,j ) A[ (j)*ldA + i ] // map alpha( i,j ) to array A
#define chi( i ) x[ (i)*incx ] // map chi( i ) to array x
#define psi( i ) y[ (i)*incy ] // map psi( i ) to array x
void Dots( int, const double *, int, const double *, int, double * );
void Gemv( int m, int n, double *A, int ldA,
double *x, int incx, double *y, int incy )
{
for ( int i=0; i<m; i++ )
Dots( , , , , , );
}
in file Assignments/Week1/C/Gemv_I_Dots.c. You will test this with an implementation of matrix-matrix multiplication in a later homework.
What it also demonstrates is how matrix-vector multiplication can be implemented as a sequence of axpy operations.
Homework1.4.3
In directory Assignments/Week1/C complete the implementation of matrix-vector multiplication in terms of axpy operations
#define alpha( i,j ) A[ (j)*ldA + i ] // map alpha( i,j ) to array A
#define chi( i ) x[ (i)*incx ] // map chi( i ) to array x
#define psi( i ) y[ (i)*incy ] // map psi( i ) to array x
void Axpy( int, double, double *, int, double *, int );
void Gemv( int m, int n, double *A, int ldA,
double *x, int incx, double *y, int incy )
{
for ( int j=0; j<n; j++ )
Axpy( , , , , , );
}
in file Assignments/Week1/C/Gemv_J_Axpy.c. You will test this with an implementation of matrix-matrix multiplication in a later homework.
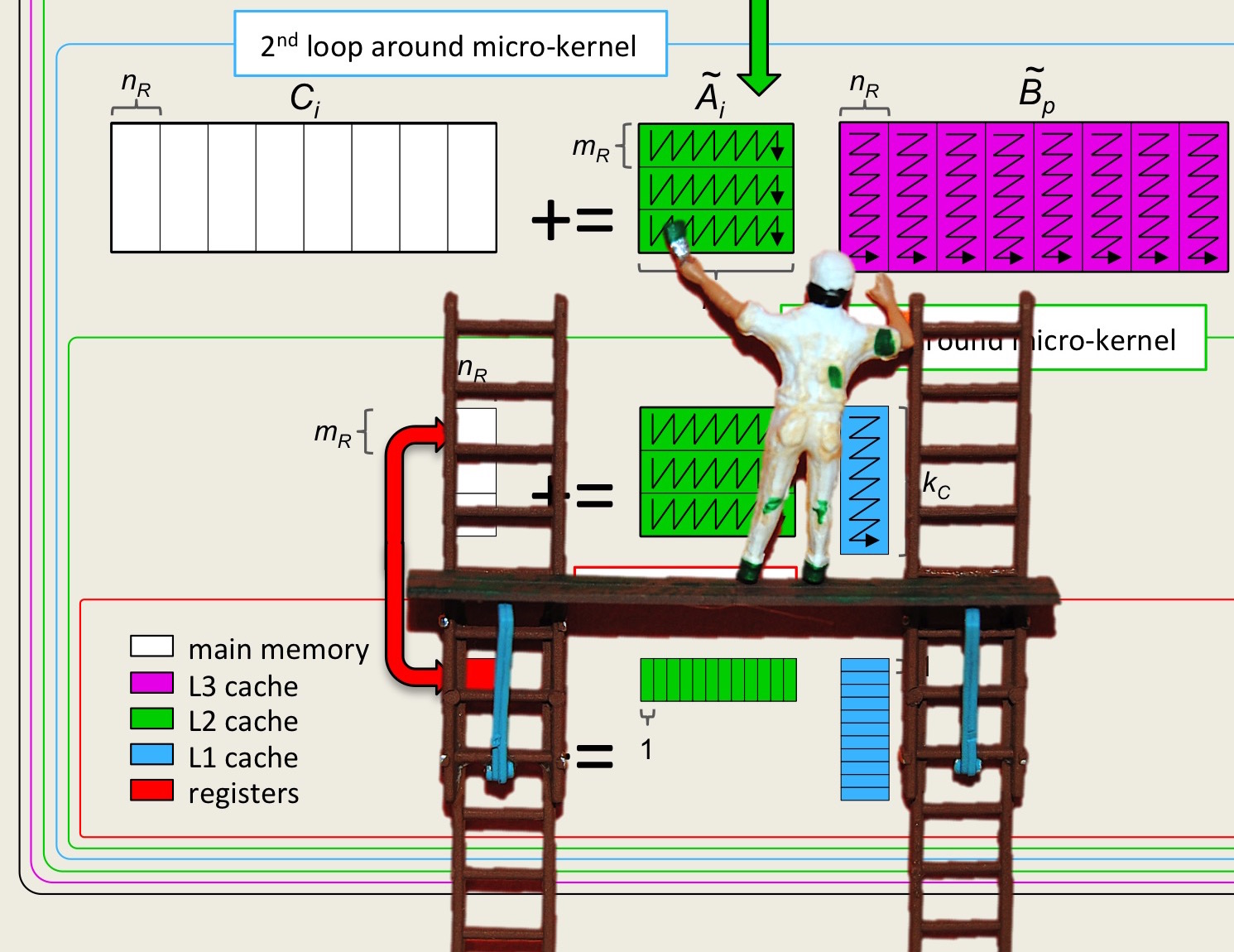
Now that we are getting comfortable with partitioning matrices and vectors, we can view the six algorithms for \(C := A B +
C \) is a more layered fashion. If we partition \(C \) and \(B \) by columns, we find that
\begin{equation*}
\begin{array}{rcl}
\left( \begin{array}{c | c | c | c }
c_0 \amp c_1 \amp \cdots \amp c_{n-1}
\end{array} \right)
\amp:=\amp
A \left( \begin{array}{c | c | c | c }
b_0 \amp b_1 \amp \cdots \amp b_{n-1}
\end{array} \right)
+
\left( \begin{array}{c | c | c | c }
c_0 \amp c_1 \amp \cdots \amp c_{n-1}
\end{array} \right)
\\
\amp = \amp
\left( \begin{array}{c | c | c | c }
A b_0 + c_0 \amp A b_1 + c_1 \amp \cdots \amp A b_{n-1} + c_{n-1}
\end{array} \right)
\end{array}
\end{equation*}
A picture that captures this is given by
This illustrates how the JIP and JPI algorithms can be viewed as a loop around matrix-vector multiplications:
\begin{equation*}
y := \alpha A x + \beta y \quad \mbox{or} \quad
y := \alpha A^T x + \beta y.
\end{equation*}
If
\(m \times n \) matrix \(A \) is stored in array A with its leading dimension stored in variable ldA,
\(m \) is stored in variable m and \(n \) is stored in variable n,
vector \(x \) is stored in array x with its stride stored in variable incx,
vector \(y \) is stored in array y with its stride stored in variable incy, and
\(\alpha \) and \(\beta \) are stored in variables alpha and beta, respectively,
the \(y := \alpha A x + \beta y \) translates, from C, into the call
dgemv_( "No transpose", &m, &n, &alpha, A, &ldA, x, &incx,
&beta, y, &incy );
Homework1.4.6
Complete the code in Assignments/Week1/C/Gemm_J_dgemv.c that casts matrix-matrix multiplication in terms of the dgemv BLAS routine. Test it by executing
The BLIS "native call" that is similar to the BLAS dgemv routine in this setting translates to
bli_dgemv( BLIS_NO_TRANSPOSE, BLIS_NO_CONJUGATE, m, n,
&alpha, A, 1, ldA, x, incx, &beta, y, incy );
Notice the two parameters after A. BLIS requires a row and column stride to be specified for matrices, thus generalizing beyond column-major order storage.
Homework1.4.7
Complete the code in Assignments/Week1/C/Gemm_J_bli_dgemv.c that casts matrix-matrix multiplication in terms of the bli_dgemv BLIS routine. Test it by executing
What it also demonstrates is how the rank-1 operation can be implemented as a sequence of axpy operations.
Homework1.4.10
In Assignments/Week1/C/Ger_J_Axpy.c complete the implementation of rank-1 in terms of axpy operations. You will test this with an implementation of matrix-matrix multiplication in a later homework.
In Assignments/Week1/C/Ger_I_Axpy.c complete the implementation of rank-1 in terms of axpy operations (by rows). You will test this with an implementation of MMM in a later homework.
\begin{equation*}
A := \alpha x y^T + A
\end{equation*}
If
\(m \times n \) matrix \(A \) is stored in array A with its leading dimension stored in variable ldA,
\(m \) is stored in variable m and \(n \) is stored in variable n,
vector \(x \) is stored in array x with its stride stored in variable incx,
vector \(y \) is stored in array y with its stride stored in variable incy, and
\(\alpha \) is stored in variable alpha,
the \(A := \alpha x y^T + A \) translates, from C, into the call
dger_( &m, &n, &alpha, x, &incx, &beta, y, &incy, A, &ldA );
Homework1.4.14
Complete the code in Assignments/Week1/C/Gemm_P_dger.c that casts matrix-matrix multiplication in terms of the dger BLAS routine. Compile and execute with
The BLIS native call that is similar to the BLAS dger routine in this setting translates to
bli_dger( BLIS_NO_CONJUGATE, BLIS_NO_CONJUGATE, m, n, &alpha, x, incx,
&beta, y, incy, A, 1, ldA );
Again, notice the two parameters after A. BLIS requires a row and column stride to be specified for matrices, thus generalizing beyond column-major order storage.
Homework1.4.15
Complete the code in Assignments/Week1/C/Gemm_P_bli_dger.c that casts matrix-matrix multiplication in terms of the bli_dger BLIS routine. Compile and execute with
This illustrates how the IJP and IPJ algorithms can be viewed as a loop around the updating of a row of \(C \) with the product of the corresponding row of \(A \) times matrix \(B \text{:}\)
The problem with implementing the above algorithms is that Gemv_I_Dots and Gemv_J_Axpy implement \(y := A x + y \) rather than \(y^T := x^T A
+ y^T \text{.}\) Obviously, you could create new routines for this new operation. We will instead look at how to use the BLAS and BLIS interfaces.
Recall that the BLAS include the routine dgemv that computes
\begin{equation*}
y := \alpha A x + \beta y \quad \mbox{or} \quad
y := \alpha A^T x + \beta y.
\end{equation*}
What we want is a routine that computes
\begin{equation*}
y^T := x^T A + y^T.
\end{equation*}
\(A = B \)\(A^T = B^T \text{,}\)\(( A + B)^T = A^T + B^T \text{,}\)\((A B)^T = B^T A^T \text{.}\)
\begin{equation*}
y^T = x^T A + y^T,
\end{equation*}
\begin{equation*}
(y^T)^T = ( x^T A + y^T)^T
\end{equation*}
\begin{equation*}
y = ( x^T A )^T + (y^T)^T
\end{equation*}
and finally
\begin{equation*}
y = A^T x + y.
\end{equation*}
So, updating
\begin{equation*}
y^T := x^T A + y^T
\end{equation*}
\(m \times n \) matrix \(A \) is stored in array A with its leading dimension stored in variable ldA,
\(m \) is stored in variable m and \(n \) is stored in variable n,
vector \(x \) is stored in array x with its stride stored in variable incx,
vector \(y \) is stored in array y with its stride stored in variable incy, and
\(\alpha \) and \(\beta \) are stored in variables alpha and beta, respectively,
then \(y := \alpha A^T x + \beta y \) translates, from C, into the call
dgemv_( "Transpose", &m, &n, &alpha, A, &ldA, x, &incx, &beta, y, &incy );
Homework1.4.17
In directory Assignments/Week1/C complete the code in file Gemm_I_dgemv.c that casts MMM in terms of the dgemv BLAS routine, but compute the result by rows. Compile and execute it with
The BLIS native call that is similar to the BLAS dgemv routine in this setting translates to
bli_dgemv( BLIS_TRANSPOSE, BLIS_NO_CONJUGATE, m, n,
&alpha, A, ldA, 1, x, incx, &beta, y, incy );
Because of the two parameters after A that capture the stride between elements in a column (the row stride) and elements in rows (the column stride), one can alternatively swap these parameters:
bli_dgemv( BLIS_NO_TRANSPOSE, BLIS_NO_CONJUGATE, m, n,
&alpha, A, ldA, 1, x, incx, &beta, y, incy );
Homework1.4.18
In directory Assignments/Week1/C complete the code in file Gemm_I_bli_dgemv.c that casts MMM in terms of the bli_dgemv BLIS routine. Compile and execute it with
So, for the outer loop there are three choices: \(j
\text{,}\) \(p \text{,}\) or \(i \text{.}\) This may give the appearance that there are only three algorithms. However, the matrix-vector multiply and rank-1 update hide a double loop and the order of these two loops can be chosen, to bring us back to six choices for algorithms. Importantly, matrix-vector multiplication can be organized so that matrices are addressed by columns in the inner-most loop (the JI order for computing gemv) as can the rank-1 update (the JI order for computing ger). For the implementation that picks the I loop as the outer loop, gemv is utilized but with the transposed matrix. As a result, there is no way of casting the inner two loops in terms of operations with columns.
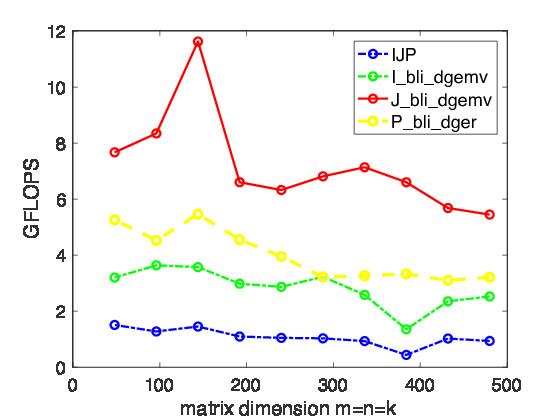
Figure1.4.4 Left: Performance of simple implementations of the different loop orderings. Right: Performance for different choices of the outer loop, calling the BLIS typed interface. All experiments were performed on Robert's laptop. Notice that the scale along the y-axis is not consistent between the two graphs.
Homework1.4.19
In directory Assignments/Week1/C/data use the Live Script in /Assignments/Week1/C/data/Plot_All_Outer.mlx to compare and contrast the performance of many of the algorithms that use the I, J, and P loop as the outer-most loop. If you want to rerun all the experiments, you can do so by executing
make Plot_All_Outer
in directory Assignments/Week1/C. What do you notice?
From the performance experiments reported in Figure 1.4.4, we have observed that accessing matrices by columns, so that the most frequently loaded data is contiguous in memory, yields better performance. Still, the observed performance is much worse than can be achieved.
We have now partitioning the matrices ,what we call "slicing and dicing", enhances our insight into how different algorithms access data. This will be explored and exploited further in future weeks.