Section 4.3 Matrix Multiplication
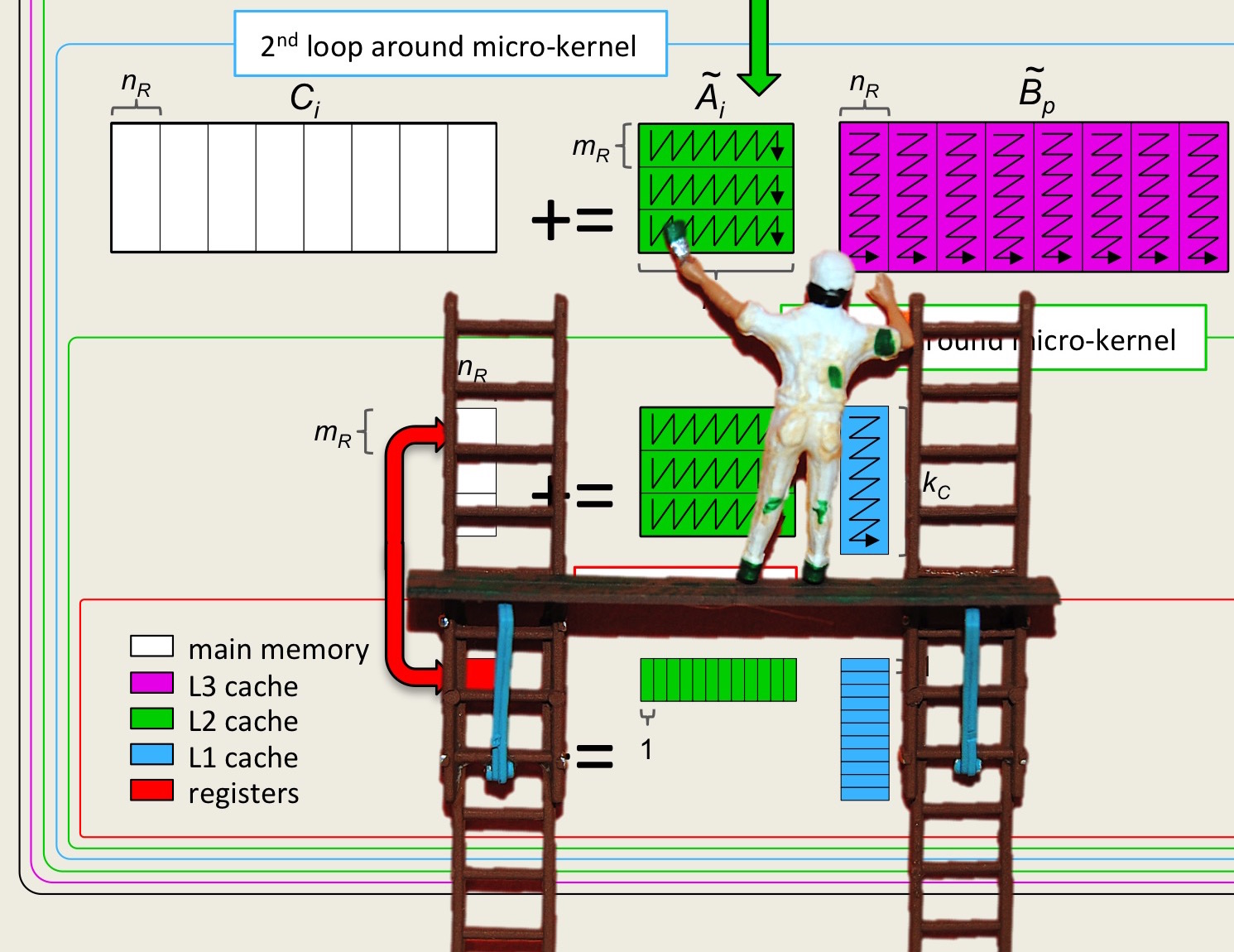
¶Unit 4.3.1 Parallelizing the second loop around the microkernel
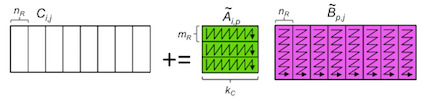
¶Now let's dive right in and parallelize one of the loops. We flipped a coin and it is the second loop around the microkernel that we are going to discuss first:
\lstinputlisting[firstline=73,lastline=79]{github/LAFF-On-PfHPC/Assignments/WeekB/C/GemmFiveLoops.c}
What we want to express is that each threads will perform a subset of multiplications of the submatrix \(\tilde A_{i,p} \) times the micropanels of \(\tilde B_{p,j} \text{.}\) Each should perform a roughly equal part of the necessary computation. This is indicated by inserting a pragma, a directive to the compiler: #pragma omp parallel for
for ( int j=0; j<n; j+=NR ) {
int jb = min( NR, n-j );
LoopOne( m, jb, k, Atilde, &Btilde[ j*k ], &gamma( 0,j ), ldC );
}
To compile this, we must add -fopenmp to the CFLAGS in the Makefile. Next, at execution time, you will want to indicate how many threads to use during the execution. First, to find out how many cores are available, you may want to execute lscpuwhich, on the machine where I tried it, yields
Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 20 On-line CPU(s) list: 0-19 Thread(s) per core: 2 Core(s) per socket: 10 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 63 Model name: Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz Stepping: 2 CPU MHz: 1326.273 CPU max MHz: 3000.0000 CPU min MHz: 1200.0000 BogoMIPS: 4594.96 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 25600K NUMA node0 CPU(s): 0-19and some additional information. What this tells us is that there are 10 cores, with two threads possible per core (this is called hyperthreading). On a mac you may want to try executing
sysctl -n hw.physicalcpuinstead. Next, you may then want to indicate, for example, that you want to use four threads:
export OMP_NUM_THREADS=4After you have added the directive to your code, compile it and execute.
So far, you have optimized your choice of MMM in file GemmFiveLoops_??x??.c where ??x?? reflects the register blocking for your microkernel. At this time, your implementation targets a single core. For the remainder of the exercises, you will start with the simplest implementation that includes packing, for the case where \(m_r \times n_r = 12 \times 4 \text{.}\) Now, in directory Week4/C,
Start with Gemm_Parallel_Loop2_12x4.c, in which you will find our implementation for a single core with \(m_r \times n_r = 12 \times 4 \text{.}\)
Modify it as described in this unit to parallelize Loop 2 around the microkernel.
Set the number of threads to some number between \(1 \) and the number of CPUs in the target processor.
Execute
make Parallel_Loop2_12x4
View the resulting performance with data/ShowPerformance.mlx.
Be sure to check if you got the right answer!
How does performance improve relative to the number of threads you indicated should be used?
Unit 4.3.2 Parallelizing the first loop around the microkernel
¶One can similarly optimize the first loop around the microkernel:
Homework 4.3.2
In directory Week4/C,
Copy Gemm_Parallel_Loop2_12x4.c into Gemm_Parallel_Loop1_12x4.c.
Modify it so that only the first loop around the microkernel is parallelized.
Set the number of threads to some number between \(1 \) and the number of CPUs in the target processor.
Execute make Parallel_Loop1_12x4.
View the resulting performance with data/ShowPerformance.mlx, uncommenting the appropriate lines. (You should be able to do this so that you see previous performance curves as well.)
Be sure to check if you got the right answer!
How does the performance improve relative to the number of threads being used?
Unit 4.3.3 Parallelizing the third loop around the microkernel
¶One can similarly optimize the third loop around the microkernel:
Homework 4.3.3
In directory Week4/C,
Copy Gemm_Parallel_Loop2_12x4.c into Gemm_Parallel_Loop3_12x4.c.
Modify it so that only the third loop around the microkernel is parallelized.
Set the number of threads to some number between \(2 \) and the number of CPUs in the target processor.
Execute make Parallel_Loop3_12x4.
View the resulting performance with ShowPerformance.mlx, uncommenting the appropriate lines.
Be sure to check if you got the right answer! This actually is trickier than you might at first think!
Observations:
-
Parallelelizing the third loop is a bit trickier. Likely, you started by inserting the #pragma statement and got the wrong answer. The problem is that you are now parallelizing
implemented by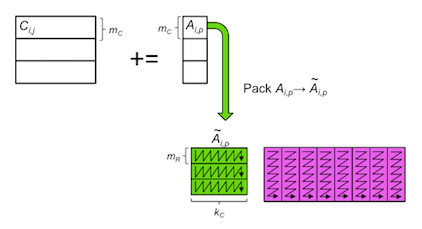
\begin{center} \lstinputlisting[firstline=62,lastline=71]{github/LAFF-On-PfHPC/Assignments/WeekB/C/GemmFiveLoops.c} \end{center}The problem with a naive parallelization is that all threads pack their block of \(A \) into the same buffer Atilde. There are two solutions to this:Quick and dirty: allocate and free a new buffer in this loop, so that each iteration, and hence each thread, gets a different buffer.
-
Cleaner: In Loop 5 around the microkernel, we currently allocate one buffer for Atilde:
void LoopThree( int m, int n, int k, double *A, int ldA, double *Btilde, double *C, int ldC ) { double *Atilde = ( double * ) malloc( MC * KC * sizeof( double ) ); for ( int i=0; i<m; i+=MC ) { int ib = min( MC, m-i ); PackBlockA_MCxKC( ib, k, &alpha( i, 0 ), ldA, Atilde ); LoopTwo( ib, n, k, Atilde, Btilde, &gamma( i,0 ), ldC ); } free( Atilde); }What one could do is to allocate a larger buffer here, enough for as many blocks \(\widetilde A\) as there are threads, and then in the third loop around the microkernel one can index into this larger buffer to give each thread its own space. For this, one needs to know about a few OpenMP inquiry routines:omp_get_num_threads() returns the number of theads being used in a parallel section.
omp_get_thread_num() returns the thread number of the thread that calls it.
Now, this is all a bit tricky, because omp_get_num_threads() returns the number of threads being used only in a parallel section. So, to allocate enough space, one would try to change the code in Loop 5 to
double *Atilde; #pragma omp parallel { if ( omp_get_thread_num() == 0 ) malloc( MC * NC * sizeof( double ) * omp_get_num_threads() ); }Here the curly brackets indicate the scope of the parallel section. The call to free must then be correspondingly modified so that only thread 0 releases the buffer.Now, in Loop 2, one can index into this larger buffer.