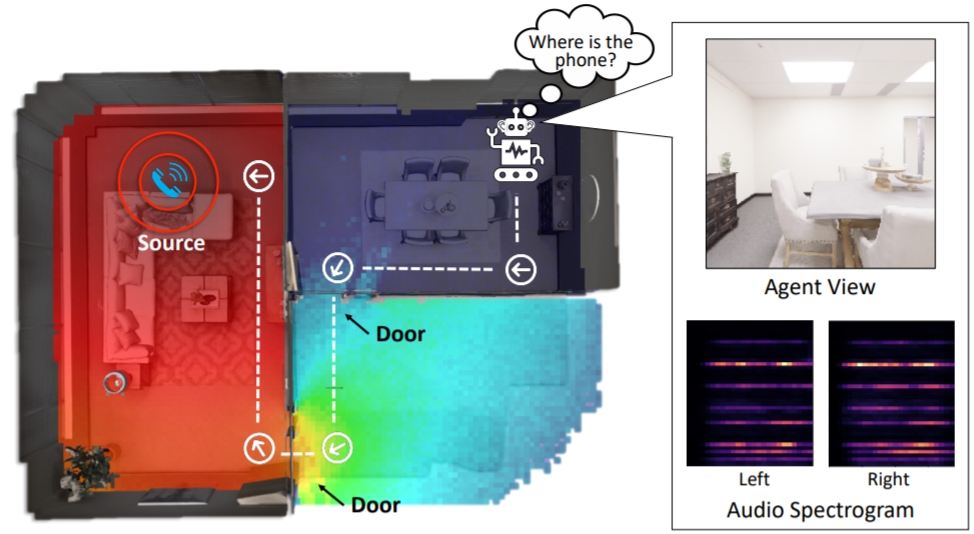
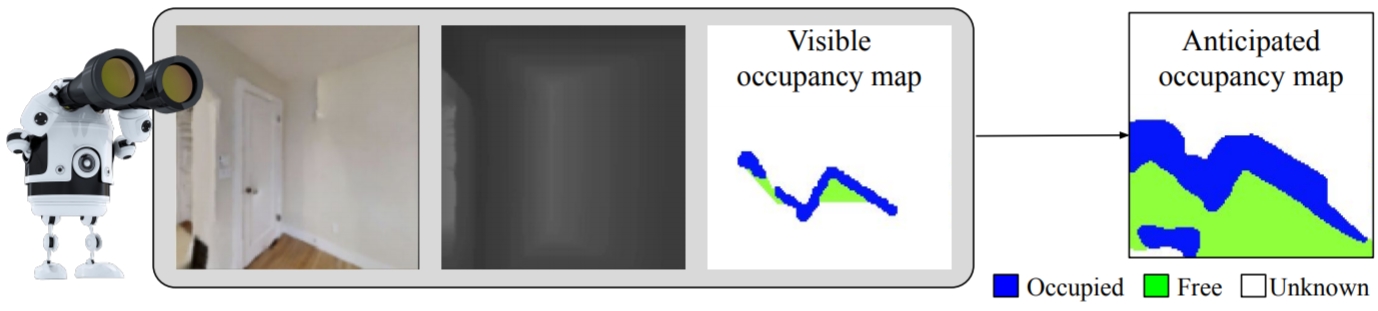
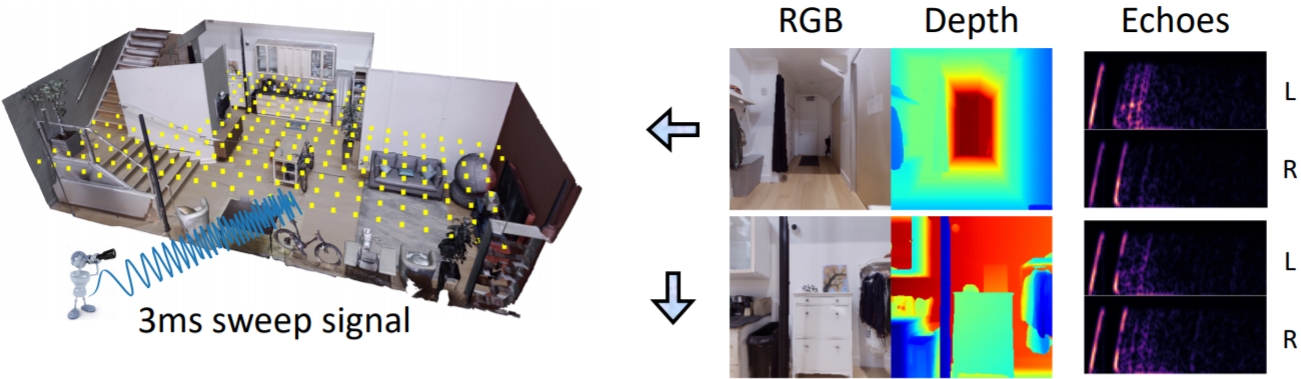
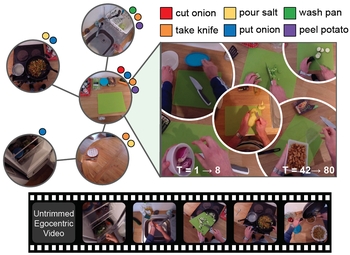
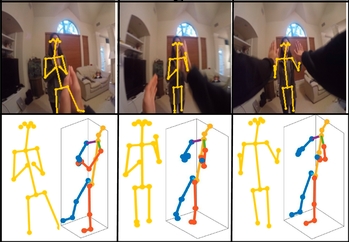
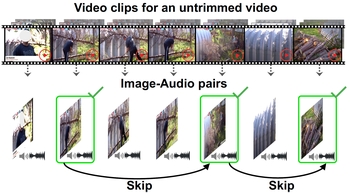
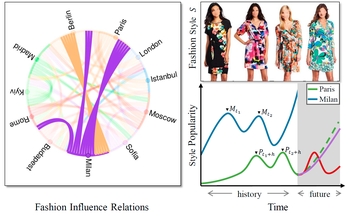
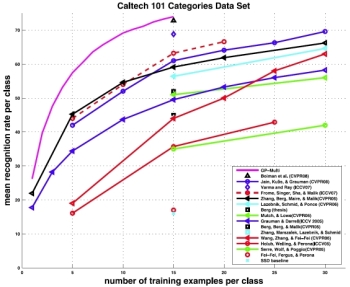
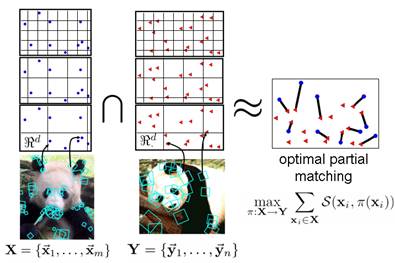
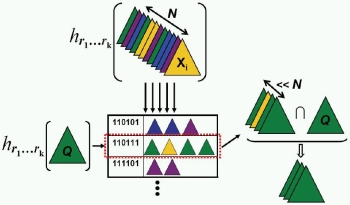
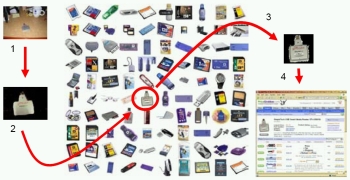
Mash, Spread, Slice! Learning to Manipulate
Object States via Visual Spatial Progress. Priyanka
Mandikal, Jiaheng Hu, Shivin Dass, Sagnik Majumder,
Roberto Martín-Martín*, Kristen Grauman*. IEEE
International Conference on Robotics and Automation
(ICRA), 2026 [pdf] [project]
and Best Poster Award at CoRL Beyond Rigid
Worlds Workshop
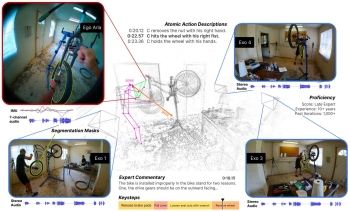
SkillSight: Efficient First-Person Skill
Assessment with Gaze. Chi hsuan Wu, Kumar Ashutosh,
Kristen Grauman. CVPR 2026 [pdf] [project]
HieraMamba: Video Temporal Grounding via
Hierarchical Anchor-Mamba Pooling. Joungbin An and
Kristen Grauman. CVPR 2026 [pdf] [project]
Seeing without Pixels: Perception from Camera
Trajectories. Zihui Xue, Kristen Grauman, Dima
Damen, Andrew Zisserman, Tengda Han. CVPR 2026
[pdf] [project]
Stitch-a-Demo: Creating Video Demonstrations
from Multistep Descriptions. Chi hsuan Wu, Kumar
Ashutosh, Kristen Grauman. CVPR 2026 [pdf] [project]
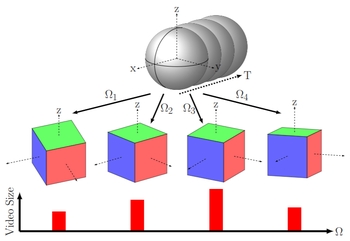
SPOC: Spatially-Progressing Object State
Change Segmentation in Video. Priyanka Mandikal, Tushar
Nagarajan, Alex Stoken, Zihui Xue, Kristen Grauman.
WACV 2026. [pdf] [project]
Seeing the Arrow of Time in Large
Multimodal Models. Zihui Xue, Mi Luo, Kristen
Grauman. NeurIPS 2025 [pdf] [project]
When Thinking
Drifts: Evidential Grounding for Robust Video
Reasoning. Mi Luo, Zihui Xue,Alex Dimakis,Kristen Grauman.
NeurIPS 2025. [pdf] [project]
Learning
Skill-Attributes for Transferable Assessment in
Video. Kumar Ashutosh, Kristen Grauman.
NeurIPS 2025.
PerceptionLM:
Open-Access Data and Models for Detailed Visual
Understanding. Cho et al. NeurIPS 2025.
Progress-Aware Video Frame Captioning.
Zihui Xue, Joungbin An, Xitong Yang, Kristen
Grauman. CVPR 2025 [pdf] [project]
Viewpoint Rosetta Stone: Unlocking Unpaired
Ego-Exo Videos for View-invariant Representation
Learning. Mi Luo, Zihui Xue, Alex Dimakis, Kristen
Grauman. CVPR 2025 (Oral) [pdf]
[project]
[code/model]
ExpertAF: Expert Actionable Feedback from
Video. Kumar Ashutosh, Tushar Nagarajan, Georgios
Pavlakos, Kris Kitani, Kristen Grauman. CVPR
2025 [pdf] [project]
FIction: 4D Future Interaction Prediction from
Video. Kumar Ashutosh, Georgios Pavlakos, Kristen
Grauman. CVPR 2025 (Highlight) [pdf] [project]
Which Viewpoint Shows it Best? Language for
Weakly Supervising View Selection in Multi-view
Instructional Videos. Sagnik Majumder, Tushar
Nagarajan, Ziad Al-Halah, Reina Pradhan, Kristen Grauman.
CVPR 2025. (Highlight) [paper] [project]
Vid2Coach:
Transforming How-To Videos into Task Assistants.
Mina Huh, Zihui Xue, Ujjaini Das, Kumar Ashutosh, Kristen
Grauman, Amy Pavel. UIST 2025 [paper] [project]
Switch-a-View: View Selection Learned from
Unlabeled In-the-wild Videos. Sagnik Majumder,
Tushar Nagarajan, Ziad Al-Halah, Kristen
Grauman. ICCV 2025 [paper]
[project]
Learning Activity View-invariance Under
Extreme Viewpoint Changes via Curriculum Knowledge
Distillation. Arjun Somayazulu, Efi Mavroudi,
Changan Chen, Lorenzo Torresani, Kristen
Grauman. 2025 [arXiv]
HOI-Swap: Swapping Objects in Videos with
Hand-Object Interaction Awareness. Zihui Xue, Romy
Luo, Changan Chen, Kristen Grauman. NeurIPS
2024. [pdf] [project]
Action2Sound:
Ambient-Aware Generation of Action Sounds from Egocentric
Videos. Changan Chen*, Puyuan Peng*, Ami Baid, Zihui
Xue, Wei-Ning Hsu, David Harwath, Kristen Grauman.
ECCV 2024 (Oral) [pdf] [project]
Put Myself in
Your Shoes: Lifting the Egocentric Perspective from
Exocentric Videos. Mi Luo, Zihui Xue, Alex Dimakis,
Kristen Grauman. ECCV 2024 [pdf] [project]
4DIFF:
3D-Aware Diffusion Model for Third-to-First Viewpoint
Translation. Feng Cheng*, Mi Luo*, Huiyu Wang, Alex
Dimakis, Lorenzo Torresani, Gedas Bertasius, Kristen
Grauman. ECCV 2024
Active
Audio-Visual Exploration for Acoustic Environment
Modeling. Arjun Somayazulu, Sagnik Majumder, Changan
Chen, Kristen Grauman. IROS 2024.
Sim2Real
Transfer for Audio-Visual Navigation with
Frequency-Adaptive Acoustic Field Prediction.
Changan Chen, Jordi Ramos Chen, Anshul Tomar, Kristen
Grauman. IROS 2024.
Ego-Exo4D:
Understanding Skilled Human Activity from First- and
Third-Person Perspectives. Kristen Grauman,
Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra
Malik, [full list of 100 authors in Ego-Exo4D
consortium].... Michael Wray. CVPR 2024 (Oral)
[paper]
[supp/appendix]
[data/benchmarks]
[blog]
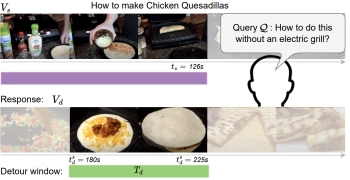
Detours for
Navigating Instructional Videos. Kumar Ashutosh,
Zihui Xue, Tushar Nagarajan, Kristen Grauman. CVPR
2024 (Poster highlight) [pdf]
[project
page]
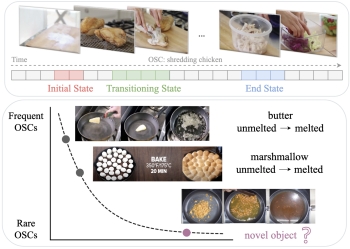
Learning
Object State Changes in Videos: An Open-World
Perspective. Zihui Xue, Kumar Ashutosh, Kristen
Grauman. CVPR 2024. [pdf]
[project
page]
SoundingActions:
Learning How Actions Sound from Narrated Egocentric
Videos. Changan Chen, Kumar Ashutosh, Rohit Girdhar,
David Harwath, Kristen Grauman. CVPR 2024. [pdf]
[project
page]
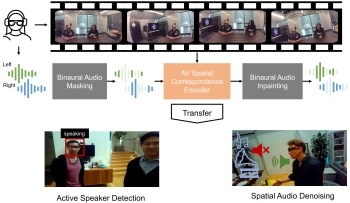
Learning
Spatial Features from Audio-Visual Correspondence in
Egocentric Videos. Sagnik Majumder, Ziad Al-Halah, Kristen
Grauman. CVPR 2024. [pdf]
[project
page]
EgoEnv:
Human-centric environment representations
from egocentric video. Tushar
Nagarajan, Santhosh Kumar Ramakrishnan, Ruta
Desai, James Hillis, Kristen Grauman.
NeurIPS 2023 (Oral) [pdf]
Learning Fine-grained
View-Invariant Representations from Unpaired Ego-Exo
Videos via Temporal Alignment. Zihui Xue and
Kristen Grauman. NeurIPS 2023. [pdf]
Single-Stage Visual Query
Localization in Egocentric Videos. Hanwen Jiang, Santhosh
Kumar Ramakrishnan, and Kristen Grauman. NeurIPS 2023. [pdf]
What You Say Is What You
Show: Visual Narration Detection in
Instructional Videos. Kumar Ashutosh,
Rohit Girdhar, Lorenzo Torresani, Kristen
Grauman. arXiv 2023. [pdf]
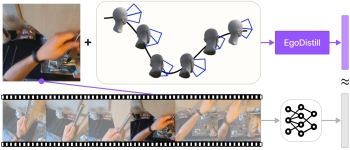
EgoDistill: Egocentric
Head Motion Distillation for Efficient Video
Understanding. Shuhan Tan, Tushar
Nagarajan, Kristen Grauman. NeurIPS 2023 [pdf]
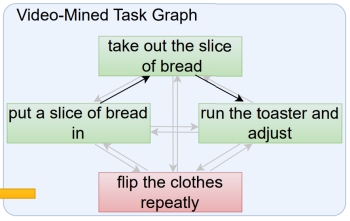
Video-Mined Task Graphs
for Keystep Recognition in Instructional
Videos. Kumar Ashutosh, Santhosh Kumar
Ramakrishnan, Triantafyllos Afouras, Kristen
Grauman. NeurIPS 2023. [pdf]
EgoTracks: A Long-term
Egocentric Visual Object Tracking Dataset.
Hao Tang, Kevin J Liang, Kristen Grauman, Matt
Feiszli, Weiyao Wang. NeurIPS 2023.
[pdf]
Visually-Guided Audio
Spatialization in Video with Geometry-Aware
Multi-task Learning. Rishabh Garg, Ruohan
Gao, Kristen Grauman. International
Journal of Computer Vision (IJCV). Vol
131. 2023. Special Issue for Best Papers
of BMVC [pdf]
Ego4D: Around the World
in 3,000 Hours of Egocentric Video. K.
Grauman et al. IEEE Trans. on Pattern
Analysis and Machine Intelligence (PAMI).
Invited article, Best Papers of
CVPR. 2023.
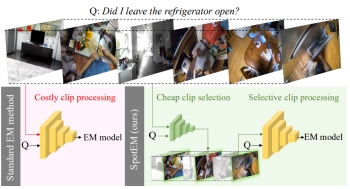
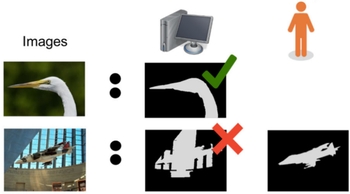
SpotEM:
Efficient Video Search for Episodic Memory. Santhosh
Kumar Ramakrishnan, Ziad Al-Halah, Kristen Grauman. ICML
2023 [pdf] [project]
Learning to
Map Efficiently by Active Echolocation. Xixi Hu,
Senthil Purushwalkam, David Harwath, Kristen
Grauman. IROS 2023.
A
domain-agnostic approach for characterization of lifelong
learning systems. M. Baker et al. Neural
Networks. Volume 160, Pages 274-296. March
2023. [link]
HierVL:
Learning Hierarchical Video-Language Embeddings.
Kumar Ashutosh, Rohit Girdhar, Lorenzo Torresani, Kristen
Grauman. CVPR 2023. Highlight paper [pdf] [project]
NaQ:
Leveraging Narrations as Queries to Supervise Episodic
Memory. Santhosh Kumar Ramakrishnan, Ziad Al-Halah,
Kristen Grauman. CVPR 2023. [pdf] [project]
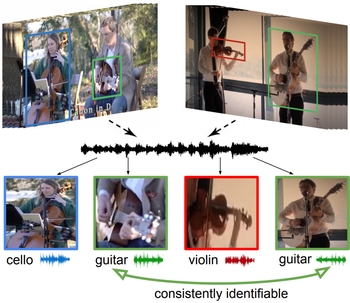
Chat2Map:
Efficient Scene Mapping from Multi-Ego
Conversations. Sagnik Majumder, Hao Jiang, Pierre
Moulon, Ethan Henderson, Paul Calamia, Kristen Grauman*,
Vamsi Ithapu*. CVPR 2023. [pdf] [project]
Egocentric
Video Task Translation. Zihui Xue, Yale Song,
Kristen Grauman, Lorenzo Torresani. CVPR
2023. (CVPR Highlight paper &
winner of Ego4D 2022 "Talking To Me" benchmark
challenge) [pdf] [project]
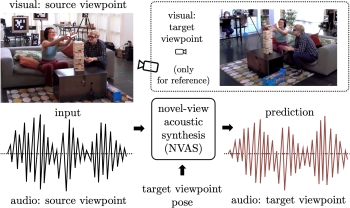
Novel-View
Acoustic Synthesis. Changan Chen, Alexander Richard,
Roman Shapovalov, Vamsi Krishna Ithapu, Natalia Neverova,
Kristen Grauman, Andrea Vedaldi. CVPR 2023. [pdf] [project]
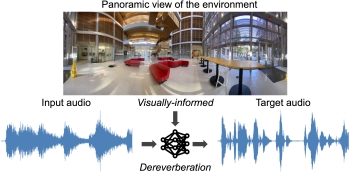
Learning
Audio-Visual Dereverberation. Changan Chen, Wei Sun, David
Harwath, Kristen Grauman. ICASSP 2023 [pdf] [project]
[code]
SoundSpaces
2.0: A Simulation Platform for Visual-Acoustic
Learning. Changan Chen*, Carl Schissler*, Sanchit
Garg*, Philip Kobernik, Alexander Clegg, Paul Calamia,
Dhruv Batra, Philip W Robinson, Kristen Grauman.
NeurIPS 2022 [pdf] [project
page]
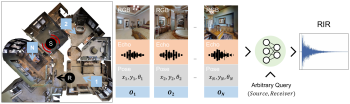
Few-Shot
Audio-Visual Learning of Environment Acoustics.
Sagnik Majumder, Changan Chen, Ziad Al-Halah, Kristen
Grauman. NeurIPS 2022. [pdf] [project
page]
Active
Audio-Visual Separation of Dynamic Sound Sources. S.
Majumder and K. Grauman. In Proceedings of the
European Conference on Computer Vision (ECCV), 2022. [pdf] [project
page]
Egocentric
Activity Recognition and Localization on a 3D Map.
M. Liu, L. Ma, K. Somasundaram, Y. Li, K. Grauman, J.
Rehg, C. Li.
In Proceedings of the European Conference on Computer
Vision (ECCV), 2022. [pdf]
[project page]
Ego4D: Around
the World in 3,000 Hours of Egocentric Video. K Grauman et
al. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), 2022. (Oral, Best Paper
Finalist) [pdf]
[supp]
[project
page]
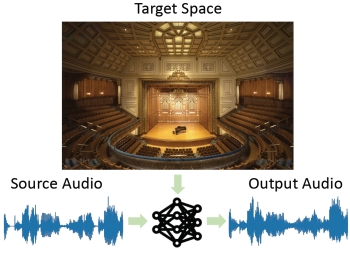
Visual
Acoustic Matching. C. Chen, R. Gao, P. Calamia, and
K. Grauman. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
2022. (Oral) [pdf]
[project
page]
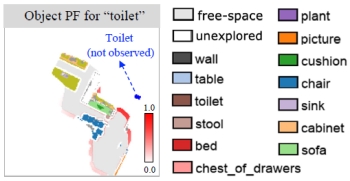
PONI:
Potential Functions for ObjectGoal Navigation with
Interaction-Free Learning. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
2022. (Oral) [pdf]
[project
page] [code]
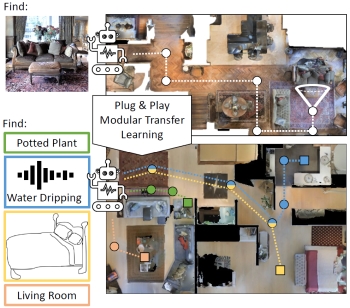
Zero
Experience Required: Plug & Play Modular Transfer
Learning for Semantic Visual Navigation. Z.
Al-Halah, S. Ramakrishnan, and K. Grauman. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
2022. [pdf]
[project
page]
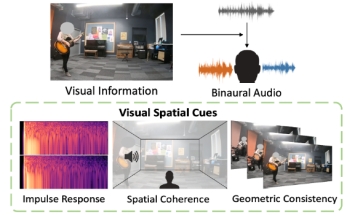
Geometry-Aware
Multi-Task Learning for Binaural Audio Generation from
Video. R. Garg, R. Gao, K. Grauman. In
Proceedings of the British Machine Vision Conference
(BMVC), 2021. (Oral) [Best Paper
Award Runner Up] [pdf] [project
page]
Environment
Predictive Coding for Embodied Agents. S. K.
Ramakrishnan, T. Nagarajan, Z. Al-Halah, and K.
Grauman. In Proceedings of the International
Conference on Learning Representations (ICLR), 2022.
[pdf]
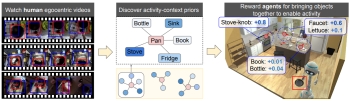
Shaping
Embodied Agent Behavior with Activity-context Priors from
Egocentric Video. T. Nagarajan and K. Grauman.
In Proceedings of Advances in Neural Information
Processing Systems (NeurIPS), Dec 2021. (spotlight oral).
[pdf]
[project
page]
DexVIP:
Learning Dexterous Grasping with Human Hand Pose Priors
from Video. P. Mandikal and K. Grauman. In
Conference on Robot Learning (CoRL), 2021. [pdf]
[project
page]
From Culture
to Clothing: Discovering the World Events Behind A Century
of Fashion Images. W-L. Hsiao and K. Grauman.
In Proceedings of the International Conference on
Computer Vision (ICCV), Oct 2021 (Oral). [pdf]
[project
page]
Audio-Visual
Floorplan Reconstruction. S. Purushwalkam, S. V. A.
Gari, V. K. Ithapu, C. Schissler, P. Robinson, A. Gupta,
K. Grauman. In
Proceedings of the International Conference on Computer
Vision (ICCV), Oct 2021 [pdf] [project/video]
Move2Hear:
Active Audio-Visual Source Separation. S. Majumder,
Z. Al-Halah, K. Grauman. In Proceedings of the International
Conference on Computer Vision (ICCV), Oct 2021. [pdf]
[code/videos]
Multiview
Pseudo-Labeling for Semi-supervised Learning from
Video. B. Xiong, H. Fan, K. Grauman, C.
Feichtenhofer. In
Proceedings of the International Conference on Computer
Vision (ICCV), Oct 2021. [pdf]
Anticipative
Video Transformer. R. Girdhar and K. Grauman.
In Proceedings of the
International Conference on Computer Vision (ICCV), Oct
2021. [pdf]
Winner of the EPIC-Kitchens CVPR'21 Action Anticipation
Challenge
Learning
Spherical Convolution for 360 Recognition. Y-C. Su
and K. Grauman. Transactions on Pattern Analysis and
Machine Intelligence (PAMI), Sept 2021. [link]
VisualVoice:
Audio-Visual Speech Separation with Cross-Modal
Consistency. R. Gao and K. Grauman. In
Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
2021. [pdf]
[project/video]
Ego-Exo: Transferring Visual
Representations from Third-person to First-person
Videos. Y. Li, T. Nagarajan, B. Xiong, K.
Grauman. In Proceedings of the IEEE
Conference on Computer Vision and Pattern
Recognition (CVPR), 2021. [pdf]
Semantic
Audio-Visual Navigation. C. Chen, Z.
Al-Halah, K. Grauman. In
Proceedings of
the IEEE
Conference on
Computer
Vision and
Pattern
Recognition
(CVPR), 2021.[pdf]
[project/video]
Fashion
IQ: A New Dataset Towards Retrieving Images
by Natural Language Feedback. H. Wu,
Y. Gao, X. Guo, Z. Al-Halah, S. Rennie, K.
Grauman, R. Feris. In Proceedings of
the IEEE Conference on
Computer Vision and Pattern
Recognition (CVPR), 2021. [pdf]
Learning
Dexterous Grasping with Object-Centric Visual
Affordances. P. Mandikal and K. Grauman.
In Proceedings of the International Conference on
Robotics and Automation (ICRA), 2021. [pdf]
[project]
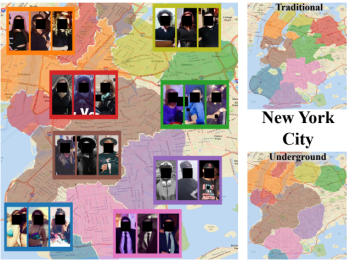
Discovering
Underground Maps from Fashion. U. Mall, K. Bala, T.
Berg, K. Grauman. Winter Conference on Applications of
Computer Vision (WACV), 2022. [pdf]
An
Exploration of Embodied Visual Exploration. S.
Ramakrishnan, D. Jayaraman, K. Grauman. IJCV
2021. [pdf]
[project]
[code]
Learning to
Set Waypoints for Audio-Visual Navigation. C. Chen,
S. Majumder, Z. Al-Halah, R. Gao, S. Ramakrishnan, K.
Grauman. In Proceedings of the International
Conference on Learning Representations (ICLR), May
2021. [pdf] [project]
Modeling
Fashion Influence from Photos, Z. Al-Halah and K.
Grauman. IEEE Transactions on Multimedia, Nov
2020. [pdf]
[project]
[code]
Learning
Affordance Landscapes for Interaction Exploration in 3D
Environments. T. Nagarajan and. K. Grauman. In
Proceedings of the Advances on Neural Information
Processing Systems (NeurIPS), Dec 2020. (Spotlight)
[pdf] [project]
[spotlight
talk]
SoundSpaces: Audio-Visual
Navigation in 3D Environments. C.
Chen*, U. Jain*, C. Schissler, S. V. Amengual Gari, Z.
Al-Halah, V. Ithapu, P. Robinson, K. Grauman. In
Proceedings of the European Conference on Computer Vision
(ECCV), August 2020. (Spotlight)
[videos]
[audio
simulation data] [code]
[pdf]
Occupancy
Anticipation for Efficient Exploration and
Navigation. S. Ramakrishnan, Z. Al-Halah, K.
Grauman. In
Proceedings of the European Conference on Computer Vision
(ECCV), August 2020. (Spotlight)
[project]
[pdf]
[code]
VisualEchoes:
Spatial Image Representation Learning through
Echolocation. R. Gao, C. Chen, Z. Al-Halah, C.
Schissler, K. Grauman. In Proceedings of the European Conference on
Computer Vision (ECCV), August 2020. [project]
[pdf]
[supp]
[data]
Proposal-based
Video Completion. Y-T. Hu, H. Wang, N. Ballas, K.
Grauman, A. Schwing. In Proceedings
of the European Conference on Computer Vision (ECCV),
August 2020. [pdf]
Densifying
Supervision for Fine-Grained Comparisons. A. Yu and
K. Grauman. International Journal of Computer Vision
(IJCV), Special Issue on Generative Adversarial Networks
for Computer Vision, 2020. [link]
Learning
Patterns of Tourist Movement and Photography from
Geotagged Photos at Archaeological Heritage Sites in
Cuzco, Peru. N. Payntar, W-L. Hsiao, A. Covey, K.
Grauman. To appear, Journal of Tourism Management,
2020. [arXiv]
Ego-Topo:
Environment Affordances from Egocentric Video. T.
Nagarajan, Y. Li, C. Feichtenhofer, K. Grauman. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Seattle, June 2020. (Oral)
[project
page/dataset] [pdf]
[supp]
You2Me:
Inferring Body Pose in Egocentric Video via First and
Second Person Interactions. E. Ng, D. Xiang, H. Joo,
K. Grauman. In Proceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Seattle, June 2020. (Oral)
[project
page/dataset] [pdf]
Listen to
Look: Action Recognition by Previewing Audio. R.
Gao, T-H. Oh, K. Grauman, L. Torresani. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Seattle, June 2020. [pdf]
[project
page]
ViBE:
Dressing for Diverse Body Shapes. W-L. Hsiao and K.
Grauman. In
Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), Seattle, June
2020. (Oral)
[project
page] [pdf]
[supp]
[data]
From Paris to
Berlin: Discovering Fashion Style Influences Around the
World. Z. Al-Halah and K. Grauman. In
Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), Seattle, June
2020. [pdf]
[supp]
[project
page] [code]
Don't Judge
an Object by Its Context: Learning to Overcome Contextual
Bias. K. Singh, D. Mahajan, K. Grauman, Y J. Lee, M.
Feiszli, D. Ghadiyaram. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Seattle, June 2020. (Oral)
[pdf]
Learning
Compressible 360 Video Isomers. Y-C. Su and K.
Grauman. Transactions on Pattern Analysis and
Machine Intelligence (PAMI). Feb 2020. [link]
Fashion++:
Minimal Edits for Outfit Improvement. W-L.
Hsiao, I. Katsman, C-Y. Wu, D. Parikh, K. Grauman.
In Proceedings of the International Conference on
Computer Vision (ICCV), Seoul, Korea, Nov 2019. [pdf]
[supp]
[video]
[code]
Grounded
Human-Object Interaction Hotspots from Video. T.
Nagarajan, C. Feichtenhofer, K. Grauman. In
Proceedings of the International Conference on Computer
Vision (ICCV), Seoul, Korea, Nov 2019. [pdf]
[supp]
[project
page]
Co-Separating
Sounds of Visual Objects. R. Gao and K.
Grauman. In Proceedings of the
International Conference on Computer Vision (ICCV), Seoul,
Korea, Nov 2019. [pdf]
[supp]
[videos]
[code]
ClickCarving:
Interactive Object Segmentation in Images and Videos with
Point Clicks. S. Jain and K. Grauman.
International Journal of Computer Vision (IJCV), Issue 9,
2019. [link]
2.5D Visual
Sound. R. Gao and K. Grauman. In Proceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Long Beach, CA, June 2019. (Oral)
[Best Paper Award finalist] [pdf]
[supp]
[FAIR-Play
dataset] [videos]
[code]
Emergence of
Exploratory Look-around Behaviors through Active
Observation Completion. S. Ramakrishnan, D.
Jayaraman, and K. Grauman. Science Robotics, Vol. 4,
Issue 30, May 2019. [link]
Kernel
Transformer Networks for Compact Spherical
Convolution. Y-C. Su and K. Grauman. In
Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), Long Beach, CA, June 2019. [pdf]
[supp]
[code/models]
Less is More:
Learning Highlight Detection from Video Duration. B.
Xiong, Y. Kalantidis, D. Ghadiyaram, and K. Grauman.
In Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), Long Beach, CA, June 2019.
[pdf]
[supp] [videos]
Thinking
Outside the Pool: Active Training Image Creation for
Relative Attributes. A. Yu and K. Grauman. In
Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), Long Beach, CA, June 2019. [pdf]
[supp]
[code/data]
Extreme
Relative Pose Estimation for RGB-D Scans via Scene
Completion. Z. Yang, J. Pan, L. Luo, X. Zhou, K.
Grauman, and Q. Huang. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Long Beach, CA, June 2019. (Oral)
[pdf]
[supp]
[code]
SpotTune:
Transfer Learning through Adaptive Fine-tuning. Y.
Guo, H. Shi, A. Kumar, K. Grauman, T. Rosing, and R.
Feris. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), Long
Beach, CA, June 2019. [pdf]
[code]
Predicting
How to Distribute Work Between Algorithms and Humans to
Segment an Image Batch. D. Gurari, Y. Zhao, S. Jain,
M. Betke, and K. Grauman. International Journal of
Computer Vision (IJCV), Volume 127, Issue 9, pp 1198–1216,
September 2019. [link]
[arXiv]
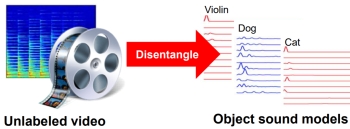
Learning to
Separate Object Sounds by Watching Unlabeled Video.
R. Gao, R. Feris, and K. Grauman. In Proceedings of
the European Conference on Computer Vision (ECCV), Munich,
Germany, Sept 2018. (Oral) [pdf]
[videos]
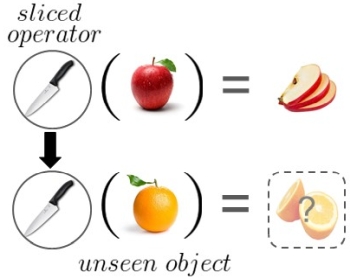
Attributes as
Operators. T. Nagarajan and K. Grauman.
In Proceedings of the European Conference
on Computer Vision (ECCV), Munich, Germany, Sept
2018. [pdf]
[supp]
[code]
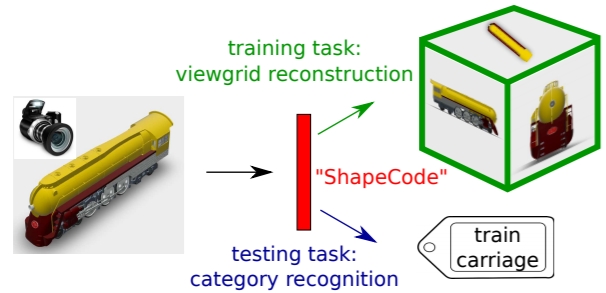
ShapeCodes:
Self-Supervised Feature Learning by Lifting Views to
Viewgrids. D. Jayaraman, R. Gao, and K.
Grauman. In
Proceedings of the European Conference on Computer
Vision (ECCV), Munich, Germany, Sept 2018. [pdf]
[supp]
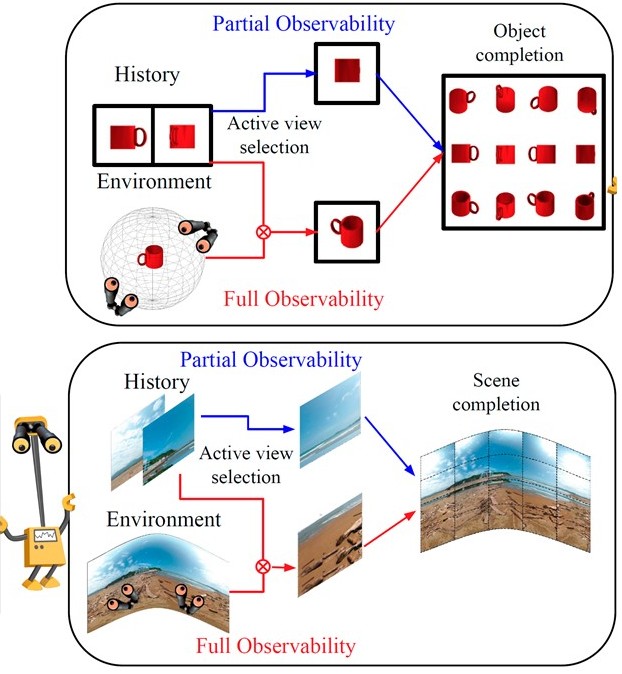
Sidekick
Policy Learning for Active Visual Exploration. S.
Ramakrishnan and K. Grauman. In Proceedings of the
European Conference on Computer Vision (ECCV), Munich,
Germany, Sept 2018. [pdf]
[supp]
[videos/code]
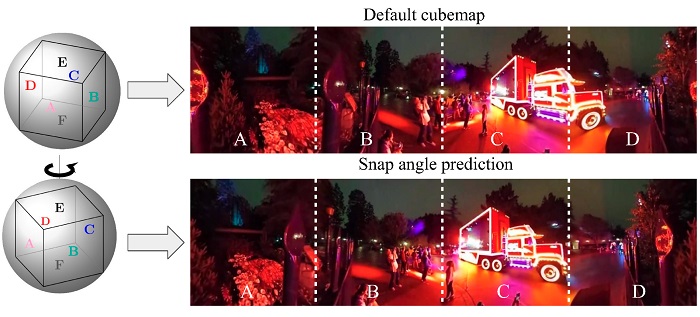
Snap Angle
Prediction for 360 Panoramas. B. Xiong and K.
Grauman. In
Proceedings of the European Conference on Computer Vision
(ECCV), Munich, Germany, Sept 2018. [pdf]
[supp]
[project page]
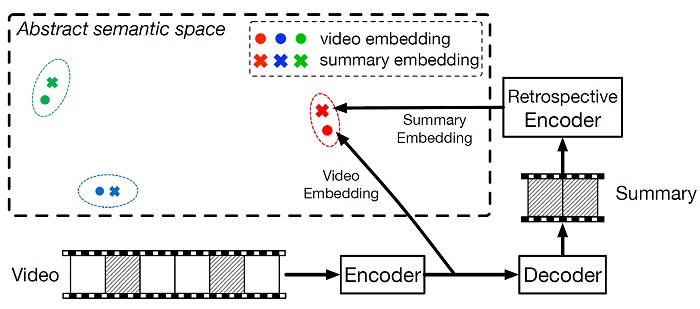
Retrospective
Encoders for Video Summarization. K. Zhang, K.
Grauman, F. Sha. In Proceedings of the European
Conference on Computer Vision (ECCV), Munich, Germany,
Sept 2018. [pdf]
[supp]
BrowseWithMe:
An Online Clothes Shopping Assistant for People with
Visual Impairments. A. Stangl, E. Kothari, S. Jain,
T. Yeh, K. Grauman, D. Gurari. In Proceedings of The
20th International ACM SIGACCESS Conference on Computers
and Accessibility (ASSETS), Galway, Ireland, Oct
2018. [pdf]
[video
demo]
Pixel
Objectness: Learning to Segment Generic Objects
Automatically in Images and Videos. B. Xiong, S.
Jain, and K. Grauman. To appear, Transactions on
Pattern Analysis and Machine Intelligence (PAMI),
2018. [code-imgs]
[code-video]
End-to-end
Policy Learning for Active Visual Categorization. D.
Jayaraman and K. Grauman. Transactions on Pattern
Analysis and Machine Intelligence (PAMI), Volume 41, Issue
7, pp. 1601-1614, July 2018. [pdf]
Visual
Question Answer Diversity. C-J. Yang, K. Grauman,
and D. Gurari. In Proceedings of the Sixth AAAI
Conference on Human Computation and
Crowdsourcing (HCOMP), Zurich, July 2018.
[pdf]
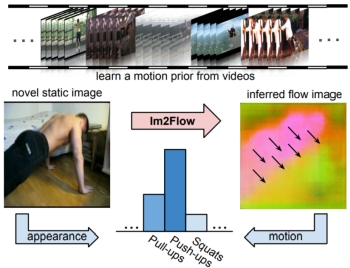
Im2Flow:
Motion Hallucination from Static Images for Action
Recognition. R. Gao, B. Xiong, and K. Grauman.
In Proceedings of IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Salt Lake City, June 2018. (Oral) [pdf]
[code] [project
page]
BlockDrop:
Dynamic Inference Paths in Residual Networks. Z. Wu,
T. Nagarajan, A. Kumar, S. Rennie, L. Davis, K. Grauman,
R. Feris. In Proceedings of IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), Salt Lake
City, June 2018. (Spotlight) [pdf]
[supp]
[code]
VizWiz
Grand Challenge: Answering Visual Questions from Blind
People. D. Gurari, Q. Li, A. Stangl, A. Guo, C. Lin,
K. Grauman, J. Luo, and J. Bigham. In Proceedings of
IEEE Conference on Computer Vision and Pattern Recognition
(CVPR), Salt Lake City, June 2018. (Spotlight)
[pdf]
[supp]
Learning to
Look Around: Intelligently Exploring Unseen Environments
for Unknown Tasks. D. Jayaraman and K.
Grauman. In
Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), Salt Lake City, June
2018. [pdf]
[animations]
Learning
Compressible 360 Video Isomers. Y-C. Su and K.
Grauman. In
Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), Salt Lake City, June
2018. [pdf]
[supp]
[data]
Creating
Capsule Wardrobes from Fashion Images. W-L. Hsiao
and K. Grauman. In
Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), Salt Lake City, June
2018. (Spotlight) [pdf]
[supp]
Compare and
Contrast: Learning Prominent Visual Differences. S.
Chen and K. Grauman. In Proceedings of IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), Salt Lake City,
June 2018. [pdf]
[supp]
[project
page]
Learning
Spherical Convolution for Fast Features from 360°
Imagery. Y-C. Su and K. Grauman. In Advances
in Neural Information Processing (NIPS), Long Beach, CA,
Dec 2017. [pdf]
[supp]
[code]
Predicting
Foreground Object Ambiguity and Efficiently Crowdsourcing
the Segmentation(s). D. Gurari, K. He, B.
Xiong, J. Zhang, M. Sameki, S. Jain, S. Sclaroff, M.
Betke, and K. Grauman. International Journal of
Computer Vision (IJCV), Volume 126, Issue 7, pp
714–730, July 2018. [data]
[pdf]
Next-active-object
prediction from egocentric videos. A. Furnari, S.
Battiato, K. Grauman, and G. Maria Farinella.
Journal of Visual Communication and Image
Representation. Volume 49, pp. 401-411, November
2017. [link]
[project
page]
Semantic
Jitter: Dense Supervision for Visual Comparisons via
Synthetic Images. A. Yu and K. Grauman. In Proceedings of the International Conference
on Computer Vision (ICCV), Venice, Italy, Oct 2017.
[pdf]
[supp]
[poster]
Fashion
Forward: Forecasting Visual Style in Fashion. Z.
Al-Halah, R. Stiefelhagen, and K. Grauman. In Proceedings of the International Conference
on Computer Vision (ICCV), Venice, Italy, Oct 2017.
[pdf]
[supp]
[project
page]
Learning the
Latent "Look": Unsupervised Discovery of a Style-Coherent
Embedding from Fashion Images. W-L. Hsiao and K.
Grauman. In Proceedings
of the International Conference on Computer Vision (ICCV),
Venice, Italy, Oct 2017. [pdf]
[supp]
[project
page/code] [poster]
On-Demand
Learning for Deep Image Restoration. R. Gao and K.
Grauman. In Proceedings of the International
Conference on Computer Vision (ICCV), Venice, Italy, Oct
2017. [pdf]
[supp]
[project
page] [code/data/pretrained
models]
Making 360
Video Watchable in 2D: Learning Videography for Click Free
Viewing. Y-C. Su and K. Grauman. In
Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), Honolulu, July 2017.
(Spotlight) [pdf]
[supp]
[videos]
[spotlight
slides] [poster]
Pano2Vid: Automatic Cinematography for Watching 360
Videos. Y-C. Su, D. Jayaraman, and K. Grauman.
Invited talk, 6th Workshop on Intelligent Cinematography
and Editing, Lyon, France, April 2017. [pdf]
Seeing
Invisible Poses: Estimating 3D Body Pose from Egocentric
Video. H. Jiang and K. Grauman. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Honolulu, July 2017. (Spotlight) [pdf]
[videos]
[poster]
[code/data]
Detangling
People: Individuating Multiple Close People and Their Body
Parts via Region Assembly. H. Jiang and K. Grauman. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition (CVPR),
Honolulu, July 2017. (Oral) [pdf]
[poster]
FusionSeg: Learning to Combine
Motion and Appearance for Fully Automatic Segmentation
of Generic Objects in Video. S. Jain, B. Xiong,
and K. Grauman. Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
Honolulu, July 2017. [pdf]
[supp]
[poster]
[demo]
[project
page/videos/code] [DAVIS
results leaderboard] patent pending
Learning
Image Representations Tied to Egomotion from Unlabeled
Video. D. Jayaraman and K.
Grauman. International Journal of Computer
Vision (IJCV), Special Issue for Best Papers of ICCV
2015, Mar 2017. [pdf]
[preprint]
[project
page, pretrained
models]
CrowdVerge:
Predicting If People Will Agree on the Answer to a Visual
Question. D. Gurari and K. Grauman. ACM Conference
on Human Factors in Computing Systems (CHI), Denver, CO,
May, 2017. Best Paper Honorable Mention
Award [pdf]
[project
page/data]
Pano2Vid:
Automatic Cinematography for Watching 360◦ Videos.
Y-C. Su, D. Jayaraman, and K. Grauman. Proceedings of the Asian Conference
on Computer Vision (ACCV), Taipei, November 2016.
(Oral) [Best Application Paper Award]
[pdf]
[supp]
[project
page/data]
Object-Centric
Representation Learning from Unlabeled Videos. R.
Gao, D. Jayaraman, and K. Grauman. Proceedings of
the Asian Conference on Computer Vision (ACCV), Taipei,
November 2016. [pdf]
[data/models]
[poster]
Pretrained models available.
Crowdsourcing in Computer
Vision. A. Kovashka, O. Russakovsky, L.
Fei-Fei, and K. Grauman. Foundations and
Trends in Computer Graphics and Vision, Vol 10,
Issue 3, Nov 2016. [link]
[arxiv]
[pdf]
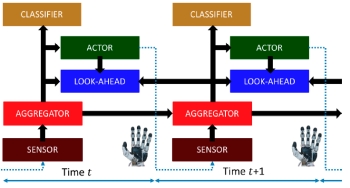
Look-Ahead
Before You Leap: End-to-End Active Recognition by
Forecasting the Effect of Motion. D. Jayaraman and
K. Grauman. Proceedings of the European Conference
on Computer Vision (ECCV), Amsterdam, October
2016. (Oral) [pdf]
[supp]
[slides]
[poster]
[project
page/code]
Leaving Some
Stones Unturned: Dynamic Feature Prioritization for
Activity Detection in Streaming Video. Y-C. Su and
K. Grauman. Proceedings of the European Conference
on Computer Vision (ECCV), Amsterdam, October
2016. [pdf]
[supp]
[videos/project]
[poster]
Detecting
Engagement in Egocentric Video. Y-C. Su and K.
Grauman. Proceedings of the European Conference on
Computer Vision (ECCV), Amsterdam, October 2016.
(Oral)
[pdf]
[supp]
[videos/data]
[poster]
[slides]
Video
Summarization with Long Short-term Memory. K.
Zhang, W-L. Chao, F. Sha, and K. Grauman.
Proceedings of the European Conference on Computer
Vision (ECCV), Amsterdam, October 2016. [pdf]
[supp]
Click
Carving: Segmenting Objects in Video with Point
Clicks. S. D.
Jain and K. Grauman. In Proceedings of the Fourth AAAI Conference
on Human Computation and Crowdsourcing (HCOMP), Austin,
TX, October 2016. [pdf]
[project
page] [code]
Slow and
Steady Feature Analysis: Higher Order Temporal Coherence
in Video. D. Jayaraman and K. Grauman. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Las Vegas, June 2016. (Spotlight) [pdf]
[poster]
[slides]
Summary
Transfer: Exemplar-based Subset Selection for Video
Summarization. K. Zhang, W-L. Chao, F. Sha, and K.
Grauman. In
Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), Las Vegas, June 2016. [pdf]
[supp]
[poster]
[code]
Active Image
Segmentation Propagation. S. Jain and K.
Grauman. In
Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), Las Vegas, June 2016. [pdf]
[poster]
Pull the
Plug? Predicting If Computers or Humans Should
Segment Images. D. Gurari, S. Jain, M. Betke, and K.
Grauman. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), Las Vegas,
June 2016. [pdf]
[supp]
[code/data]
Subjects
and Their Objects: Localizing Interactees for a
Person-Centric View of Importance. C-Y. Chen and
K. Grauman. International Journal of Computer
Vision (IJCV), Oct 2016. [link]
[arxiv
version]
Fine-Grained
Comparisons with Attributes. A. Yu and K.
Grauman. Chapter in Visual
Attributes. R. Feris, C. Lampert, and D. Parikh,
Editors. Springer. To appear, 2017. [preprint]
Divide,
Share, and Conquer: Multi-task Attribute Learning with
Selective Sharing. C-Y. Chen, D. Jayaraman, F. Sha,
and K. Grauman. Chapter in Visual Attributes.
R. Feris, C. Lampert, and D. Parikh, Editors.
Springer. To appear, 2017. [pdf]
Attributes
for Image Retrieval. A. Kovashka and
K. Grauman. Chapter in Visual Attributes.
R. Feris, C. Lampert, and D. Parikh, Editors.
Springer. To appear, 2017.
Efficient
Activity Detection in Untrimmed Video with Max-Subgraph
Search. C-Y. Chen and K. Grauman. IEEE
Trans. on Pattern Analysis and Machine Intelligence
(PAMI), April 2016. [pdf]
Text
Detection in Stores Using a Repetition Prior. B.
Xiong and K. Grauman. In Proceedings of the IEEE
Winter Conference on Computer Vision (WACV). Lake
Placid, NY, March 2016. [pdf]
Learning Image
Representations Tied to Ego-Motion. D. Jayaraman
and K. Grauman. In Proceedings of
the IEEE International Conference on Computer Vision
(ICCV), Santiago, Chile, Dec 2015. (Oral) [pdf]
[supp]
[code,data]
[slides] Pretrained models now available.
Just Noticeable
Differences in Visual Attributes. A. Yu and K.
Grauman. In Proceedings of the IEEE International
Conference on Computer Vision (ICCV), Santiago, Chile,
Dec 2015. [pdf]
[supp]
[poster]
[project
page]
WhittleSearch:
Interactive Image Search with
Relative Attribute Feedback.
A. Kovashka, D. Parikh, and K.
Grauman. International
Journal on Computer Vision (IJCV),
Volume 115, Issue 2, pp 185-210,
November 2015. [link]
[arxiv]
[demo]
Discovering
Attribute Shades of Meaning with the Crowd. A.
Kovashka and K. Grauman.
International Journal on Computer
Vision (IJCV), Volume 114, Issue 1,
pp. 56-73, August 2015. [link]
[arxiv] [data]
Boundary
Preserving Dense Local Regions. J. Kim and K.
Grauman. IEEE Transactions on Pattern Analysis and
Machine Intelligence (PAMI), Volume 37, No 5, pp.
931-943, April 2015. [link] [code]
Predicting
Important Objects for Egocentric Video
Summarization. Y J. Lee and K. Grauman.
International Journal on Computer Vision, Volume 114,
Issue 1, pp. 38-55, August 2015. [link]
[arxiv]
Predicting
Useful Neighborhoods for
Lazy Local Learning.
A. Yu and K. Grauman. In Advances in
Neural Information Processing Systems
(NIPS), Montreal, Canada, Dec 2014. [pdf]
[supp]
[poster]
Large-Margin
Determinantal Point Processes. W-L. Chao, B. Gong,
K. Grauman, and F. Sha. In Proceedings of the Conference
on Uncertainty in Artificial Intelligence (UAI),
Amsterdam, Netherlands, July 2015. [pdf]
[supp]
Zero-shot
Recognition with Unreliable
Attributes.
D. Jayaraman and K. Grauman. In
Advances in Neural Information Processing
Systems (NIPS), Montreal, Canada, Dec
2014. [pdf]
[supp]
[poster]
[code]
[project]
Diverse
Sequential Subset Selection
for Supervised Video
Summarization.
B. Gong, W. Chao, K. Grauman, and F.
Sha. In Advances in
Neural Information Processing Systems
(NIPS), Montreal, Canada, Dec 2014. [pdf]
[supp]
[poster]
Predicting
the Location
of
"Interactees"
in Novel
Human-Object
Interactions.
C-Y. Chen and K. Grauman. In
Proceedings of the Asian Conference on
Computer Vision (ACCV), Singapore, Nov
2014. [pdf]
[project
page] [data]
Which
Image Pairs
Will Cosegment
Well?
Predicting
Partners for
Cosegmentation.
S. Jain and K. Grauman. In Proceedings
of the Asian Conference on Computer Vision
(ACCV), Singapore, Nov 2014. [pdf]
Detecting
Snap Points in Egocentric Video with a Web
Photo Prior. B. Xiong and K.
Grauman. In Proceedings of the
European Conference on Computer Vision
(ECCV), Zurich, Switzerland, Sept
2014. [pdf]
[project
page] [data]
[code]
Intentional Photos from an
Unintentional Photographer: Detecting Snap Points in
Egocentric Video with a Web Photo Prior. B. Xiong
and K. Grauman. Invited chapter. In Mobile
Cloud Visual Media Computing. Springer
International Publishing. Editors: G. Hua and
X.-S. Hua. pp 85-111. November 2015. [pdf]
Supervoxel-Consistent
Foreground Propagation in Video. S.
Jain and K. Grauman. In
Proceedings of the European
Conference on Computer
Vision (ECCV), Zurich,
Switzerland, Sept
2014. [pdf]
[project
page] [data]
Discovering Shades
of Attribute Meaning with the Crowd. A. Kovashka
and K. Grauman. Third International Workshop on
Parts and Attributes, in conjunction with the European
Conference on Computer Vision. Zurich,
Switzerland, Sept 2014. [pdf]
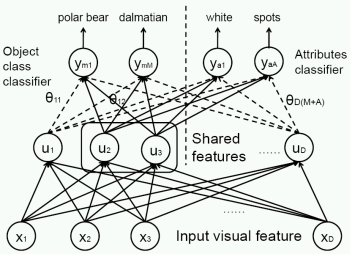
Decorrelating
Semantic Visual Attributes by Resisting the
Urge to Share. D. Jayaraman, F. Sha,
and K. Grauman. In
Proceedings of
the IEEE
Conference on
Computer
Vision and
Pattern
Recognition
(CVPR),
Columbus,
Ohio, June
2014.
(Oral) [pdf]
[supp]
[project
page]
[slides]
[poster]
[code]
Fine-Grained
Visual Comparisons with Local
Learning. A. Yu and K. Grauman.
In
Proceedings of the IEEE
Conference on Computer
Vision and Pattern
Recognition (CVPR),
Columbus, Ohio, June
2014. [pdf]
[supp]
[poster]
[data]
[code]
[project
page]
Beyond
Comparing Image Pairs: Setwise Active
Learning for Relative Attributes. L.
Liang and K. Grauman. In
Proceedings of
the IEEE
Conference on
Computer
Vision and
Pattern
Recognition
(CVPR),
Columbus,
Ohio, June
2014. [pdf]
[supp]
[project
page]
[code
for data
collection]
[code
for algorithm]
[poster]
Beyond
Comparing
Image Pairs:
Setwise Active
Learning for
Relative
Attributes.
L. Liang and
K.
Grauman.
Workshop on Computer Vision and Human
Computation (CVHC), CVPR 2014. [abstract]
Inferring
Unseen Views of People. C.-Y. Chen and
K. Grauman. In Proceedings of the IEEE
Conference on Computer Vision and Pattern
Recognition (CVPR), Columbus, Ohio, June
2014.
[pdf]
[supp]
[project
page]
[poster]
Inferring
Analogous Attributes.
C.-Y. Chen and K.
Grauman. In
Proceedings of the IEEE
Conference on Computer
Vision and Pattern
Recognition (CVPR),
Columbus, Ohio, June
2014. [pdf]
[supp]
[project
page] [poster]
Inferring Analogous
Attributes: Large-Scale
Transfer of
Category-Specific Attribute
Classifiers. C.-Y.
Chen and K. Grauman.
International Workshop on
Large Scale Visual
Recognition and Retrieval
(BigVision) at CVPR 2014. [abstract]
Learning
Kernels for Unsupervised Domain
Adaptation with Applications to
Visual Object Recognition.
B. Gong, K. Grauman, and F.
Sha. International Journal
of Computer Vision (IJCV),
Volume 109, Issue 1-2, pp. 3-27,
August 2014. [link]
Attribute Pivots
for Guiding Relevance Feedback in Image Search. A.
Kovashka and K. Grauman. In
Proceedings of the IEEE International Conference on
Computer Vision (ICCV), Sydney, Australia, December
2013. [pdf]
[poster]
[project
page] [patented]
Interactive Image Search with Attribute-based Guidance
and Personalization. A. Kovashka and K.
Grauman. Workshop
on Computer Vision and Human Computation (CVHC), CVPR
2014. [abstract]
Predicting
Sufficient Annotation Strength for Interactive
Foreground Segmentation. S. Jain and K.
Grauman. In Proceedings of the IEEE International
Conference on Computer Vision (ICCV), Sydney, Australia,
December 2013. [pdf]
[poster]
[project
page] [data]
Predicting Sufficient Annotation Strength for
Interactive Foreground Segmentation. S. Jain and
K. Grauman. Workshop on Computer Vision and Human
Computation (CVHC), CVPR 2014. [abstract]
Attribute
Adaptation for Personalized Image Search. A.
Kovashka and K. Grauman. In Proceedings of the
IEEE International Conference on Computer Vision (ICCV),
Sydney, Australia, December 2013. [pdf]
[poster]
[project
page]
Active Learning
of an Action Detector from Untrimmed Videos. S.
Bandla and K. Grauman. In
Proceedings of the IEEE International Conference on
Computer Vision (ICCV), Sydney, Australia, December
2013. [pdf]
[project
page] [annotation
code] [poster]
[annotations]
Implied
Feedback: Learning Nuances of User Behavior in Image
Search. D. Parikh and K. Grauman. In
Proceedings of the IEEE International Conference on
Computer Vision (ICCV), Sydney, Australia, December
2013. [pdf]
[supp]
Reshaping Visual
Datasets for Domain Adaptation. B. Gong, K.
Grauman, and F. Sha. In Proceedings of Advances in
Neural Information Processing Systems (NIPS), Tahoe,
Nevada, December 2013. [pdf]
Watching
Unlabeled Video Helps Learn New Human Actions from Very
Few Labeled Snapshots. C-Y. Chen and K.
Grauman. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
Portland, OR, June 2013. (Oral) [pdf]
[project
page]
Story-Driven
Summarization for Egocentric Video. Z. Lu and K.
Grauman. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
Portland, OR, June 2013. [pdf]
[project
page] [data]
[poster]
Deformable
Spatial Pyramid Matching for Fast Dense
Correspondences. J. Kim, C. Liu, F. Sha, and K.
Grauman. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
Portland, OR, June 2013.[pdf]
[project
page] [code]
Object-Centric
Spatio-Temporal Pyramids for Egocentric Activity
Recognition. T. McCandless and K. Grauman.
In Proceedings of the British Machine Vision Conference
(BMVC), Bristol, UK, Sept 2013. [pdf]
[abstract]
[poster]
Analogy-Preserving Semantic Embedding for
Visual Object Categorization. S. J. Hwang, K.
Grauman, and F. Sha. In International Conference
on Machine Learning (ICML), Atlanta, GA, June
2013. [pdf]
Connecting the Dots with Landmarks:
Discriminatively Learning Domain-Invariant Features
for Unsupervised Domain Adaptation.
B. Gong, K.
Grauman, and F.
Sha. In International
Conference on Machine Learning (ICML), Atlanta,
GA, June 2013. (Oral) [pdf]
[supp]
Shape Sharing
for Object Segmentation. J. Kim and K.
Grauman. To appear, Proceedings of the European
Conference on Computer Vision (ECCV), Florence, Italy,
October 2012. (Oral) [pdf]
[supp]
[project
page] [code]
[slides]
Active Frame
Selection for Label Propagation in Videos. S.
Vijayanarasimhan and K. Grauman. To appear,
Proceedings of the European Conference on Computer
Vision (ECCV), Florence, Italy, October 2012. [pdf]
[poster]
[project
page] [code]
[data]
Semantic Kernel
Forests from Multiple Taxonomies. S. J. Hwang, K.
Grauman, and F. Sha. In Advances in Neural
Information Processing Systems (NIPS), Tahoe, Nevada,
December 2012. [pdf]
[poster]
[project
page] [code]
Semantic Kernel Forests from
Multiple Taxonomies. S. J. Hwang, F. Sha,
and K. Grauman. In Big Data Meets Computer
Vision: First International Workshop on
Large Scale Visual Recognition and
Retrieval. In conjunction with NIPS, 2012.
(Oral) [pdf]
[code]
Discovering Important People
and Objects for Egocentric Video Summarization. Y.
J. Lee, J. Ghosh, and K. Grauman. In Proceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Providence, RI, June 2012. [pdf][poster]
[data]
[project
page]
Efficient Activity Detection
with Max-Subgraph Search. C.-Y. Chen and K.
Grauman. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Providence, RI, June 2012. [pdf]
[poster]
[project
page] [code]
WhittleSearch: Image Search
with Relative Attribute Feedback. A. Kovashka, D. Parikh, and
K. Grauman. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Providence, RI, June 2012. [pdf] [supp][poster]
[project
page] [demo]
[patented]
Discovering Localized
Attributes for Fine-grained Recognition. K. Duan,
D. Parikh, D. Crandall, and K. Grauman. In
Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), Providence, RI, June
2012. [pdf] [poster][project
page]
Geodesic Flow Kernel for
Unsupervised Domain Adaptation. B. Gong, Y. Shi,
F. Sha, and K. Grauman. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Providence, RI, June 2012. (Oral) [pdf]
[supp] [slides]
[project
page]
Overcoming Dataset Bias: An
Unsupervised Domain Adaptation Approach. B. Gong,
F. Sha, and K. Grauman. In Big Data Meets Computer
Vision: First International Workshop on Large Scale
Visual Recognition and Retrieval. In conjunction
with NIPS, 2012. (Oral) [pdf] [project
page]
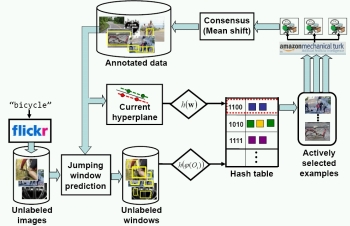
Learning Binary Hash Codes for Large-Scale Image
Search. K. Grauman and R.
Fergus. Book chapter, in Machine
Learning for Computer Vision, Ed., R. Cipolla, S.
Battiato, and G. Farinella, Studies in Computational
Intelligence Series, Springer, Volume 411, pp. 49-87, 2013
[pdf] [link]
Reconstructing a
Fragmented Face from a Cryptographic Identification
Protocol. A. Luong, M. Gerbush, B. Waters, and K.
Grauman. In Proceedings of the IEEE Workshop on
Applications of Computer Vision (WACV), Clearwater
Beach, FL, January 2013. [pdf] [poster]
Relative Attributes. D. Parikh and K.
Grauman. In Proceedings
of the International Conference on Computer Vision
(ICCV), Barcelona, Spain, November 2011.
(Oral) [pdf]
[project page] [data] [slides] [Marr
Prize, ICCV Best Paper Award]
Relative Attributes for
Enhanced Human-Machine Communication. D. Parikh,
A. Kovashka, A. Parkash, and K. Grauman. Invited
paper, Proceedings of AAAI 2012, Sub-Area Spotlights
Track for Best Papers. [pdf]
Key-Segments for Video
Object Segmentation. Y. J. Lee, J. Kim, and K.
Grauman. In Proceedings of the International Conference
on Computer Vision (ICCV), Barcelona, Spain,
November 2011. [pdf]
[poster]
[project
page] [video
results] [code]
Annotator Rationales for
Visual Recognition. J. Donahue and K.
Grauman. In Proceedings of the International Conference
on Computer Vision (ICCV), Barcelona, Spain,
November 2011. [pdf]
[project
page] [data] [video
overview]
Actively Selecting
Annotations Among Objects and Attributes. A. Kovashka, S.
Vijayanarasimhan, and K. Grauman. InProceedings of the International Conference
on Computer Vision (ICCV), Barcelona, Spain,
November 2011. [pdf]
[project
page]
Learning a Tree of Metrics with Disjoint Visual
Features. S. J. Hwang, K. Grauman, F. Sha. To appear, Advances in Neural
Information Processing Systems (NIPS).
Granada, Spain, December 2011. [pdf] [poster]
[project
page] [code]
Visual Object Recognition,
Kristen Grauman and Bastian Leibe,
Synthesis Lectures on Artificial Intelligence and
Machine Learning, April 2011, Vol. 5,
No. 2, Pages 1-181.
[link]
Face Discovery with Social
Context. Y. J. Lee and K. Grauman. In Proceedings of the British
Machine Vision Conference (BMVC), Dundee, U.K.,
August 2011. [pdf]
[abstract]
[project
page]
Large-Scale
Live
Active
Learning:
Training
Object
Detectors
with
Crawled
Data
and
Crowds.
S.
Vijayanarasimhan
and
K.
Grauman.
In
Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Colorado Springs, CO, June 2011. (Oral) [pdf]
[project
page] [slides]
We show some additional analysis of the annotation
collection, to be presented at the Human Computation Workshop(HCOMP), at AAAI 2011. [pdf]
Large-Scale
Live Active Learning: Training Object
Detectors with Crawled Data and
Crowds. S. Vijayanarasimhan and K.
Grauman. International Journal of
Computer Vision (IJCV), Volume 108, Issue
1-2, pp. 97-114, May 2014. [link]
Boundary-Preserving Dense Local Regions. J.
Kim and K. Grauman. In Proceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Colorado Springs, CO, June
2011. (Oral) [pdf]
[project
page] [code]
[slides]
Interactively Building a Discriminative Vocabulary of
Nameable Attributes. D. Parikh and K. Grauman. In Proceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Colorado Springs, CO, June
2011. [pdf]
[project
page] [poster]
We show some additional results in our short abstract to
be presented at the Fine-Grained
Visual Categorization Workshop (FGVC) at CVPR
2011. [Best Poster
Award] [pdf]
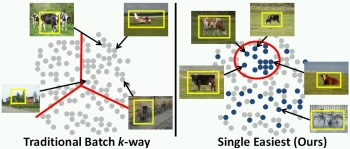
Learning the Easy Things First: Self-Paced Visual
Category Discovery. Y. J. Lee and K. Grauman.
In Proceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Colorado Springs, CO, June
2011. [pdf]
[project
page] [poster]
Sharing Features Between Objects and Their
Attributes. S. J. Hwang, F. Sha, and K.
Grauman. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), Colorado Springs, CO, June 2011. [pdf]
[project
page] [poster]
We show some additional results in our
short abstract to appear in Fine-Grained Visual Categorization Workshop
(FGVC) at CVPR 2011. [pdf][poster]
Learning with Whom to Share
in Multi-task Feature Learning. Z. Kang, K.
Grauman, and F. Sha. In Proceedings of the International Conference
on Machine Learning (ICML), Bellevue, WA, July
2011. [pdf]
[supp][code]
Efficient Region
Search for Object Detection. S. Vijayanarasimhan
and K. Grauman. In Proceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Colorado Springs, CO, June
2011. [pdf]
[project
page] [code]
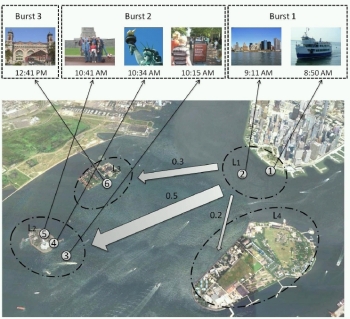
Clues from the Beaten Path: Location Estimation
with Bursty Sequences of Tourist Photos. C.-Y. Chen
and K. Grauman. In Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), Colorado
Springs, CO, June 2011. [pdf]
[project
page] [data]
[poster]
Clues from the Beaten Path: Location
Estimation with Bursty Sequences of Tourist Photos.
C.-Y. Chen. Master's thesis, December 2010. [pdf]
Hashing Hyperplane Queries
to Near Points with Applications to Large-Scale Active
Learning. P. Jain, S. Vijayanarasimhan, and K.
Grauman. In Advances
in Neural Information Processing Systems
(NIPS), Vancouver, Canada, December 2010. [pdf]
[supp] [project
page][poster]
Hashing
Hyperplane Queries to Near Points with
Applications to Large-Scale Active
Learning. S. Vijayanarasimhan, P.
Jain, and K. Grauman. Transactions on
Pattern Analysis and Machine Intelligence
(PAMI), Volume 36, No. 2, pp. 276-288,
February 2014. [link]
Object-Graphs
for Context-Aware Category Discovery.Y. J. Lee and K. Grauman.In
Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
San Francisco, CA, June 2010. (Oral) [pdf]
[project
page] [slides]
[code]
Object-Graphs
for Context-Aware Category Discovery.Y. J. Lee and K. Grauman.In IEEE Transactions
on Pattern Analysis and Machine Intelligence (TPAMI), Vol. 34, No. 2, pp. 346-358,
February 2012. [link]
Reading Between
The Lines: Object Localization Using Implicit Cues from
Image Tags.S. J. Hwang and
K. Grauman. InProceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), San Francisco, CA, June 2010.
(Oral) [pdf]
[project
page] [slides]
[data]
Reading Between
The Lines: Object Localization Using Implicit Cues from
Image Tags.S. J. Hwang and
K. Grauman.IEEE Transactions on Pattern Analysis and
Machine Intelligence(TPAMI), Vol. 34, No. 6, pp. 1145-1158,
June 2012. [link]
Accounting for the Relative
Importance of Objects
in Image Retrieval. S. J. Hwang and K.
Grauman. In
Proceedings of theBritish Machine Vision Conference (BMVC),
Aberystwyth, UK, September 2010. (Oral) [pdf] [slides][project
page] [data]
Learning the Relative Importance of Objects
from Tagged Images for Retrieval and Cross-Modal
Search. S. J. Hwang and K. Grauman.
International Journal of Computer Vision (IJCV), Vol.
100, Issue 2, pp. 134-153, November 2012. [link]
Far-Sighted
Active Learning on a Budget for Image and Video
Recognition.S.
Vijayanarasimhan, P. Jain, and K. Grauman.In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), San Francisco, CA, June 2010. [pdf]
[project
page] [code]
Cost-Sensitive
Active
Visual
Category
Learning.
S.
Vijayanarasimhan
and
K.
Grauman.
International Journal of
Computer Vision (IJCV), Vol. 91,
Issue 1 (2011), p. 24, (online first July
2010). [link]
Minimizing Annotation Costs in
Visual Category Learning. S. Vijayanarasimhan and
K. Grauman. Invited chapter, in Cost-Sensitive
Machine Learning, B. Krishnapuram, S. Yu, and B.
Rao, Editors. Chapman and Hall/CRC, December
2011. [link]
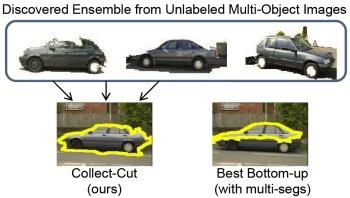
Collect-Cut:
Segmentation with Top-Down Cues Discovered in
Multi-Object Images.Y. J.
Lee and K. Grauman.In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
San Francisco, CA, June 2010. [pdf]
[project
page] [poster]
Learning a
Hierarchy of Discriminative Space-Time Neighborhood
Features for Human Action Recognition.A. Kovashka and K. Grauman.In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), San Francisco, CA, June 2010. [pdf]
[project
page] [poster]
Asymmetric
Region-to-Image Matching for Comparing Images with
Generic Object Categories.J.
Kim and K. Grauman.In
Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
San Francisco, CA, June 2010. [pdf]
[project
page] [code]
Top-Down Pairwise Potentials
for Piecing Together Multi-Class Segmentation
Puzzles. S. Vijayanarasimhan and K.Grauman.
In Proceedings of the Seventh IEEE Computer Society
Workshop on Perceptual Organization in Computer Vision (POCV), June 2010. [pdf] [slides]
Kernelized
Locality-Sensitive Hashing for Scalable Image Search.B. Kulis and K. Grauman.In Proceedings of the IEEE
International Conference on Computer Vision (ICCV), Kyoto, Japan, October 2009.[pdf]
[poster]
[code]
[project
page]
Kernelized
Locality-Sensitive Hashing. B. Kulis and K.
Grauman. IEEE Transactions on Pattern Analysis
and Machine Intelligence (TPAMI), Vol. 34, No. 6, pp.
1092-1104, June
2012. [link]
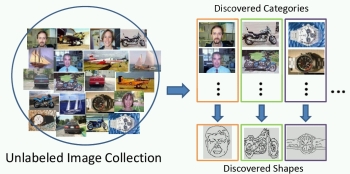
Shape Discovery
from Unlabeled Image Collections.Y.
J. Lee and K. Grauman.In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
Miami, FL, June 2009.[pdf]
[project
page] [poster]
Multi-Level
Active Prediction of Useful Image Annotations
for Recognition.S. Vijayanarasimhan and K. Grauman.In Advances in Neural Information
Processing Systems (NIPS), Vancouver, Canada, Dec.
2008. (Oral) [pdf][slides]
[project
page]
Cost-Sensitive
Active Visual Category Learning.S.
Vijayanarasimhan and K. Grauman.Abstract
presented
at the Learning Workshop, Clearwater FL, April 2009.[abstract]
[slides]
What’s It Going
to Cost You? : Predicting Effort vs. Informativeness for
Multi-Label Image Annotations.S.
Vijayanarasimhan
and K. Grauman.In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
Miami, FL, June 2009.[pdf]
[project
page]
Efficiently
Searching for Similar Images.K.
Grauman.Invited article to
appear in the Communications of the ACM,
2009.[pre-print]
[CACM
link]
Online Metric
Learning and Fast Similarity Search.P. Jain, B. Kulis, I.
Dhillon, and K. Grauman.In
Advances in Neural Information Processing
Systems (NIPS), Vancouver, Canada, Dec. 2008. (Oral) [pdf]
[extended
version]
Fast Image
Search for Learned Metrics.P.
Jain, B. Kulis, and K. Grauman.In
Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), Anchorage, Alaska, June 2008.(Oral) [Best Student Paper Award][pdf][slides
(ppt)] [project
page]
Fast Similarity Search for Learned Metrics.B. Kulis, P. Jain, and
K. Grauman.In IEEE
Transactions on Pattern Analysis and Machine
Intelligence (TPAMI), Vol.
31, No. 12, December 2009.[link]
[project
page]
Observe Locally,
Infer Globally: a Space-Time MRF for Detecting Abnormal
Activities with Incremental Updates.J. Kim and K. Grauman.In
Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
Miami, FL, June 2009.[pdf]
[project
page] [loopy
BP code]
Foreground
Focus: Unsupervised Learning from Partially
Matching Images.Y. J.
Lee and K. Grauman.In International Journal of Computer Vision
(IJCV), Vol. 85, No. 2, 2009.[link]
[project
page]
Foreground
Focus: Finding Meaningful Features in Unlabeled Images.
Y. J. Lee and K. Grauman.In
Proceedings of the British Machine Vision Conference
(BMVC), Leeds,
U.K.,
September 2008. (Oral) [pdf]
[slides
(ppt)] [project
page]
Keywords to
Visual Categories: Multiple-Instance Learning for Weakly
Supervised Object Categorization.S.
Vijayanarasimhan and K. Grauman.In
Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), Anchorage, Alaska, June 2008.[pdf][poster
(pdf)][poster
(ppt)][Semantic
Robot Vision Challenge slides (ppt)] [project
page] [code]
Watch, Listen
& Learn: Co-training on Captioned Images and Videos.S. Gupta, J. Kim, K. Grauman,
and R. Mooney.In Proceedings
of the European Conference on Machine Learning and
Principles and Practice of Knowledge Discovery in
Databases (ECML), Antwerp, Belgium,
September 2008.[pdf]
[project
page]
Active Learning
with Gaussian Processes for Object Categorization.A. Kapoor, K. Grauman, R.
Urtasun, and T. Darrell.In
Proceedings of the IEEE International
Conference on Computer Vision, Rio de Janeiro,
Brazil, October 2007.[pdf]
Gaussian
Processes for Object Categorization.A. Kapoor, K. Grauman, R. Uratsun, and T.
Darrell.In International
Journal of Computer Vision (IJCV), Vol. 88, No.
2, 2010. [link]
The Pyramid Match Kernel:
Discriminative Classification with Sets of Image
Features.K. Grauman and T.
Darrell. In Proceedings of the IEEE
International Conference on Computer Vision (ICCV), Beijing, China,
October 2005. (Oral) [pdf]
[ppt
slides][code] [project
page]
The Pyramid Match: Efficient Learning with Partial
Correspondences.K.
Grauman.In Proceedings of the Association for the
Advancement of Artificial Intelligence (AAAI),(Nectar
track, for AI results presented at other conferences
in last two years)Vancouver,
Canada,
July 2007.[pdf]
The Pyramid Match Kernel: Efficient Learning with Sets
of Features.K. Grauman and
T. Darrell.Journal of
Machine Learning Research (JMLR), 8 (Apr): 725--760,
2007.[pdf][code][project
page]
Matching Sets of Features for Efficient Retrieval and
Recognition, K. Grauman, Ph.D. Thesis,
MIT, 2006.[pdf]
(35.8 MB)
Pyramid Match
Hashing: Sub-Linear Time Indexing Over Partial
Correspondences.K. Grauman
and T. Darrell.In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), Minneapolis,
MN, June
2007.[pdf]
Approximate
Correspondences in High Dimensions.K.
Grauman and T. Darrell.In Advances inNeural
Information Processing Systems 19 (NIPS) 2007.[pdf][code][poster
(pdf)][poster
(ppt)]
Unsupervised
Learning of Categories from Sets of Partially Matching
Image Features.K. Grauman
and T. Darrell.In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), New York City,
NY, June
2006. (Oral) [pdf][ppt
slides]
Efficient Image Matching with
Distributions of Local Invariant Features.K. Grauman and T. Darrell. In
Proceedings IEEE Conference on Computer Vision and
Pattern Recognition (CVPR),
San Diego,
CA, June
2005.[pdf]
Fast Contour
Matching Using Approximate Earth Mover's Distance.
K. Grauman and T. Darrell.In
Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition (CVPR),
WashingtonDC, June
2004. [pdf] [project
page]
[code]
A Picture is Worth a Thousand
Keywords: Image-Based Object Search on a Mobile
Platform. T. Yeh, K. Grauman, K. Tollmar, and T.
Darrell. In CHI 2005, Conference on
Human Factors in Computing Systems, Portland, OR, April
2005. [pdf]
Inferring 3D Structure with a
Statistical Image-Based Shape Model. K. Grauman,
G. Shakhnarovich, and T. Darrell. In Proceedings
of the IEEE International Conference on Computer
Vision (ICCV), Nice, France,
October 2003. [pdf]
[project
page]
Avoiding the
``Streetlight Effect'': Tracking by Exploring Likelihood
Modes.D. Demirdjian, L.
Taycher, G. Shakhnarovich, K. Grauman, and T. Darrell.In Proceedings of the IEEE
International Conference on Computer Vision (ICCV), Beijing, China,
October 2005. [pdf]
A Bayesian Approach to Image-Based
Visual Hull Reconstruction.K.
Grauman, G. Shakhnarovich, and T. Darrell.In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), Madison, WI,
June 2003. [pdf]
[project
page]
Virtual Visual
Hulls: Example-Based 3D Shape Inference from a Single
Silhouette. K. Grauman, G. Shakhnarovich, and T.
Darrell.In Proceedings
of the 2nd Workshop on Statistical Methods in Video
Processing, in conjunction with ECCV,Prague,
Czech Republic, May 2004. [pdf]
[project
page]
Communication via Eye Blinks and
Eyebrow Raises: Video-Based Human-Computer Interfaces.
K. Grauman, M. Betke, J. Lombardi, J. Gips, and G.
Bradski. Universal Access in the Information
Society, 2(4) pp. 359-373, Springer-Verlag Heidelberg,
November 2003. [link]
[project
page]
Communication
via Eye Blinks: Detection and Duration Analysis in Real
Time.K. Grauman, M. Betke,
J. Gips, and G. Bradski. In Proceedings of the
IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Lihue, HI, December 2001.
[pdf]
[project
page]